


Scalability, availability and high availability—these are the advantages that make public clouds a must have in modern software development. But they can cost you dearly if you don’t manage your cost spending carefully. In the second part of our three-part series on cloud cost optimization, we will show you how to get the GCP bill under control and avoid unexpected cloud costs.
Following up on our initial blog about AWS, we’ll now turn to building a cost management solution for the second public cloud: Google Cloud Platform (GCP). Our ultimate goal is to prevent unwanted cloud spend while developing cloud-native software architecture. To make sure we are on the same page, let’s review the requirements such a solution should meet:
- Work automatically
- Be easy to implement
- Be inexpensive to develop
- Enable the client to switch off or decrease the use of resources but not delete them
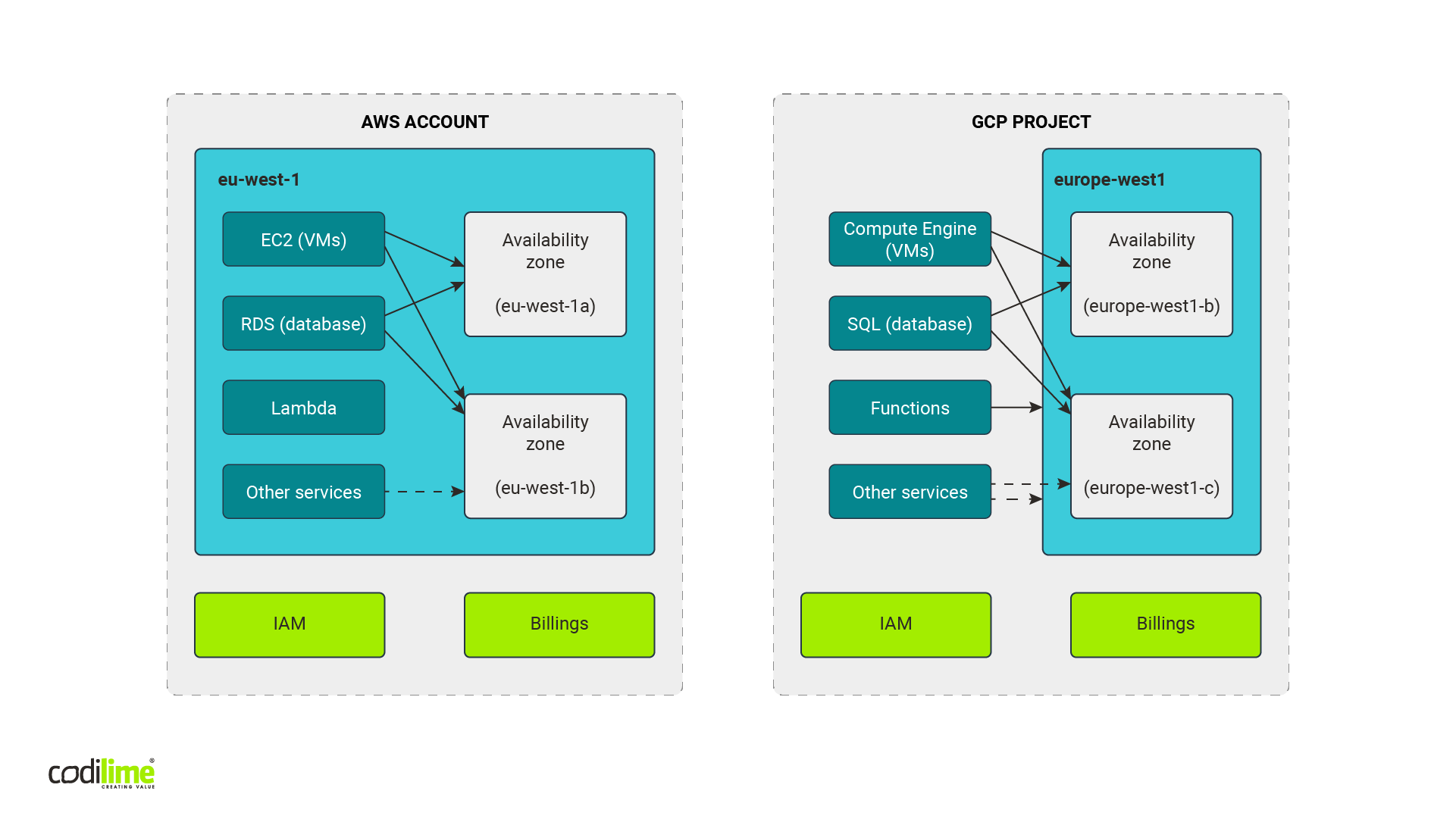
AWS infrastructure vs GCP infrastructure
While we’re not going to compare GCP with AWS in this post, a quick look at the most important differences will benefit those who’ve never had the chance to work with these public cloud providers.
We’ll start with a quick chronological overview. Amazon started building its cloud solutions at the beginning of the 2000s ![]() . Released to the public in November 2004, Simple Queue Service (SQS) was the first publicly available AWS service, allowing users to queue and exchange messages across applications. S3 (Simple Storage Service) appeared on the market in March 2006. The one of the most important services, EC2 (Elastic Cloud Computing) that allows you to run virtual machines, went live in August 2006.
. Released to the public in November 2004, Simple Queue Service (SQS) was the first publicly available AWS service, allowing users to queue and exchange messages across applications. S3 (Simple Storage Service) appeared on the market in March 2006. The one of the most important services, EC2 (Elastic Cloud Computing) that allows you to run virtual machines, went live in August 2006.
The first GCP service available to the public was App Service, which allowed users to build and host their web applications in the Google infrastructure. This service went live in April 2008. Cloud Storage, a counterpart of AWS S3, was released in May 2010. Compute Engine, a counterpart of AWS EC2 service, was launched in May 2013 after a one-year preview period.
As you can see, AWS has been on the market longer than GCP. This may be why AWS seems to be a more mature and better documented platform than Google. It also gives the impression that GCP’s overall construction and the names of several components are similar to AWS Cloud. Both public clouds are based on services composed spanning a dozen functionalities. The service categories are similar and similar services can be found both in GCP and AWS.
The main infrastructure element in the AWS cloud is “an account”. But don’t let its common moniker fool you—it is more a container for resources than a user account we know from social media or emails. In GCP, its counterpart is called “a project”. Both public clouds have a parent structure called “an organisation,” which is optional in AWS. This structure is used to manage and group accounts or projects according to the requirements of a given organization. When working on the cost optimization solution, GCP account/AWS project level is what interests us most, as these are the smallest units that have separated groups of resources with their own budgets.
For most services in both clouds, you need to choose the region where a given resource will be created. A region is a geographical area which allows you to decide where your data are actually stored. This is especially important to stay compliant with GDPR or other regulations and ensure your infrastructure is protected against global failures. Additionally, regions are divided into availability zones—separated physical locations of data centers ensuring that the resources in regions are physically separated and allowing users to use high availability solutions. In this way, a potential failure in one data center will not affect the overall availability of the resources for the entire region.
Both GCP and AWS have twenty-something regions with three or more availability zones for each of them. Of course, that their names are similar doesn’t mean their implementation is also identical. Quite the contrary, they differ a lot when it comes to the details. We are going to concentrate here only on those details that are most important for our cost optimization solution.
Here, you can check our environment services.
Working with GCP vs working with AWS
AWS presupposes a strict separation of regions from each other, so the work done with this provider will be region-oriented. In the AWS web console you need to choose a region you intend to work with. You will also see only resources that were created in a chosen region. New resources are created in a chosen region by default. The situation is the same for CLI and API tools—you need to choose a region you will be working with. Some AWS services are independent from the regions, for example Billing Service. There are also resources that are tightly connected to availability zones.
GCP works in a slightly different manner. Web console displays all resources by default regardless of the region in which they were created. Only when creating a resource do you need to choose a region and/or—depending on the resource type—a zone. In GCP, a resource can be global, regional or zonal. When using CLI and API, you need to choose a region or a zone for resources of a particular type.
GCP native mechanisms for cost control
As in the case of AWS, we decided to look into native mechanisms GCP users could employ to control costs. We discovered that they are similar to what AWS offers. You can define budget and alert thresholds, which when exceeded will prompt the service to notify you by email. Additionally, you can send a message to the Pub/Sub service, which is a counterpart of SNS service in AWS. However, in GCP you cannot take any action related to resources, which is possible in AWS.
When we dig deeper in the official GCP documentation, we found a description of a solution similar to what we created for AWS: budget -> a notification to message service -> programming function. Instead of turning off some services, documentation suggests you take one of two types of action: sending a Slack notification or turning off the budget. We opted to check the latter, which was promising at first glance. Instead of switching off particular resources, you switch off the entire budget, thus stopping all services. A fast, effective and comfortable solution, you might think. But hold your horses: was this really what we needed? In the documentation, there is one interesting passage:
Warning:
This example removes Cloud Billing from your project, shutting down all resources. Resources might not shut down gracefully, and might be irretrievably deleted. There is no graceful recovery if you disable Cloud Billing. You can re-enable Cloud Billing, but there is no guarantee of service recovery and manual configuration is required.
So, it became immediately clear that we needed to choose the same path we’d taken with our AWS cost optimization solution: budget -> a notification to a message service -> programming function + API library -> stopping particular resources.
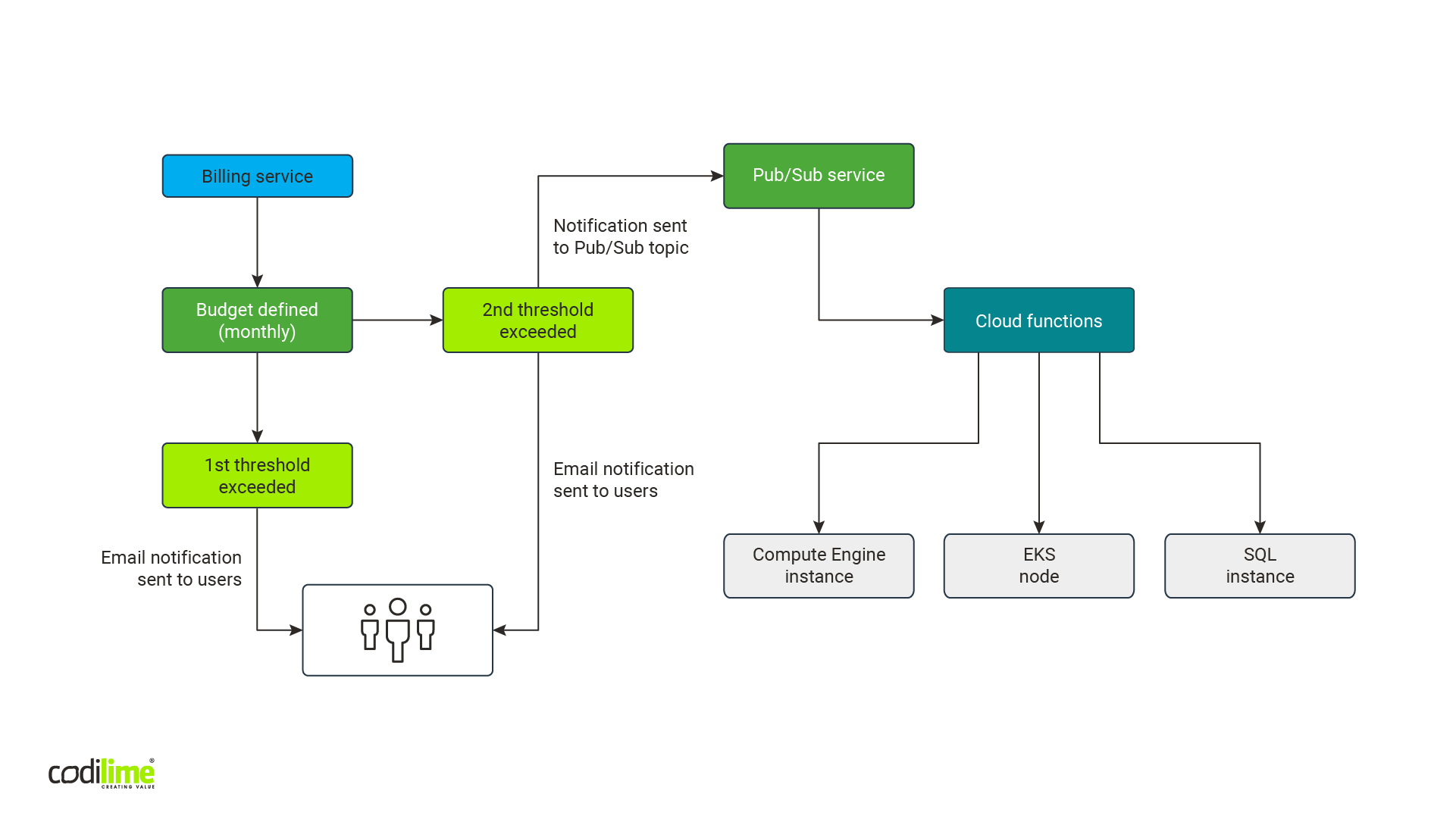
Pub/Sub service + Cloud functions
A notification service Pub/Sub calls a programming function in the very similar way as it is done in AWS. You need to define an entrypoint—a specific function name called in a code that can contain many functions. A notification is sent to the function defined as an entrypoint. This means that in the function definition the fact that it will obtain a notification while being called needs to be taken into account. This notification is sent in the form of two arguments.
def pubsub_entrypoint(event, context):
When it comes to differences, Pub/Sub is a global service. As such, neither a zone nor a region need to be defined when it is created. It is based on internal distributed Google infrastructure and, among others, has a load balancing mechanism to ensure that both message publishers and message consumers get the message without delay. On the other hand, in the AWS SNS, you’ll need to define the region where a service is created, but it has global availability. After receiving access rights, services from other regions can become publishers and consumers.
A function in the Cloud Functions service requires the region in which it is created to be defined. But because of how Google Cloud works, a copy for each region doesn’t need to be created. It is enough to have one function with the access to the API of the services you need to switch off.
Python + googleapiclient library
So, we got the working workflow: budget -> Pub/Sub topic -> Cloud functions. What we lacked was a Python library supporting API—a counterpart of the AWS boto3 library. In our earlier example of switching off a budget from the level of Cloud Functions, the googleapiclient library was used , and it was exactly what we needed.
In GCP, every service has its own API, but not all of them are turned on by default, so you will need to remember to turn them on before using them. That can be done via GCP web console, gcloud CLI or using Terraform.
We were aware that each service in GCP needed to be approached individually, as in the case of AWS. Since this solution is a proof of concept, we chose services that are counterparts of the services covered in our AWS cost optimization solution. Of course, there is room to add others, should the need arise.
-
Stopping Compute Engine instance
Compute Engine virtual machine instances are zonal objects. This means you need to search all available zones.You can get a list of zones and regions from the API.
We also discovered that a library allows you to define fields to be returned. This makes the entire code shorter. In the example below, only “id” and “status” fields are retrieved from the list of instances found in the zone:
compute_api.instances().list(project = project_name, zone = zone_name, fields='items/id,items/status').execute()
Instances that are turned on have the “RUNNING” status. After filtering them, we can stop them with the “instances().stop” method:
compute_api.instances().stop(project = project_name, zone = zone_name, instance = instance_id).execute()
-
Stopping instances managed by groups and autoscaler
As in AWS, the “instances().stop” method used above stops all standard instances. But using this method to stop the instances managed by instance groups will cause these instances to be relaunched by a group or autoscaler related to it. Therefore, to stop an instance managed by a group, update the settings of the group to which a given instance belongs or update the autoscaler.
To make sure that all instances are stopped, search all regions for autoscalers by using “regionAutoscalers().list.” Next, filter autoscalers that have the “Active” status and update them using the “regionAutoscalers().update, with” the update parameters put in the request body, for example:
"autoscalingPolicy": {
"minNumReplicas": 0,
"maxNumReplicas": 0,
}
And the call:
compute_api.regionAutoscalers().update(project = project_name, region = region_name, autoscaler = autoscaler_id, body=autoscaler_body).execute()
These actions stop only the auto scaling instances. Apart from those, you can also have instances managed by groups themselves—so-called “managed instance groups”. They require a different action, such as updating a group’s settings. To search for such groups, you can use the “instanceGroupManagers().list” method to search all zones. To stop instances, call the “instanceGroupManagers().resize” method with the parameter “size = 0”:
compute_api.instanceGroupManagers().resize(project = project_name, zone = zone_name, instanceGroupManager = managed_inst_group_name, size = 0).execute()
-
Stopping containers in the Kubernetes Engine (GKS) service
GKS service is used to manage Kubernetes-based containers. Before deploying a container, you need to create a Kubernetes cluster. But because such a cluster in GKS service cannot be stopped, we needed to approach it another way. Using Kubernetes API (the one that kubectl tool uses) was ruled out, as it would make our cost optimization solution too complicated. Neither did we want to use other libraries or delve deeper into the external tool configuration instead of the service itself. We therefore decided to look better into GKS clusters, and soon discovered that the instances that make up a Kubernetes cluster are managed by a ‘managed instance group’ resource. Scaling such a group down to zero yields an interesting result. A cluster is still visible as active but with zero nodes.
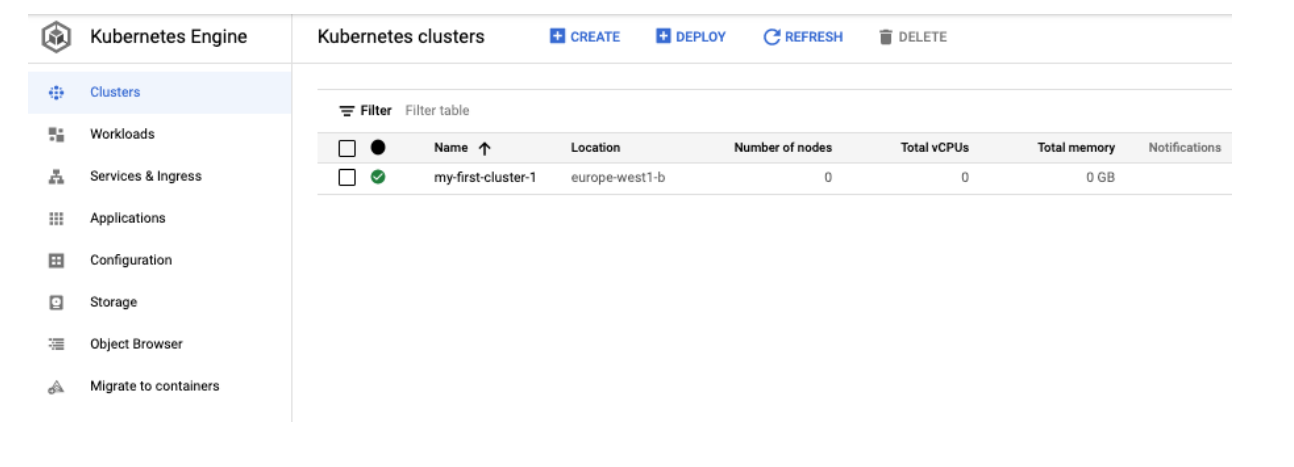
All deployed containers are of course switched off and this cluster no longer generates costs.
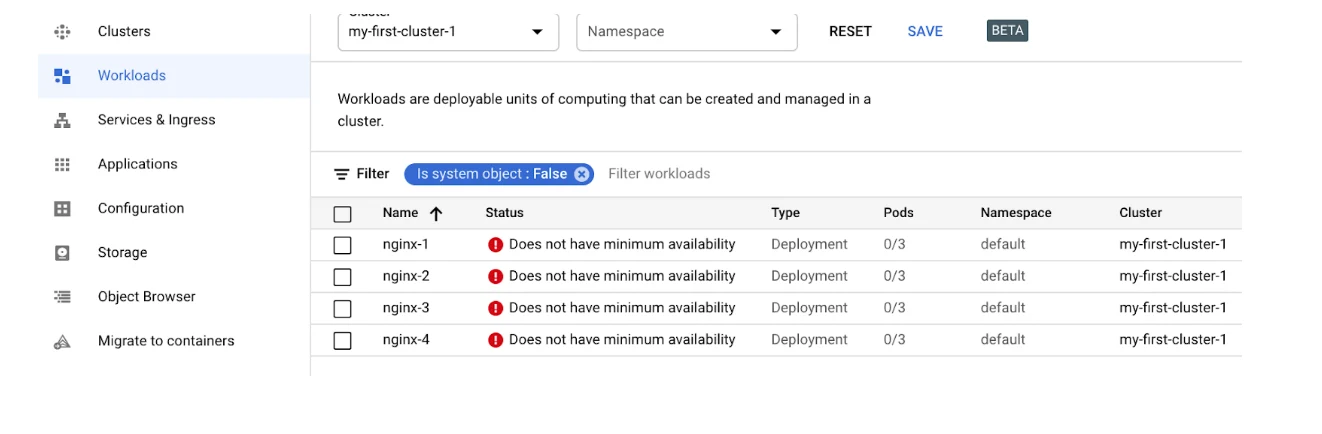
When you update the group settings again and set the instance number to a number other than zero, the cluster starts working again.
Strictly out of curiosity, we checked the API GKE documentation and found out that there is an option to update the number of cluster nodes directly in its configuration. After tests, we decided not to implement it, since updating managed instance groups had already been implemented in our solution and had the same effect: changing the number of instances in a group to zero, sets the parameter with the number of nodes to zero in the GKE cluster configuration.
-
Stopping instances of the SQL database service
Google Cloud SQL service is a counterpart of AWS RDS and provides relational databases as a service, though with fewer options. You can choose different versions of MySQL and PostgreSQL databases and MSSQL database. Regardless of the database type, when creating one you can choose the type and parameters of the virtual machine your database will be launched on.
At this stage you can also choose the failover mode, which allows you to launch an additional paid stand-by database that is not visible to users. The stand-by database is a copy of the main database localized in the same region but in a different availability zone. If the main database or its zone become unavailable, the main database’s IP will be set to point to the stand-by database. In our cost optimization solution, we do not have to bother about such stand-by databases. They are neither visible in the console nor accessible via API. They are related to the main databases and intentionally stopping the latter means the stand-by database will also be stopped.
After launching MySQL and PostgreSQL databases (we did not test MSSQL database) you can also launch a read-only replica of each database whether it has a stand-by copy or not. A replica is launched in the same zone as the main database and it is used for load balancing, allowing users to have additional read from the replica. For our solution, what’s important is that a replica database is stopped in a different way than a main database. This should be addressed in our function code.
You can get a list of replicas and main instances from API using the same “instances().list” method. The field “instanceType” informs you about the type of database:
“READ_REPLICA_INSTANCE”—for replicas
“CLOUD_SQL_INSTANCE”—for main instances
To stop a replica, use the “instances().stopReplica” method:
db_api.instances().stopReplica(project = project_name, instance = db_instance_name).execute()
To stop main instances, use the “instances().patch” method modifying the “activationPolicy” settings included in the body of our request:
"settings": {
"activationPolicy": "NEVER"
}
A method call will look like this:
instances().patch(project = project_name, instance = db_instance_name, body = db_instances_api_req_body).execute()
The final solution overview
Unlike with the AWS cloud, we do not need to use separate scripts for each region. Fig. 6 shows a schema of the solution:
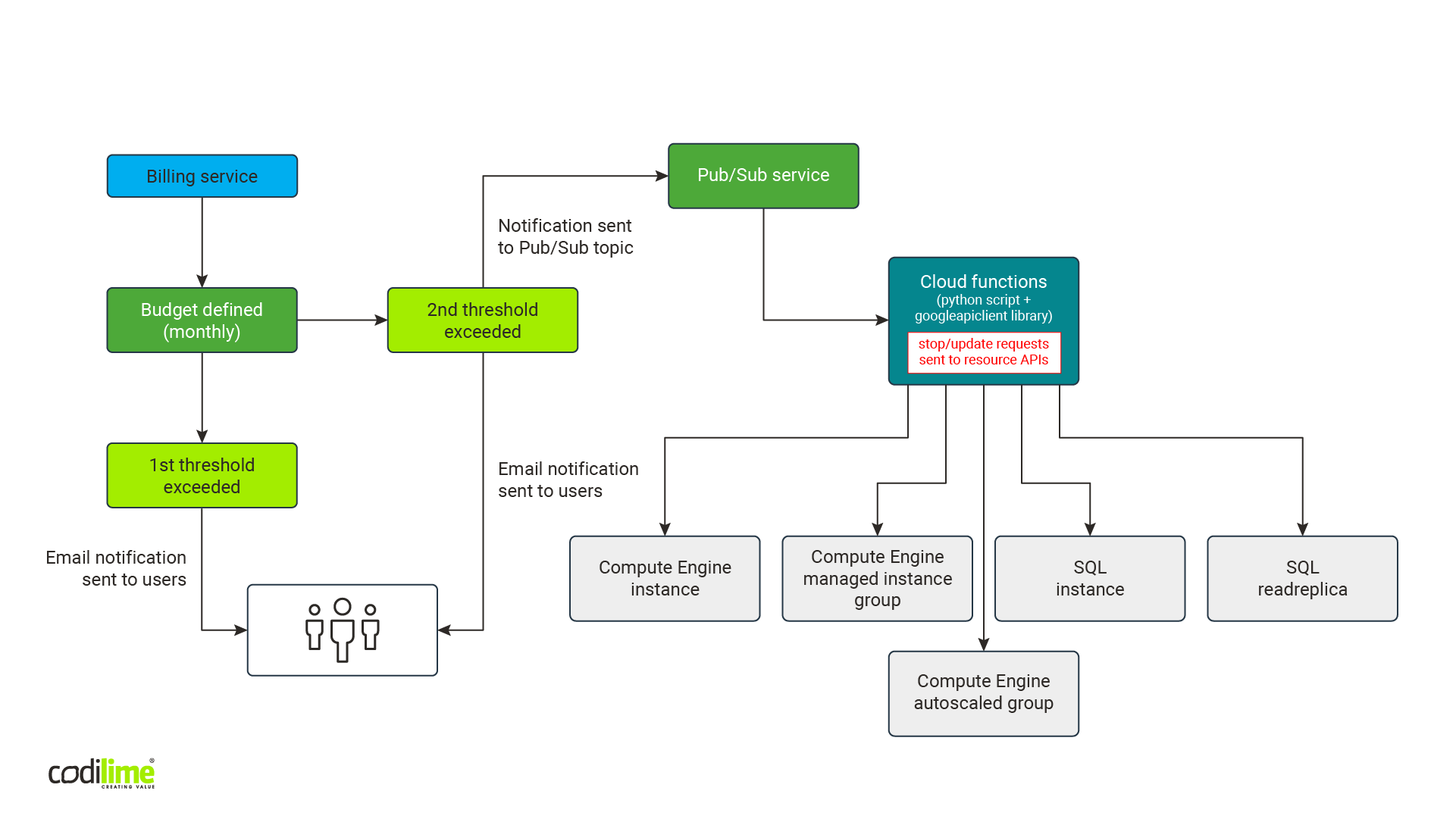
Like the AWS solution, this one generates almost no costs. Budgets are free. The Pub/Sub service has a free tier of 10 GB for messages that is renewed monthly. Even if it is exceeded by other messages, our solution will be sending no more than a few messages monthly, so costs will be negligible. The same is true for the Cloud Functions service. It offers a free-tier of two millions calls, 400,000 GB-seconds for memory usage and 200,000 Ghz-seconds for CPU usage (one GB-second is one second of wallclock time with 1GB of memory provisioned, one GHz-second is one second of wallclock time with a 1GHz CPU provisioned). Since our cost optimization solution will be launched a few times a month, it too will cost virtually nothing, even if we exceed the free tier.
Implementing the solution
To implement our solution, we decided to use Terraform. We prepared configuration files that can be easily adapted to the project where we want to implement the solution. Here a small issue occurred. To implement our solution via Terraform, we use an administrator account, while the billing system API requires a service account, which is different from a user account. Service accounts are used for communication between services.
We needed to find a workaround to help us set up and delete a budget using Terraform. The only option open was to use Terraform provisioner “local-exec,” which could be used to call the “gcloud billing budgets create” command with the appropriate parameters. “gcloud” is Google Cloud Platform’s CLI. Terraform calls the “gcloud” command locally on the workstation to create a budget with the appropriate parameters taken from the configuration file. The entire operation is a little tricky because this command needs to filter the ID of the budget being created. This ID is returned to a standard... error output (yes, precisely speaking to stderr instead of stdout as you may have expected) and must be saved in the file, so that it can be used later while performing the operation “terraform destroy”, i.e. delete the solution. “terraform destroy” uses the “gcloud billing budgets delete” command, but the destroy operation does not allow you to get Terraform variables directly. So, the only simple solution is to read them from the temporary files. This is the only way to pass the budget ID and billing account ID to the “gcloud billing budgets delete” command at “terraform destroy” operation.


Final remarks
For now, our solution enables you to stop only a few chosen resources. As the need arises, you can add other services. You can also change actions taken, like deleting instances or data. Finally, you can extend the functionality of both the AWS and GCP solutions by adding an option to start the resources that have been turned off, allowing the solution temporarily to turn resources on or off.


