


You have probably heard about ZFS. But perhaps you are still wondering what all the fuss is about, what it is exactly and how to use it. I’ve been using it for the past 3 years, so I hope I can help you understand how you can benefit from it.
In a nutshell, ZFS is a combined filesystem and logical volume manager. It is intended, first and foremost, to maintain data integrity, but also to protect data from the hardware and from the user and simplify storage administration.
ZFS was created at Sun Microsystems and open-sourced as part of OpenSolaris. It has since been ported to other OSes, including FreeBSD, Linux, and Mac OSX.If you want to know more about the origins of ZFS, ask Jeff Bonwick ![]() .
.
ZFS is typically used on large storage servers and works well there. Many also boot their operating system from it. While I’ve been using it for some time now as the root filesystem on both my personal and work laptops running Linux, I am going to walk you through what makes it worth using even on a laptop with a single disk. That said, the advice here will be geared towards desktops and laptops, and might not apply to a server configuration.
Basic concepts
Let’s go through the basic features and concepts that will help you get the idea behind ZFS.
ZFS Pool
A traditional filesystem is created on top of a single (physical or virtual) storage device. To allow for a more flexible configuration, ZFS has some additional concepts.
The first is a storage pool composed of one or more “vdevs” - groups of storage devices that can be arranged in redundant configurations (similar to RAID levels). Laptops usually have only one disk, so my pool has a single vdev of 1 disk.
Second is a dataset, which can be a file system or a virtual block device ("zvol") on top of the pool. All file systems share the free space of the pool by default, and zvols have a specified size (which can be changed at any time).
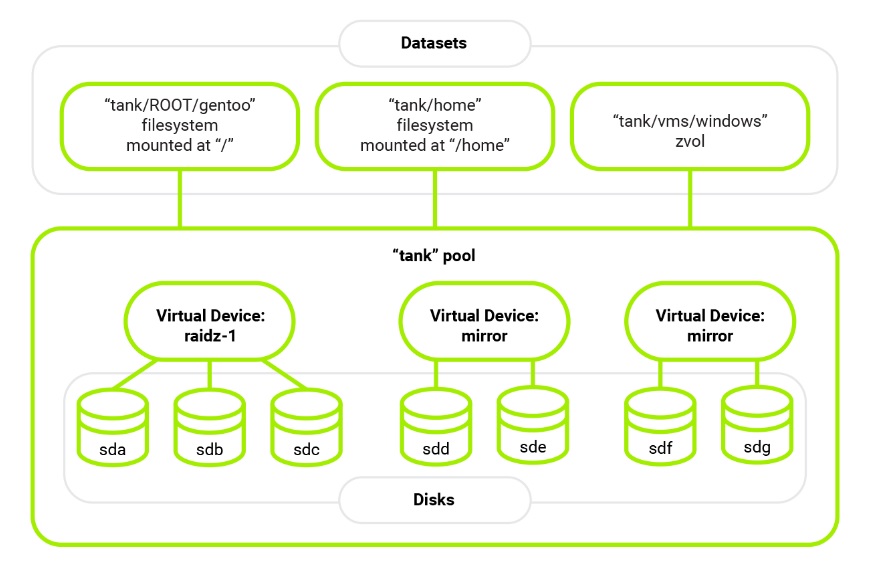
I like to experiment with different operating systems and file systems, and I used to have a partition for each OS installation, a separate /home partition, and others configured differently for different kinds of data. You may have encountered the same problem I did: partitions have a set size and are laid out sequentially on the disk, so sometimes you’d have more than enough space on one of them, while running out of space on another. Resizing and moving partitions takes time, and often has to be done while booted from a live medium, which is inconvenient. Using ZFS filesystems on the same pool for keeping OS installations and the user data pretty much solves the problem.
The configuration is stored in the pool itself
Datasets are configured using options called “properties”. Let’s take a look at some of the most useful ones.
- mountpoint, canmount and other mount-related options. When a pool is imported by the OS (most often, at boot time), its filesystems are mounted according to these properties. This way, a pool (its disks) can be moved to a different computer or OS (e.g. a LiveCD) and they will be mounted in the same way - there is no need to synchronize /etc/fstab, make scripts for mounting them or remember how to do that manually.
- compression - data is transparently compressed on the disk. The default compression algorithm (LZ4) is very fast, so it is usually a good idea to enable compression for all datasets. At work, in CodiLime, compression helps me when I have to analyze large logs (a few gigabytes uncompressed each); and it saves space in general - the compression ratio is 1.58 on the root pool on my work laptop.
- copies - additional redundant copies of data are stored on the disk. See “Data integrity” below.
- encryption (starting from ZFSonLinux 0.8) - different datasets can be encrypted with different keys, and can be backed up without being decrypted first.
- sharenfs, sharesmb - ZFS can also export filesystems with NFS or Samba without requiring a separate configuration file.
- case sensitivity - can be set to insensitive to use some Windows software under Wine.
- custom user properties - can be used as annotations by users or utilities.
Datasets are organized in a tree-like structure
For convenience, datasets are organized in a hierarchy. For example, this is what it looks like on my laptop at work, on a pool named cl
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
cl 220G 10.1G 96K none
cl/ROOT 95.2G 10.1G 96K legacy
<...>
cl/ROOT/sab-8 94.9G 10.1G 27.3G /
cl/ROOT/sab-8/usr 49.5G 10.1G 20.3G /usr
<...>
cl/grub 9.19M 10.1G 8.86M /boot/grub
cl/home 44.8G 10.1G 96K /home
cl/home/vozhyk 44.8G 10.1G 16.5G /home/vozhyk
cl/home/vozhyk/dev 6.58G 10.1G 6.20G /home/vozhyk/dev
cl/home/vozhyk/downloads 2.84G 10.1G 2.82G /home/vozhyk/downloads
cl/home/vozhyk/music 3.61G 10.1G 3.61G /home/vozhyk/music
<...>
cl/swap 10.5G 10.1G 5.95G -
Here, cl/ROOT/sab-8 is my root dataset (with Sabayon Linux) and cl/home/vozhyk is a dataset with my home directory. cl/home/vozhyk/dev contains my code and is configured with copies=2 for additional safety. cl/swap is a zvol used as swap space.
Property inheritance
Most properties are inherited from the parent dataset by default.
An example with compression
Create a dataset and its child dataset:
# zfs create cl/talk
# zfs create cl/talk/first
# zfs get compression cl/talk
NAME PROPERTY VALUE SOURCE
cl/talk compression on inherited from cl
# zfs get compression cl
NAME PROPERTY VALUE SOURCE
cl compression on local
Both have inherited the pool-level value of on.
Let’s say we want to put files we won’t frequently touch on cl/talk. We can use gzip-9, which provides stronger compression, but is much slower than the default LZ4.
# zfs set compression=gzip-9 cl/talk
# zfs get compression cl/talk
NAME PROPERTY VALUE SOURCE
cl/talk compression gzip-9 local
# zfs get compression cl/talk/first
NAME PROPERTY VALUE SOURCE
cl/talk/first compression gzip-9 inherited from cl/talk
The child inherits the value we set on the parent.
We can later reset the value to the one inherited from the pool:
# zfs inherit compression cl/talk
# zfs get compression cl/talk
NAME PROPERTY VALUE SOURCE
cl/talk compression on inherited from cl
# zfs get compression cl/talk/first
NAME PROPERTY VALUE SOURCE
cl/talk/first compression on inherited from cl
Note that no already written data is recompressed when the value is changed. You’d have to rewrite the files for that.
An example with mountpoint
# zfs get mountpoint cl/talk
NAME PROPERTY VALUE SOURCE
cl/talk mountpoint none inherited from cl
# mount | grep talk
When the value is changed, the filesystem is automatically remounted at the set mountpoint. If remounting fails, ZFS refuses to change the property value.
# zfs set mountpoint=/mnt/talk cl/talk
# mount | grep talk
cl/talk on /mnt/talk type zfs (rw,xattr,noacl)
cl/talk/first on /mnt/talk/first type zfs (rw,xattr,noacl)
# zfs set mountpoint=/mnt/FIRST cl/talk/first
# mount | grep talk
cl/talk on /mnt/talk type zfs (rw,xattr,noacl)
cl/talk/first on /mnt/FIRST type zfs (rw,xattr,noacl)
# zfs inherit mountpoint cl/talk/first
# mount | grep talk
cl/talk on /mnt/talk type zfs (rw,xattr,noacl)
cl/talk/first on /mnt/talk/first type zfs (rw,xattr,noacl)
There is also a canmount property, which can be set to on, off, or noauto.
canmount=off is helpful for using mountpoint inheritance without having to create the intermediate datasets. For example, you could do the following before installing Docker to have its data neatly placed in a separate dataset:
# zfs create -o canmount=off -o mountpoint=/var cl/var
# zfs create -o canmount=off cl/var/lib
# zfs create cl/var/lib/docker
This way, neither cl/var nor cl/var/lib will contain any data - all of it will remain in the root dataset; but Docker’s data will be written to cl/var/lib/docker. And, thanks to property inheritance, you can create more datasets under cl/var later without specifying the mountpoint or other properties you might decide to have in common for them.
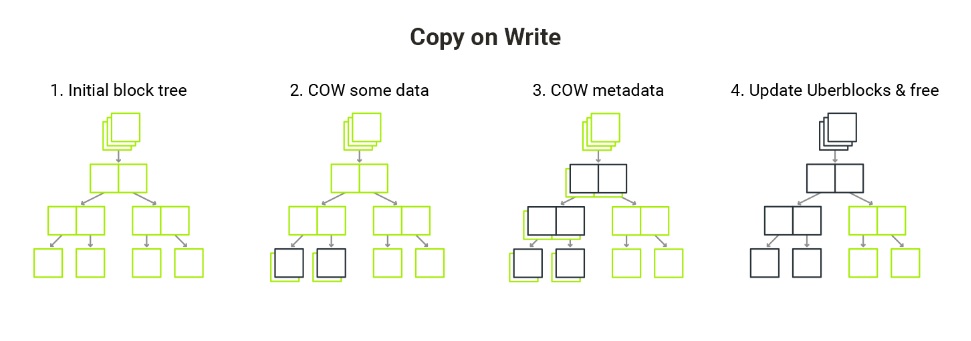
Copy-on-write
Whenever something is modified in the filesystem, the data is not overwritten - the modified data is put in a different place on the disk instead. Subsequently, the part of the metadata tree pointing to the changed element gets recreated. Only the uberblock - the pointer to the tree’s root - is overwritten (and a few of the previous pointers are kept around in case recovery is needed).
As a result, snapshots have little extra cost - creating a snapshot is immediate, it’s just a matter of taking a pointer to the current state of a dataset.
For more details, check out ZFS - The Last Word in File Systems by Jeff Bonwick and Bill Moore ![]() .
.
Useful features
Data integrity
Traditional filesystems (e.g. ext4) maintain checksums for metadata. This means that, if an inode (e.g. a description of a file or a directory) gets corrupted, fsck will notice that and remove the inode, removing the files that were accessible through it as a result. However, if a part of a file’s data is corrupted, the filesystem has no way of noticing that, and applications may read the corrupted data and behave incorrectly as a result.
In ZFS, both metadata and user data have a checksum that is verified on every read from disk. This solves the silent data corruption problem mentioned above.
Self-healing is a related feature worth mentioning. When data that doesn't match the checksum is read, ZFS tries to read a redundant copy. If it finds a copy with a matching checksum, it overwrites the broken copy with the correct one. Usually, the hard drive then re-allocates the broken sector to its reserved area. If no good copy is found, ZFS returns an IO error. What’s more, the checksum error counter gets increased (even if a redundant copy is found). The same happens if the medium returns an IO error.
This means that an application can’t read incorrect data. When there is a problem, you can learn about it either by looking at the pool’s error counter or from an e-mail, if the system is configured to send one (which may be the case in a server environment). This may help you decide whether or not to replace your disks.
I once had an SSD that returned incorrect data - it increased its error counter, but its SMART said it still had enough spare blocks. If a block’s error correction code is used, SSDs should relocate data to another block - before it can be corrupted. The one I had instead returned incorrect data and relocated the corrupted block after that.
I started doing backups then. I also rewrote everything with copies=2. This data redundancy allowed me to keep on going with my work without having to restore random files from the backup every day. However, the drive still had a high write latency. It eventually died, and I had to restore the backup to a new drive.
Snapshots
The simplest definition of a snapshot is “a read-only copy of a dataset”. Initially, it takes up no additional space. A snapshot references the old data, so even when you delete or replace some of it, it continues to take up space as part of the snapshot. (You can read more here ![]() .)
.)
A user can use zfs rollback to reset the dataset to the last snapshot, for example, to undo file removal. In order to roll back to a snapshot that is not the latest one, all snapshots newer than that (than the snapshot the user wants to roll back to) have to be destroyed.
- Snapshots are automatically mounted under the .zfs/snapshot/$snapshot_name directory under the dataset’s mountpoint.
This allows you to read or copy an old version of a file and to compare versions.
By default, .zfs is a hidden directory; but, with the snapdir dataset property, it can be made visible.
- zfs-auto-snapshot (or one of the more advanced tools) can be used to create snapshots periodically.
- zfs diff can be used to show differences between 2 snapshots or between a snapshot and the current state of the dataset.
Clones
A clone is a dataset started from a snapshot. Clones are read-write by default, but, like any dataset, can be made read-only.
A clone prevents its origin snapshot from being destroyed, so even if 2 clones have diverged from that snapshot so much that the original data is not present anymore, the snapshot keeps consuming space on the disk.
An example
Let’s create a dataset, put some files on it and modify them, creating snapshots as we go:
# zfs create cl/talk/snapdemo
# zfs snapshot cl/talk/snapdemo@empty
# touch /mnt/talk/snapdemo/test_file
# zfs snapshot cl/talk/snapdemo@created
# echo “first” > /mnt/talk/snapdemo/test_file
# zfs snapshot cl/talk/snapdemo@first
# echo “second” > /mnt/talk/snapdemo/test_file
# touch /mnt/talk/snapdemo/another_file
# ls -l /mnt/talk/snapdemo
total 1
-rw-r--r-- 1 root root 0 Jan 17 17:30 another_file
-rw-r--r-- 1 root root 13 Jan 17 17:30 test_file
# zfs snapshot cl/talk/snapdemo@second
We can list the snapshots and show the differences between them:
# zfs list -r -t all cl/talk/snapdemo
NAME USED AVAIL REFER MOUNTPOINT
cl/talk/snapdemo 288K 22.8G 104K /mnt/talk/snapdemo
cl/talk/snapdemo@empty 64K - 96K -
cl/talk/snapdemo@created 56K - 96K -
cl/talk/snapdemo@first 56K - 96K -
cl/talk/snapdemo@second 0B - 104K -
# zfs diff cl/talk/snapdemo@empty cl/talk/snapdemo@created
+ /mnt/talk/snapdemo/test_file
M /mnt/talk/snapdemo/
# zfs diff cl/talk/snapdemo@first
M /mnt/talk/snapdemo/test_file
M /mnt/talk/snapdemo/
+ /mnt/talk/snapdemo/another_file
Now, let’s say we remove all the created files by mistake:
# rm /mnt/talk/snapdemo/*
# ls -l /mnt/talk/snapdemo
total 0
We can easily undo that:
# zfs rollback cl/talk/snapdemo@second
# ls -l /mnt/talk/snapdemo
total 1
-rw-r--r-- 1 root root 0 Jan 17 17:30 another_file
-rw-r--r-- 1 root root 13 Jan 17 17:30 test_file
Now, say we want to use the version from @first. One way to do that would be to roll back to it. However, @second would first have to be removed. If we want to keep it, we need to do this: clone @first and swap the clone with the original dataset:
# zfs clone cl/talk/snapdemo@first cl/talk/snapdemo_new
# zfs rename cl/talk/snapdemo{,_backup}
# zfs rename cl/talk/snapdemo{_new,}
Now we can work with the data from @first while still preserving @second:
# ls -l /mnt/talk/snapdemo
total 1
-rw-r--r-- 1 root root 12 Jan 17 17:30 test_file
# ls -l /mnt/talk/snapdemo_backup
total 1
-rw-r--r-- 1 root root 0 Jan 17 17:30 another_file
-rw-r--r-- 1 root root 13 Jan 17 17:30 test_file
This method has a limitation: zfs rename has to unmount the given dataset then remount it (possibly, at a different location), which is not possible while a program is using the mount.
This is always true for the root filesystem. A workaround for that is to boot from a different clone of the root filesystem, so that no program uses the datasets we want to manipulate.
Boot Environments
Manually managing clones of root datasets (with their sub-datasets) with zfs tools tends to lead to errors. Commonly, a “boot environment” setup with some higher-level utilities is used to manage them and choose which one to boot from. I will cover this in a follow-up post.
Booting different OSs from the same pool
With some setup, it is possible for different Linux distributions, and even for different OSs that support booting from ZFS, to coexist on the same pool. I will cover that and the challenges involved in a follow-up post.
For more information, we encourage you to check our environment services.


