


Artificial intelligence (AI) and machine learning (ML) are trending topics in all technological domains. They offer a rich set of methods for data processing that can be used to solve practical problems, including those occurring in networks. We have prepared a series of articles to give you a better look at the various methods you can use for solving specific network issues.
Introduction to the subject of AI/ML methods for network issues
In a series of three articles, we present classes of AI/ML methods and algorithms that should play a key role in networking, considering the network/related data types they work on as well as specific types of problem they can help to solve. Regression, classification and time series forecasting are fundamental classes of ML algorithms that can process various network data. Their ability to learn data patterns, and their predictive capabilities, allow for a proactive approach in the context of network management and maintenance tasks. Cluster analysis, in turn, allows for the extraction of useful patterns and knowledge in network-related data, and grouping similar data into subgroups. We include anomaly detection to highlight its importance for processing network-related data, where many types of ML methods can be used. Another group is NLP (natural language processing) techniques that can be used for processing of network configuration-related data, for instance. For completeness, we briefly introduce reinforcement learning, explaining it in the context of network routing optimization. Finally, realizing the complexity of applying ML techniques, we discuss the main challenges that need to be taken into account when implementing these approaches to applying artificial intelligence algorithms to network problems.
- In this first article in the series, we focus on two classes of ML methods: time series forecasting and regression.
- In the second article, we will focus on the next two classes of ML methods: classification and clustering. We also added a section devoted to anomaly detection, an important topic in the context of network-related data processing, where various classes of ML algorithms can be used.
- In the third article, we will describe the next two classes of ML methods: natural language processing and reinforcement learning. Also, we will outline the major challenges of applying various ML techniques to network problems and summarize all three parts of the series.
Time series forecasting
We see time series forecasting as the primary set of ML algorithms that should be considered when entering various types of network-related problems. Why? Because network and data center monitoring is mainly done by collecting time series data. We are measuring a plethora of important values in time, such as flow bit rate, packet rate, packet delays, packet jitter, packet loss, round trip time, requests rate, throughput, CPU/memory consumption, etc. to name the most basic ones. All those values are measured in consecutive timestamps forming a data structure called a time series. The measured metrics allow us to assess the current state of the working environment, to detect or explain some existing problems and then to take action if needed.
Time series usually have different characteristics in time, of which the most important ones are a trend and a seasonality. Specific seasonal patterns and trend shapes are subject to automatic recognition by ML models. Based on historical values, such a model can forecast the future values of a specific metric in consecutive timestamps.
Figure 1 shows an ML model trained on historical data that predicts the bit rate of a traffic flow, appropriately reflecting its trend and daily seasonality. You can also notice outliers, i.e. unusual data points that can be reported as anomalies and are usually corrected (before you start training the model) in order to achieve a higher level of prediction accuracy. You will be able to learn more about anomalies and outliers in the anomaly detection section (in the second article of the series).
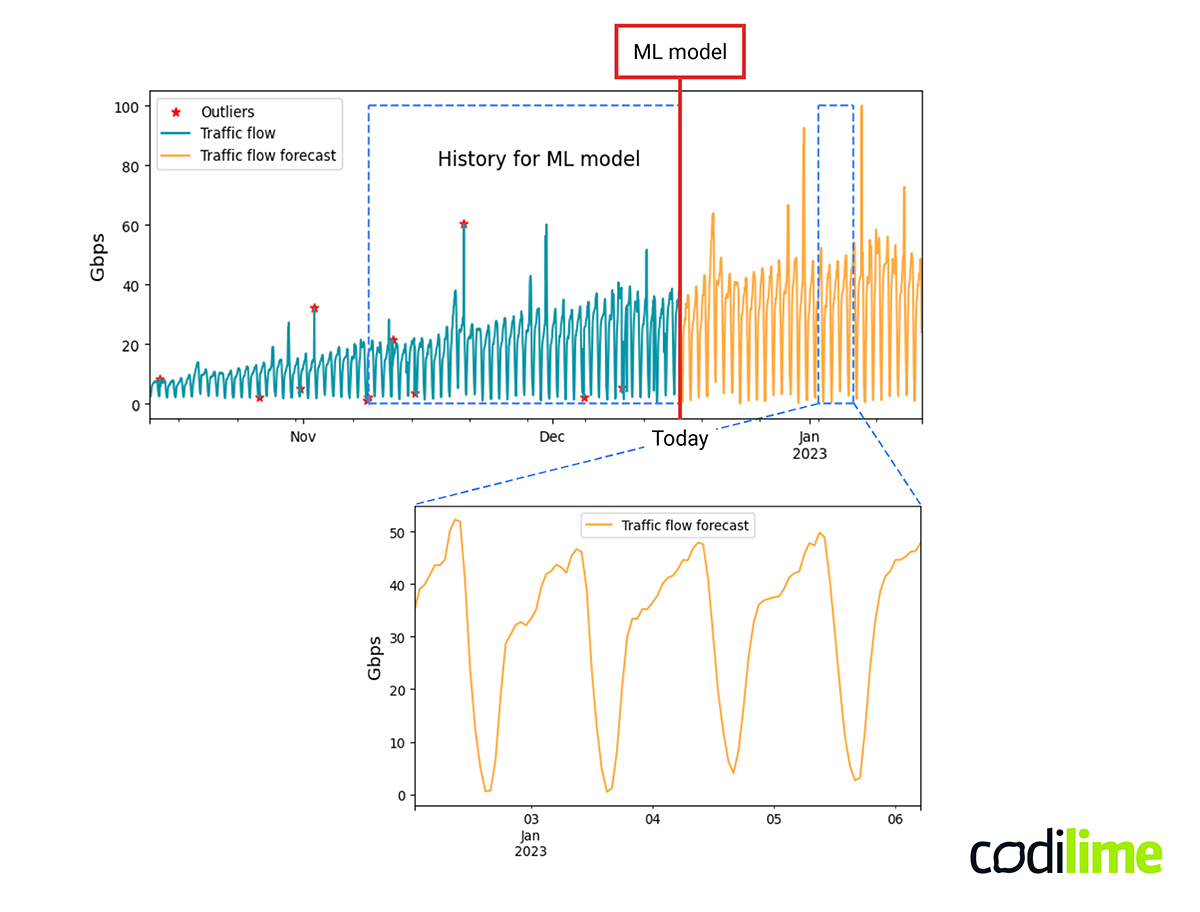
ML-based forecasting allows us to utilize the predicted metrics to build proactive decision support systems. For instance, long term forecasting of traffic or resource utilization can help us better plan necessary spendings on new equipment. Such cyclical predictions can proactively provide useful information on future “lack of capacity” problems on particular devices.
In turn, medium-term traffic flow bit rate forecasting between all endpoints in the network can be used to build a proactive system to warn about future congestion points or even proactively suggest routing changes leading to a load-balanced network state. The key word here is proactivity - you can solve a problem before it really occurs.
Finally, short-term forecasting of time series data can also be used for anomaly detection. The forecast indicates the “expected value” for the next metric measurements. If there is a large difference between predicted and measured values, an alert can be raised. It is a common practice to define thresholds for a specific metric to raise alerts when the metric value is over or under the predefined thresholds. Detecting anomalies based on comparison of actual values with expected values allows for raising alerts for anomalies also when the values do not exceed the defined thresholds, as the forecast is used as a reference.
Time series forecasting is one of our data science services. Click to read more about them.
Popular methods for time series forecasting
Below we list several of the most popular methods for time series forecasting. Other models can be found in such libraries as darts ![]() , GluonTS
, GluonTS ![]() or sktime
or sktime ![]() .
.
- ARIMA
 (Autoregressive Integrated Moving Average), SARIMAX (Seasonal ARIMA with eXogenous factor), VARIMA (Vectorized ARIMA)
(Autoregressive Integrated Moving Average), SARIMAX (Seasonal ARIMA with eXogenous factor), VARIMA (Vectorized ARIMA) - Exponential smoothing
- Prophet
- Theta model
- TBATS (Trigonometric seasonality, Box-Cox transformation, ARMA errors, Trend and Seasonal components)
- LSTM (Long Short Term Memory)
- DeepAR (probabilistic forecasting with Autoregressive Recurrent networks)
- N-BEATS (Neural Basis Expansion Analysis for Interpretable Time Series forecasting)
- Temporal Fusion Transformer
There is no single method that is best for particular time series data, as much depends on data resolution, available historical data, required forecasting horizon and the statistical characteristics of the data. A multi-model approach can also be used, as a good practice that may lead to improved forecasting accuracy. It consists of decomposition of a time series into trends, seasonal and residual components, and applying various algorithms for forecasting them separately. Finally, such forecasted components are merged to retrieve a final forecast.
In the field of network and data center infrastructure, it is necessary to simultaneously forecast multiple time series from similar sources. One approach is to train a single, global model for the entire base of such correlated time series, and then use it to forecast each time series. In terms of forecast accuracy, it may be advantageous to train a global model, as it can take into account correlations between different time series from the database. VARIMA, DeepAR and Temporal Fusion Transformer are examples of such a global approach. An alternative approach is to apply a forecasting model separately to each time series, the so-called local approach. The other mentioned approaches usually create models for a single time series. We have to remember that taking into account the freshest data when training a model, usually provides better predictions. This means that models have to be updated (retrained) over time to keep a desired level of forecasting precision. This requires additional computing infrastructure.
Regression
Regression is a type of supervised learning method. Regression algorithms try to predict an output variable based on input variables (also known as features), and the output is a continuous numerical value (see Figure 2). As it is a supervised learning approach, both input variables (independent variables) and the output variable (dependent variable) must be collected for the training process. ML regression models can learn complex relationships between input features and the output variable, trying to find the function best mapping input variables to the output variable. Thanks to such a function, the output variable can be easily evaluated for a new record of input variables.
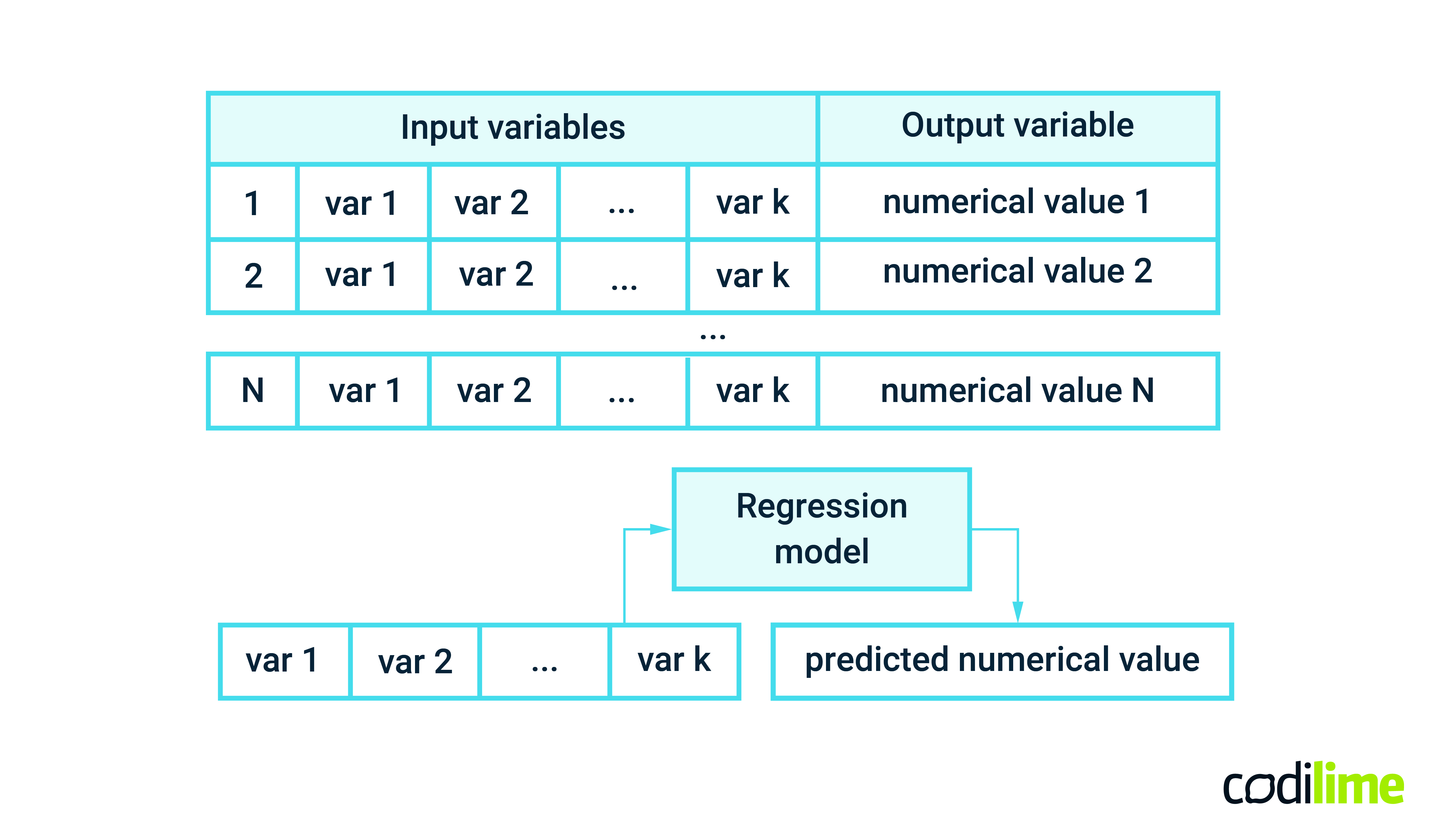
In a network and data center management context, regression models can be useful e.g. to find relationships between QoS (Quality of Service) metrics and QoE (Quality of Experience) indicators. QoS metrics such as delay, packet loss, jitter, throughput, etc. refer to objective, system-related characteristics that provide insight into the performance (at the network level) of the service you want to deliver. On the other hand, QoE indicators measure performance of a particular service from the perspective of users. Consider a video streaming service - typical QoE metrics are the video startup time, video resolution, playback failure rate, rebuffering rate or an overall user satisfaction (for instance using 0-to-10 rating scale). The QoE metrics can be objective and subjective and should properly reflect the true user satisfaction and willingness to continue using the service.
Finding correlations between QoS and QoE metrics allows us to build regression models describing the strength of influence of particular QoS metrics on QoE metrics. Such regression models can help identify those QoS metrics that have to be improved in order to optimize QoE metrics and thus increase the level of users’ satisfaction. From a practical point of view, QoE monitoring can be expensive and problematic as the measurements should be collected on user devices or via user surveys. Therefore, such measurements are usually only made periodically. However, having the computed regression models one can assess QoE metrics based on QoS metrics (the latter are a bit easier to measure because they do not require user involvement).
Regression algorithms are often associated with time series data. By this, we mean scenarios where the input feature is time and the output variable is a measured metric. The linear regression approach for quick trend evaluation of a measured metric is a basic, well-known and often used method. Also, other functions like polynomial, logistic, exponential, power, etc. can be used to reflect future trends in measured data. So, the natural question is when to use a regression algorithm and when to use a more sophisticated time series forecasting algorithm. The answer depends on the objectives, but there are some hints.
Regression algorithms in the context of time series data are more often used for evaluating trends. For instance, having monitored resource utilization (CPU, memory, link capacity), using simple linear regression you can assess when you will suffer from a lack of resources. When you are interested in trends but also seasonality (daily, weekly), you will instead use algorithms for time series forecasting, more specialized in seasonal pattern recognition.
For example, forecasting traffic flows in terms of their peak hours and hourly bit rate distribution (seasonality) allows you to group flows that can compensate for each other. (i.e. when one flow is high, the second one is low and vice versa). It can be beneficial for load balancing when we can route such traffic flows to share the same resources (links, paths in the network).
Similarly, consider two different applications, where one is extensively used during working hours and the second one is extensively used in the evenings. The knowledge of such different, compensating seasonalities in terms of incoming and outgoing traffic can be used to instantiate such applications on the same infrastructure component (e.g. the same node of a Kubernetes cluster) if it does not break any other constraints, of course (e.g. related to security, etc.). The load characteristics of given links and network interfaces will then be more balanced compared to the situation when a pair of applications having traffic peaks at the same time are instantiated on the same infrastructure component.
It is also worth mentioning that a specific regression algorithm can also be used as a component of trend evaluation in time series forecasting, when a time series decomposition method is used. In such a case, the final algorithm can be composed of multiple models corresponding to different classes of ML problems.
Popular regression models
Below we list the most popular regression models that can be applied in various use cases.
- Linear Regression
- Ridge Regression
- LASSO Linear Regression (Least Absolute Shrinkage and Selection Operator)
- Elastic Net Regression
- K-Nearest Neighbors
- Classification and Regression Trees
- Support Vector Machine (with non-linear kernel)
- Neural network regression

In this first part, we have presented two classes of ML problems: time series forecasting and regression. We briefly described which data they work on and what they can produce as outputs. We have suggested a few ideas for using them in the context of network and DC management and listed examples of the most popular algorithms.
In the next part, we will focus on two other classes of ML problems: classification and clustering. Also, we will outline the role of anomaly detection in network-related problems.


