


The consensus algorithm is a process that enables agreement on a given value/decision across multiple members of a distributed system. Recently, Raft has gained popularity as a preferred consensus algorithm. More and more products, such as databases (Etcd, ClickHouse) or messaging systems (RabbitMQ, Kafka), have incorporated it.
However, software engineers usually do not interact with Raft directly but through solutions built on top of it, like those mentioned earlier. This raises the following question: What is the value of taking a closer look at Raft? In my opinion, there are two reasons.
Raft addresses obstacles that may arise when designing fault-tolerant systems, many of which overlap with the difficulties developers face when building highly reliable systems. Being aware of these challenges can help prevent future headaches. Secondly, there is no silver bullet in software engineering, and Raft has its limitations, which are also present in Raft-based solutions.
The purpose of this article is to provide insights into Raft's internals, its assumptions, and how it addresses the distributed system challenges. But before we dive into that, I would like to explain why we need a consensus algorithm in the first place and the problems it aims to solve.
Rationale
Let’s assume we are building a simple key-value storage with Put(K, V) and Get(K) operations. Also, we need it to be fault-tolerant, so when a failure occurs, the system as a whole remains operational and reflects all issued operations. This forces us to have multiple servers that somehow maintain identical data at all times despite the changes caused by Put operations. To achieve this, we need a synchronization mechanism. Practice shows that implementing such a mechanism is highly nontrivial. Of course, this will be a proof by example, but I hope it will pinpoint the issues of such a solution.
Consider the following setup:
- 3 servers.
- Only one server handles client requests. Let’s call it the leader. The remaining two servers are called followers.
- After every Put operation, once the response is sent to the client, no matter what was the result of the operation, the leader signals all followers to perform the exact same operation.
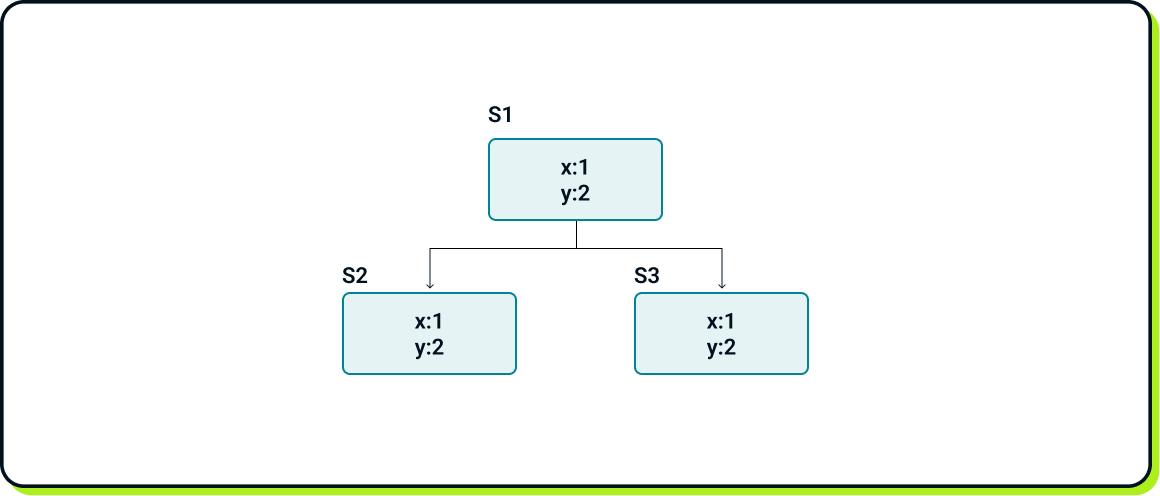
Imagine a flow where S1 is the leader.
The client successfully issues the following operations: Put(x, 1) and Put(y, 2).
As a result, the system state should look like:
Now, the client issues Put(x, 3).
However, as soon as the client receives confirmation that the operation was successfully performed, S1 crashes before notifying any of the followers. As a result, we end up in the following state:
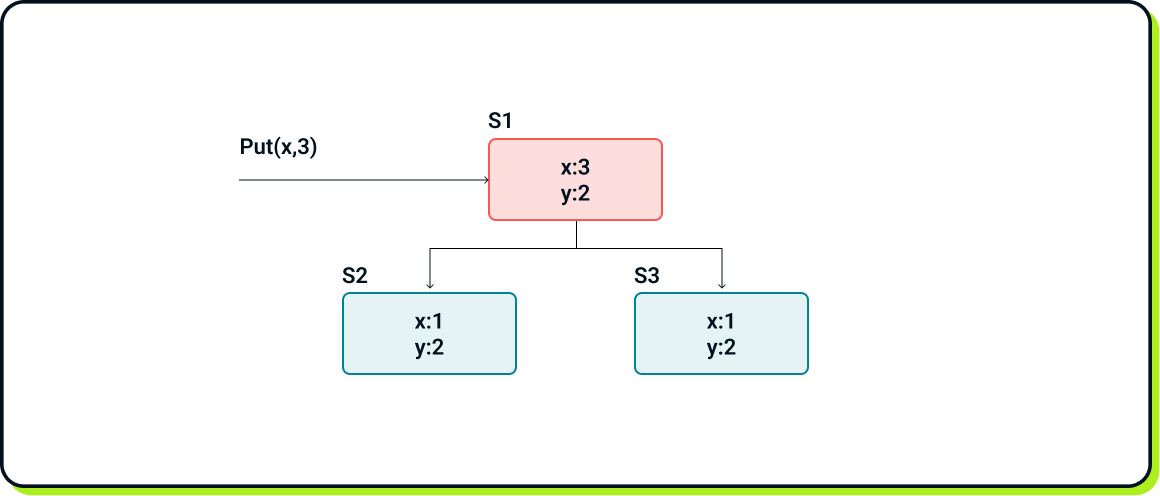
Now, a few issues arise:
First and foremost, S2 and S3 have no knowledge of Put(x, 3), and with the current setup, there is no way to recover from that. For the system to remain operational, either S2 or S3 must become the leader. This necessitates a mechanism to choose a new leader, as well as a detection mechanism to determine whether the current leader is alive.
Let’s assume that S2 becomes the new leader. How does the client know that S2 is now the leader? What should happen when S1 becomes operational again? It is no longer the leader and must catch up with all the changes that occurred during its absence to be useful.
Consensus algorithms offer a cohesive solution for issues like those depicted above. This is where Raft steps in.
State machine and log
Formally, Raft assumes that there is a “state machine” that needs to be replicated across a set of collaborative servers, known as a Raft cluster, which maintains this state using Raft as a consensus algorithm. This state machine has a defined set of operations exposed to users that can alter its internal state. For example, such a state machine could be a key-value store with Put(K, V) and Get(K) operations. We will stick with this example throughout the rest of the article.
But, in general Raft does not limit what operation is, from its perspective is a payload attached to the log index that later can be executed against a state machine. Raft itself does not inspect operation content.
In the context of Raft, the log is an integer-indexed ordered list of operations issued by clients against the state machine.
Here is a sample log for our key-value storage:

The main goal of Raft is to ensure that the log is replicated across all servers, and that operations from the log are executed in correct order and only if certain conditions are met, ensuring that executing an operation against the state is safe. The later parts of this article will explain in detail how Raft manipulates the log.
Term and election
A term is an integer that represents a logical time in the Raft cluster life cycle. It lies at the heart of Raft, organizing leader elections and log replication. Each log entry includes the term number alongside the operation, which increases monotonically over time after each leader election.
Servers (peers) in a Raft cluster can be in one of three states:
- Leader
- Follower
- Candidate
The leader is exclusively responsible for communication with clients, sending information to followers about new log entries. It periodically sends heartbeats to maintain its leadership.
Followers accept new log entries from the leader and transition into the candidate state when the leader's heartbeats are absent during a period called an election timeout.
Each peer is eligible for being a candidate, but the whole election process can be finished before some servers become candidates, due to the fact that followers nodes are entitled to voting if their term is lower than candidate’s one. The later part of this section explains why it is a crucial Raft’s property.
When a server becomes a candidate, it first increases its term and initiates an election by voting for itself and requesting votes from the other peers. Three possible outcomes can occur:
-
Turns into leader
The candidate becomes the leader if it collects a majority of votes (which is why the number of peers should be odd). A majority ensures that there is only one leader for a given term, as each peer can only vote “yes” once per term.
-
Turns into follower
The candidate reverts to a follower upon receiving a heartbeat from another peer with an election term that is equal to or higher than its own. This indicates that another peer has become the leader.
-
Voting is inconclusive
If the voting results in a split, the candidate remains in the candidate state, sleeps for a duration equal to the election timeout, increases its term, and initiates a new round of voting.
Example of voting results:
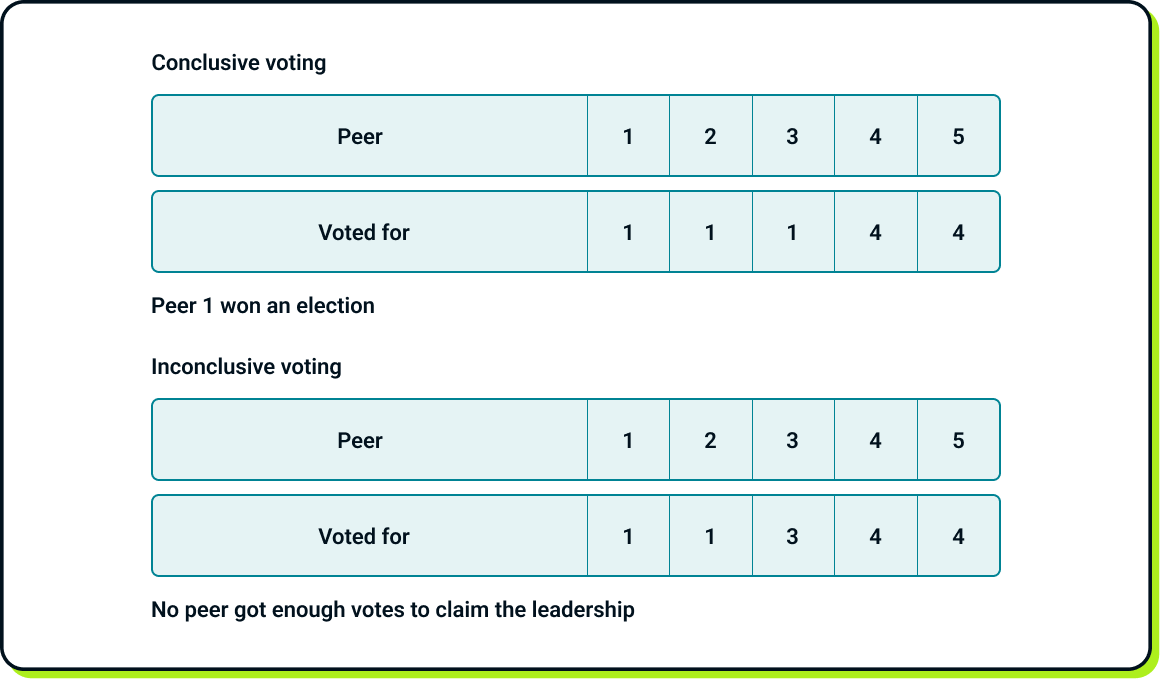
So, can we get stuck in an infinite loop of inconclusive votes? Theoretically, yes, but practically, this is unlikely. Raft incorporates a degree of randomness in its mechanism. The election timeout does not have a fixed value. Instead, it is randomly chosen from a predefined range, independently by each peer in every election. This randomness increases the likelihood that at least one peer will have a shorter sleep duration than the others, allowing it to increase its term and gather the majority of votes before the others wake up to respond to vote requests.
Additionally, there is a restriction for peers aspiring to become a new leader that is related to their log. I will explain this limitation after covering the log replication mechanism.
Log replication
Now it’s time to dive into Raft’s internals. Each Raft peer maintains a set of variables that can be categorized into three types:
Persistent variables:
- currentTerm - the highest term that the peer is aware of.
- voteFor - the name of the peer that received a vote from this peer in the current term.
- log: An ordered list of operations to be executed against the state machine.
Volatile variables on all servers:
- commitIndex - the highest index of the log known to be replicated in the cluster.
- lastApply - the highest index of the log known to be applied against the server’s state machine.
Volatile variables on leader servers:
- nextIndex - a table that tracks which entry(ies) need to be sent next to each peer.
- matchIndex - a table that tracks how much of the log has already been replicated by each peer.
This may seem to be a lot of new terminology, but let’s begin with a high-level overview of the key-value store system replicated using Raft.
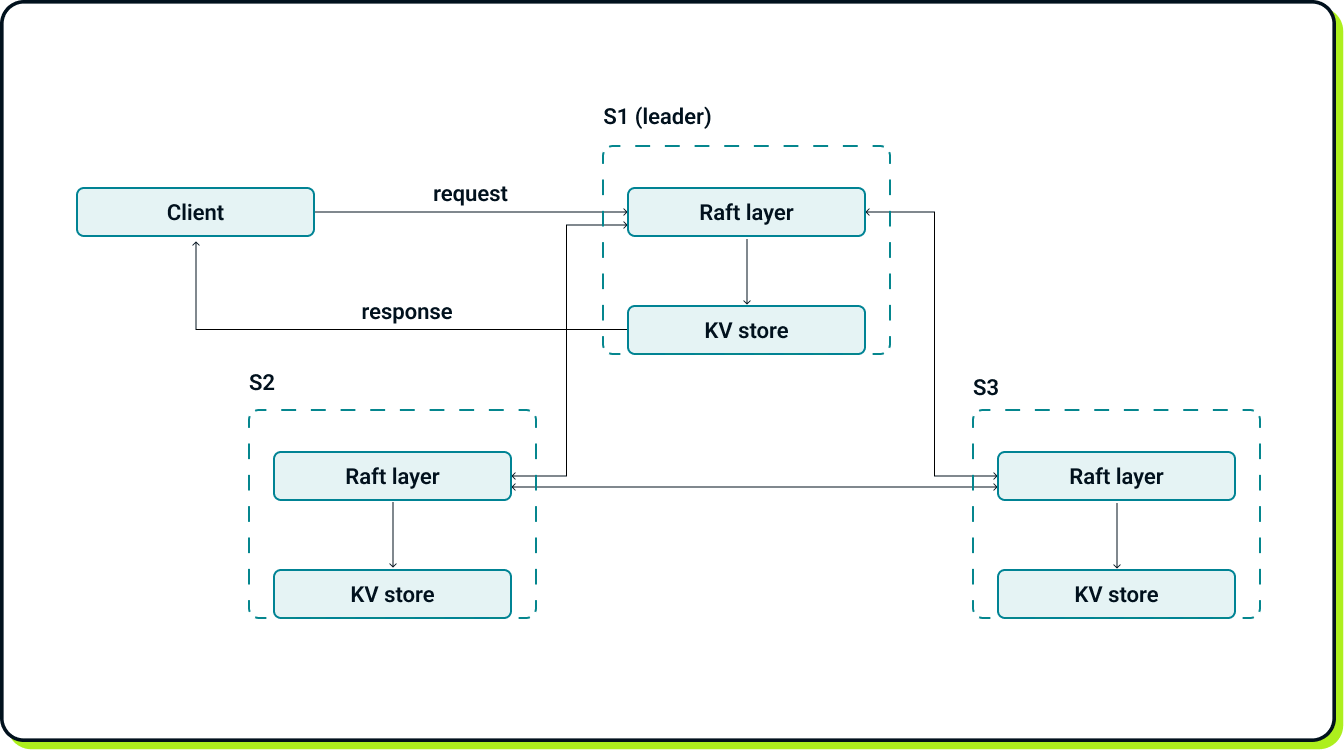
Clients do not interact directly with the key-value (KV) stores; all interactions occur through the leader's Raft layer. Additionally, there is no direct communication between KV stores. Clients must know the complete list of servers in the Raft cluster in advance, and each follower, when called by a client, redirects the request to the leader. All operations on the KV store are performed with the permission of the Raft layer.
Now let’s assume that S1 is the leader for term 1 and that a client is interacting with it. The internal state of Raft looks as follows:
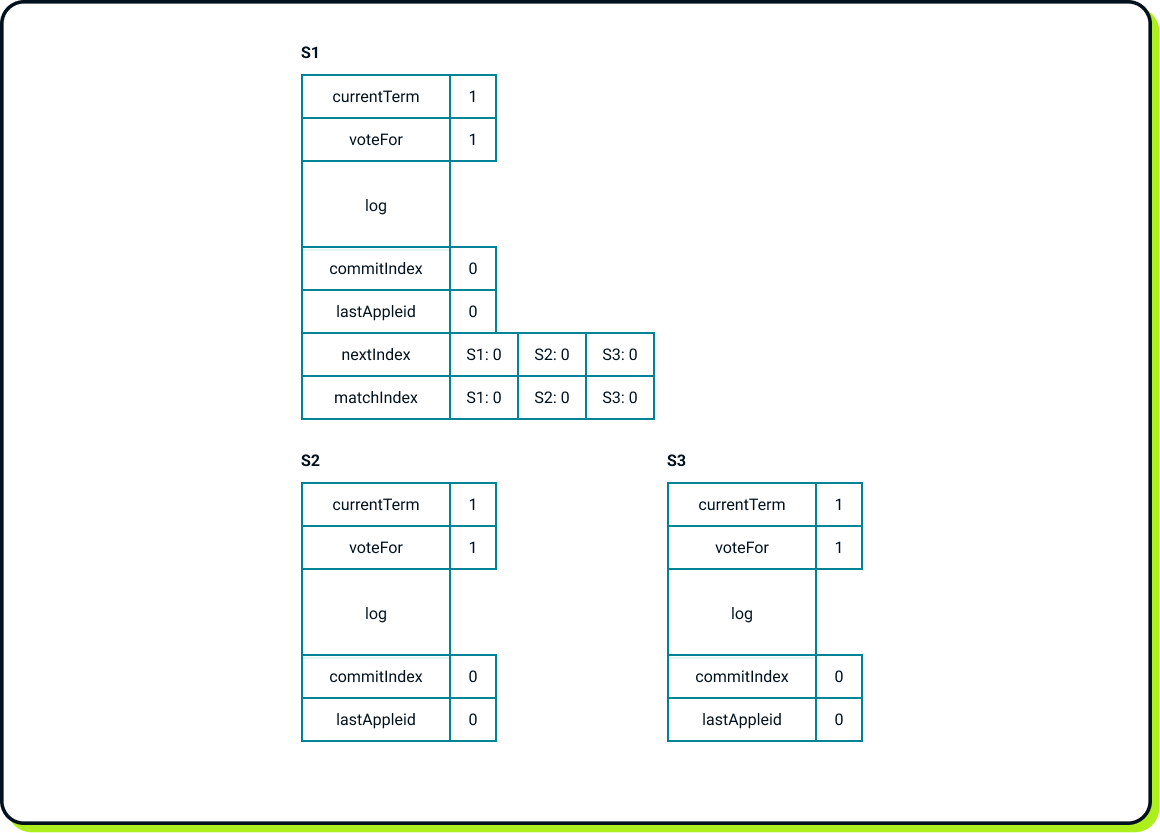
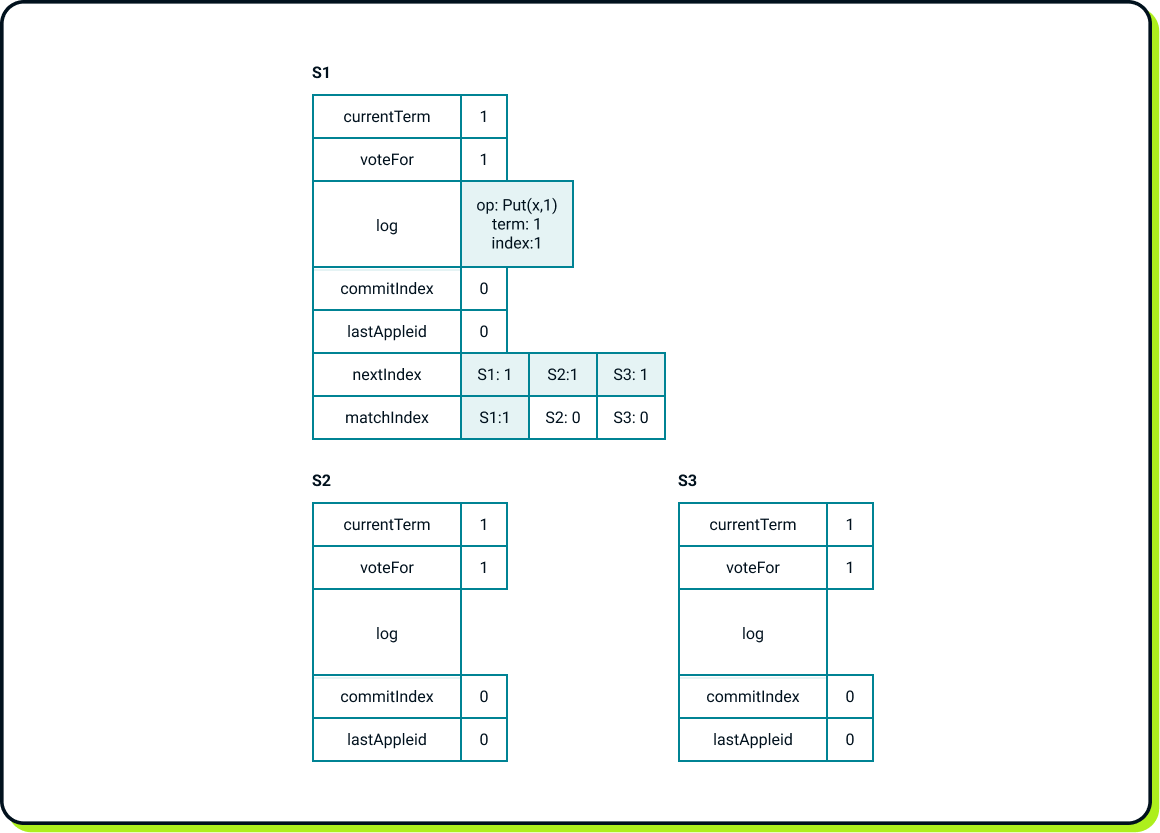
And now the client initiates the Put(x, 1) operation. The first thing the leader does is append this operation to its log and update the nextIndex and matchIndex entries for itself. The leader periodically sends all log entries with indices higher than the corresponding entries in the nextIndex table to each follower. In this scenario, S1 sends a single log entry with index 1 to S2 and S3. After sending, S1 updates its nextIndex entries.
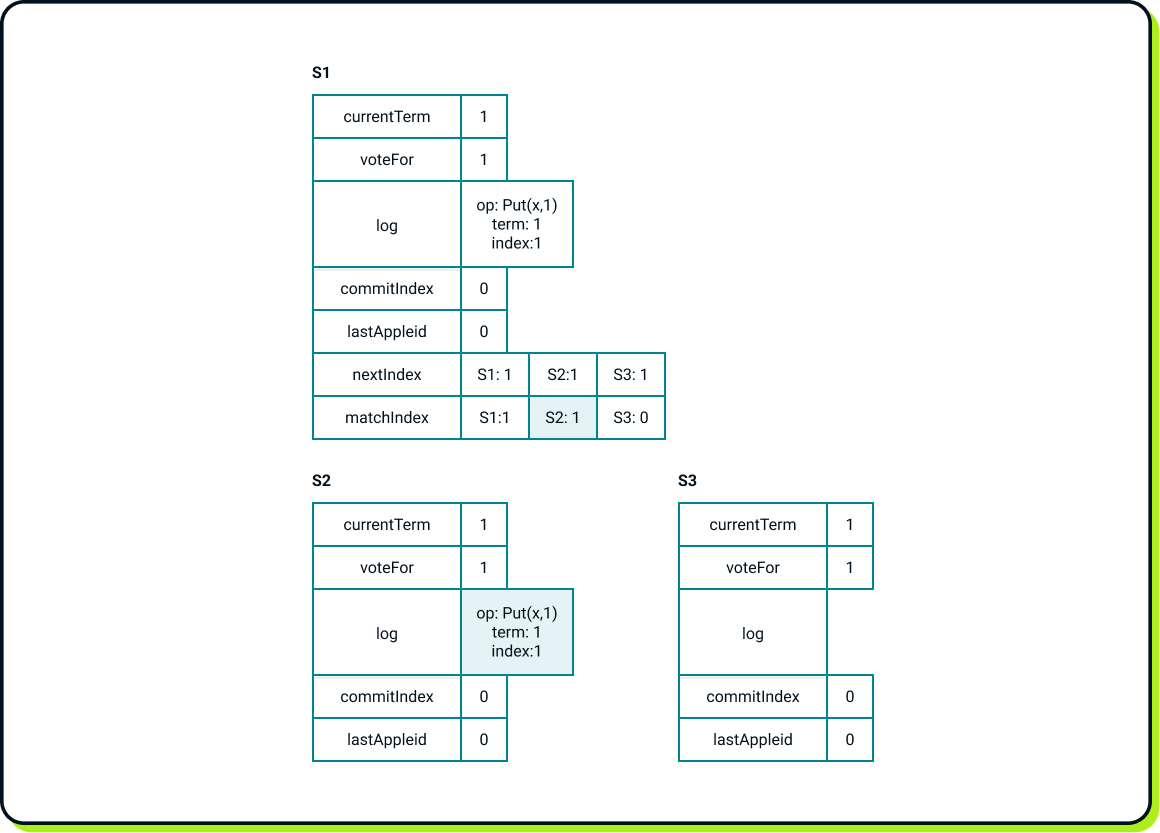
Let’s assume that S2 received the message faster, accepted the entry, and responded to the leader. Upon receiving the response, S1 updates the matchIndex entry for S2.
Raft marks a log entry as committed only if it is replicated on a majority of servers. In this case, the log entry with index 1 is replicated on 2 out of 3 servers, allowing it to be marked as committed. Now, S1 is allowed to increase the commitIndex.
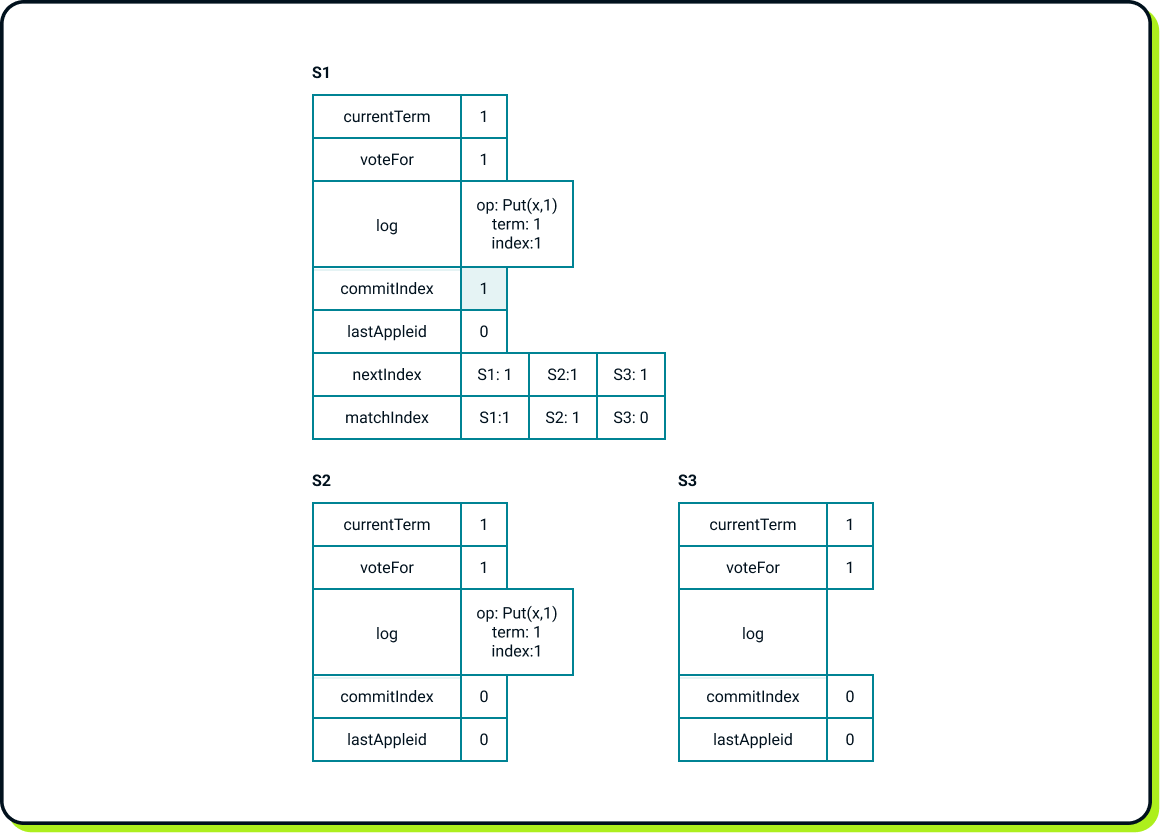
Now, S1 is finally allowed to execute the Put(x, 1) against the state machine. After the operation is executed, S1 can report the results to the client and increase the lastApplied index.
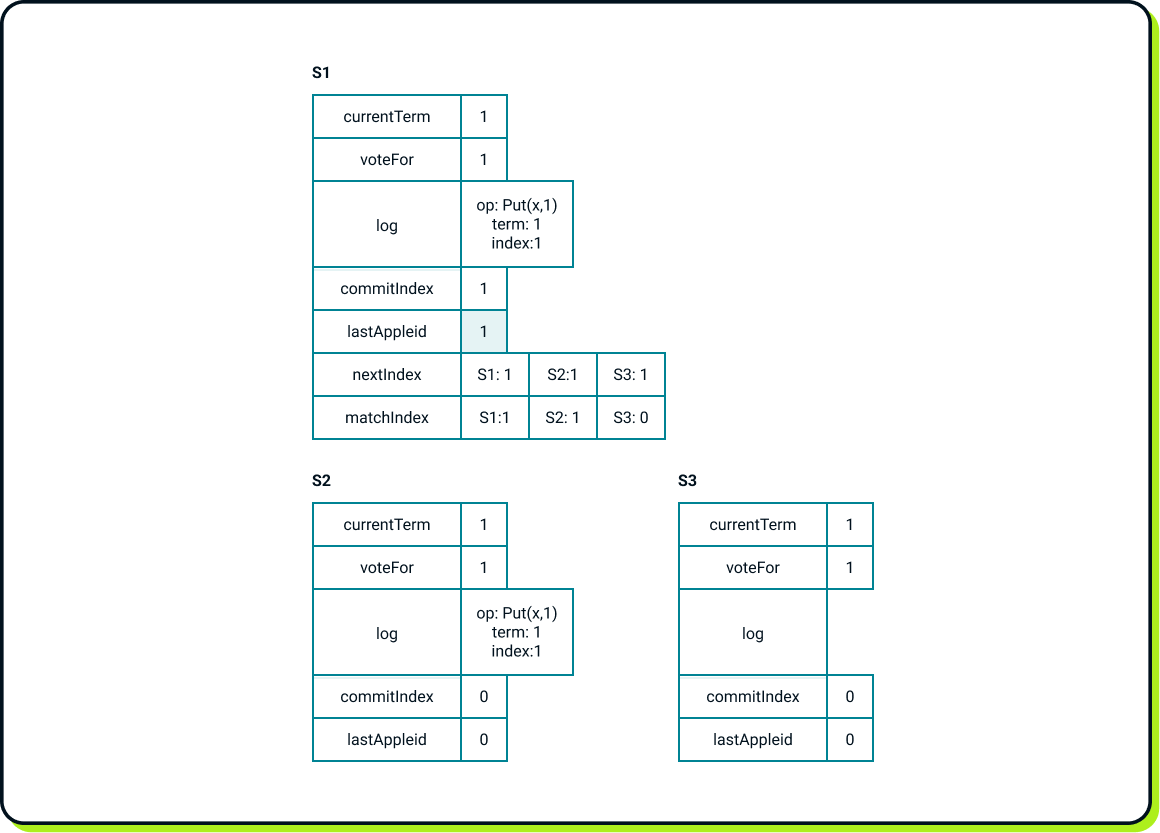
In these periodic messages to the followers, which also serve as heartbeats (when there are no new entries to be sent), the leader communicates its commitIndex so that the followers can update their state machines. After receiving such a message from the leader, S2 updates its commitIndex, executes Put(x, 1) against its own state machine, and updates its lastApplied index.
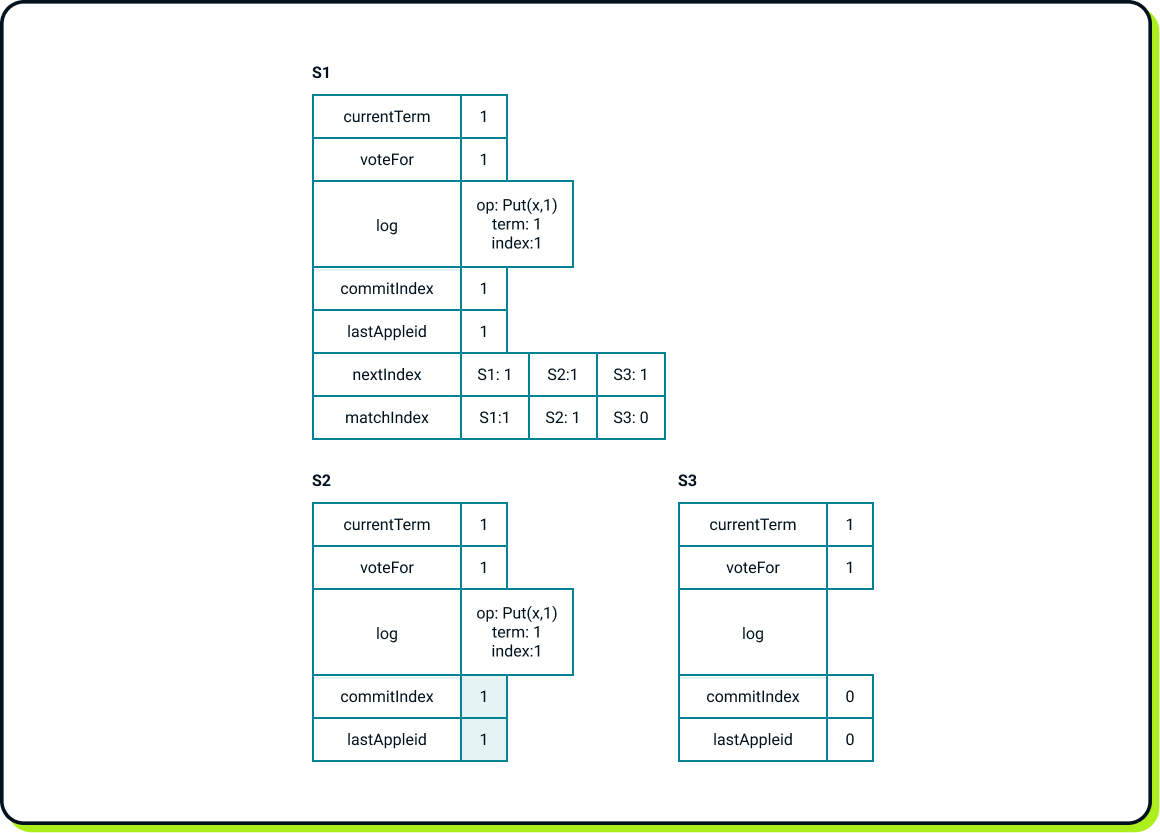
After a short network lag, S3 catches up with the entire Put(x, 1) operation.
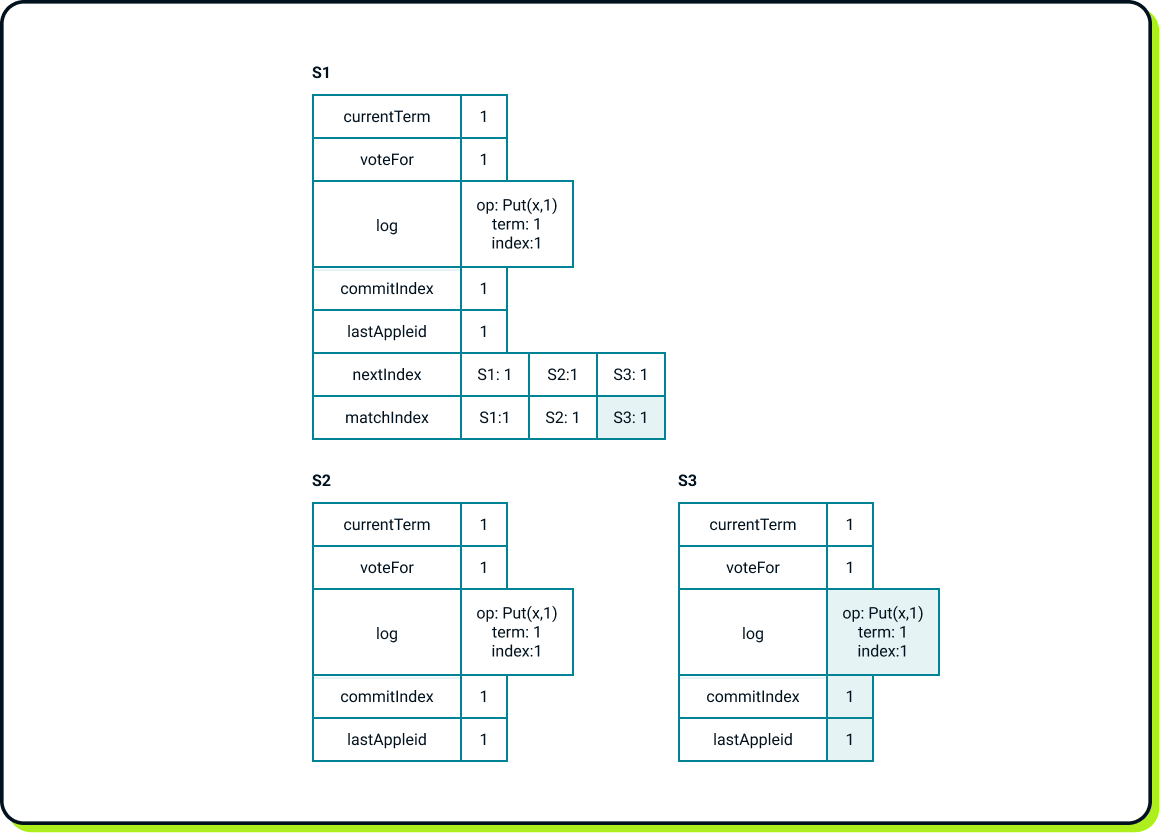
Now let’s imagine that clients issued two operations, Put(y, 2) and Put(x, 3), almost simultaneously, but once again, S3 remains unresponsive. As a result, we end up with the following state:
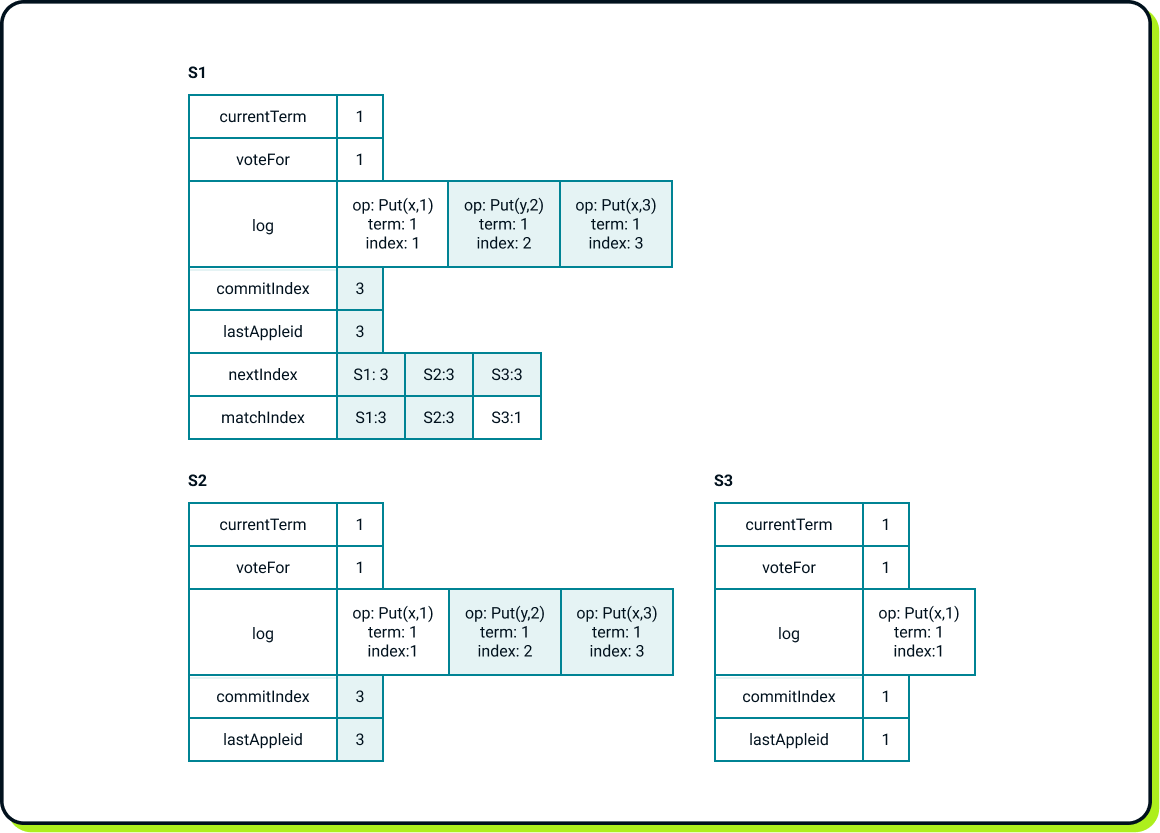
And now the client requests Put(x, 4). S1 appends it to its logs but suddenly crashes before notifying its followers!
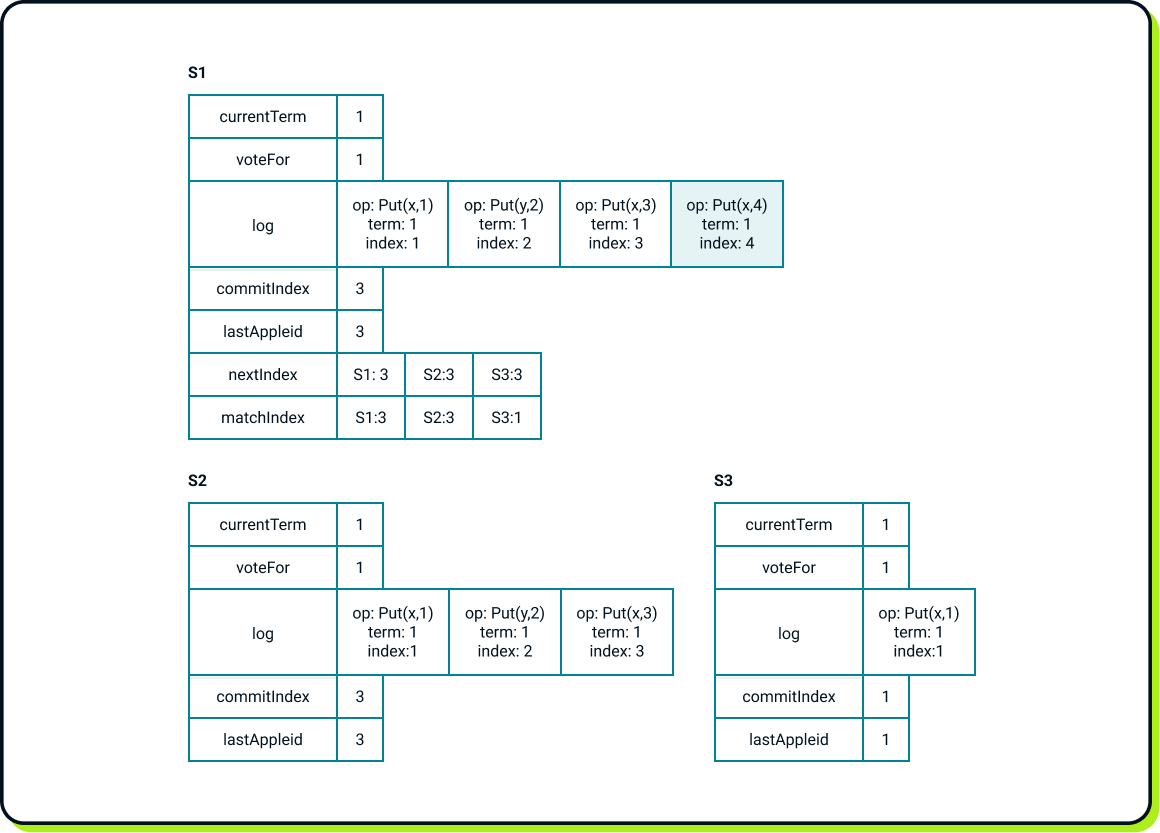
Now we need to elect a new leader. This is also the perfect time to revisit the additional restriction regarding the new leader’s log. In Raft, a peer can vote "yes" for a candidate only if the candidate's log is at least as up-to-date as the peer’s own log. The criteria are straightforward: between two logs, the one that is more up-to-date has a higher term on the last entry. If the terms are the same, the longer log wins.
So, in our case, S3 cannot become a new leader since S2’s log is more up-to-date. Let’s assume that S3 was the first to start a new election for term 2, but it cannot become a leader for the reason mentioned above. We can establish a new leader only if S2 initiates an election. In our scenario, this occurs for term 3. Next, the client initiates the operation
Put(x, 5). After all processes are completed, the state should look like this:
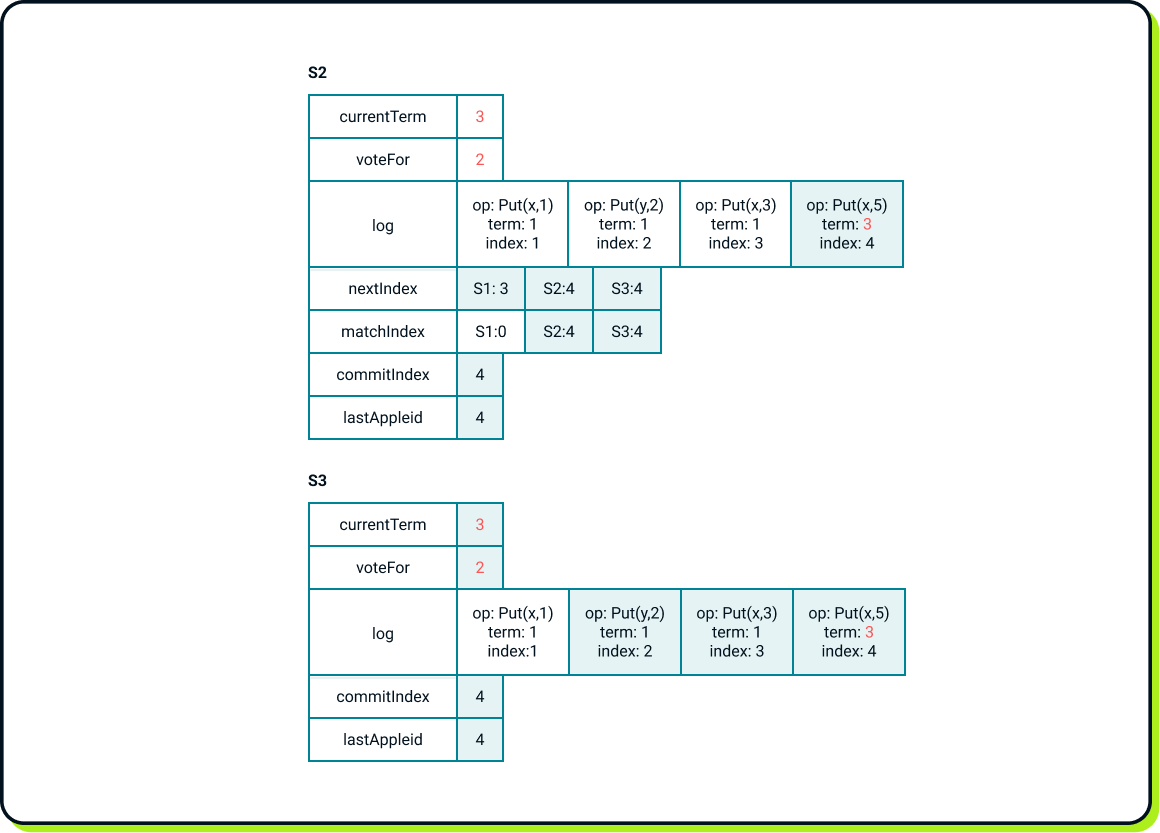
The value S1: 3 in the nextIndex table may seem a bit strange since S2's log has a length of 4. This occurs because whenever a new leader is elected, it initializes all entries in its nextIndex table to the length of its own log at the moment of obtaining leadership and updates the values whenever it receives acknowledgment that a certain number of log entries have been replicated on certain follower node, as happened in the case of S3. For S1 the nextIndex record stays S1:3, since S2 was not able to get any acknowledgment from S1, due to its failure.
To sum up, the system survived S1's failure without dropping any of the committed operations (Put(X, 4) was not committed) and it remains operational. Now, let’s consider whether we can survive any additional failures. The answer is no, because with only a single server remaining, we cannot form a majority. It is crucial to understand that "majority" refers to the total number of all Raft peers, not just those that are currently available.
The general rule is that a Raft-based system consisting of 2n+1 servers can survive up to n failures, ensuring that there is always a majority of n+1 servers. The committed operations are guaranteed to survive because at least one server from the previous majority will be part of the next majority, and those servers from the previous majority are only eligible to become a new leader due to the “up-to-date log” rule.
Persistence & log reconciliation
Now, let’s return to our setup and see what happens when S1 comes back; e.g. after a series of restarts. Only the persistent variables have survived, while the commitIndex and lastApplied have been initialized to 0 (S3 has been omitted for simplicity).
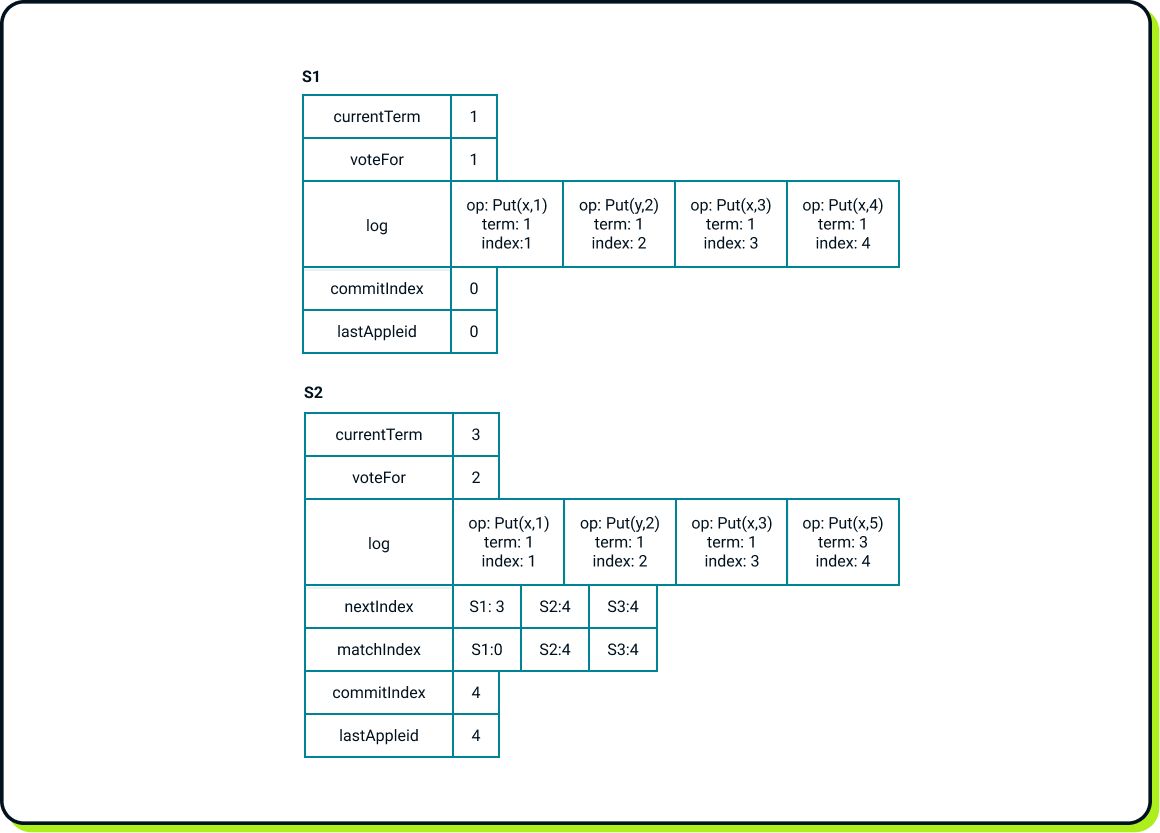
We can observe conflicting logs between S1 and S2. In such situations, the leader's log is always the source of truth. Thus, after noticing S2’s messages, S1 will update its term to 3 and voteFor to 2. S1 will replace its log entry at index 4 with S2’s entry at index 4. Only after the logs are reconciled, will S1 increase the commitIndex from 0 to 4. Then, S1 will apply all those operations to its state machine and finally update lastApplied to 4. This will result in the following state:
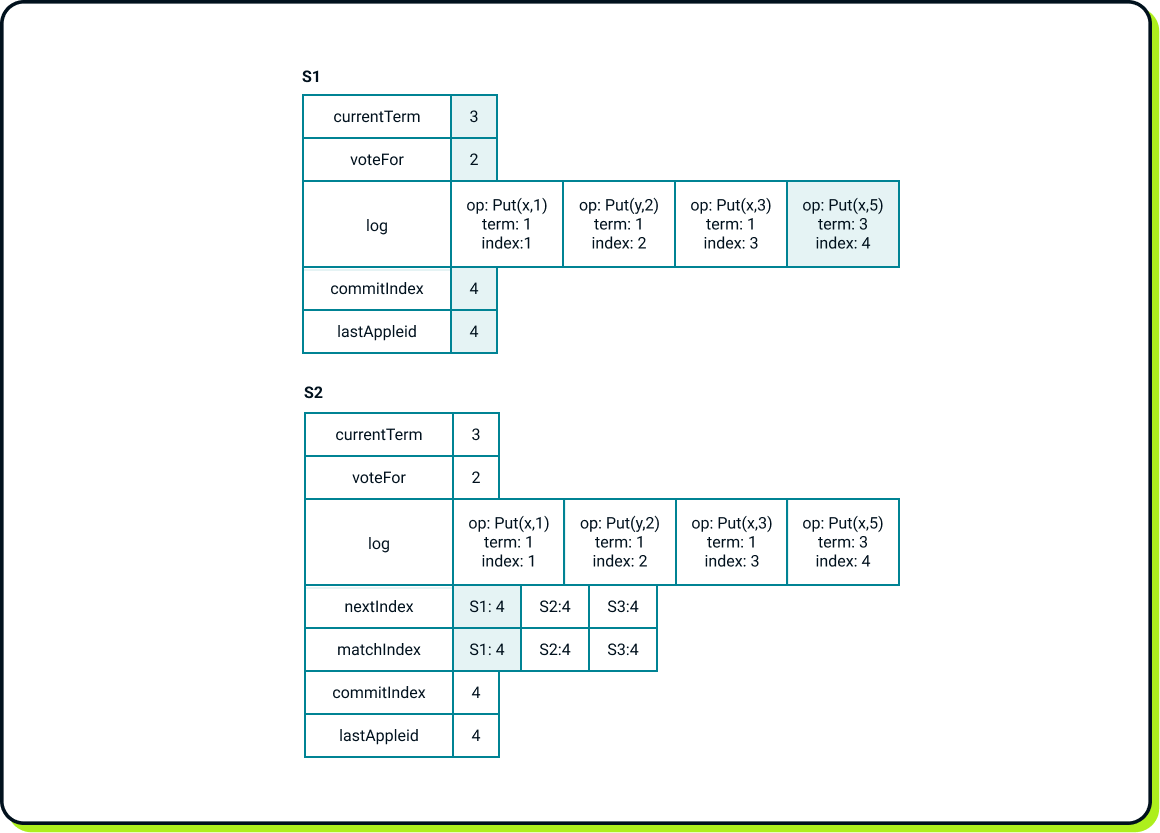
Firstly, we altered the follower's log, by erasing Put(X, 4) and replacing it with Put(X, 5) operation. This is allowed since the altered entry was not committed; hence, it was never executed against the state machine. It’s also worth considering the perspective of the client that issued the Put(X, 4) operation. In this case, it will not receive any acknowledgment. However, this is not always the outcome. In more complex cases, such as a five-server cluster, an entry could have been replicated on only two servers: the current leader and a single follower. If that follower is later elected as the new leader, the entry could eventually become committed. So, much depends on the implementation of the application built on top of Raft and how it solves such situations; e.g. how long it waits for confirmation from the Raft layer before claiming failure
Secondly, S1 re-executed the first three operations from its log that were executed previously when S1 was the leader. Such re-executions could potentially interfere with the state machine if it has its own persistent state. To mitigate this, operations can have attached IDs (such as sequential numbers) so that the state machine’s code can recognize whether a particular operation was executed before, thereby preserving state integrity.
Alternatives
Paraphrasing the Raft authors, Raft was designed as an “easier to understand and implement” alternative to another consensus algorithm called Paxos. Both algorithms assume the existence of a state machine to be replicated across servers. However, the main difference is that Raft relies on a strong leader, which only changes in response to events like leader failure or network partition (relatively rare events). In contrast, in the basic implementation of Paxos, nodes vote on every value (decision), which can lead to a higher overhead from the consensus layer.
Takeaways
For me personally, as a software engineer, the biggest takeaway from looking closely at Raft is an increased awareness of the problems that can occur in any distributed system, such as sudden server or network failures. So, when I am issuing a call in the code, let’s say to another service, I think more about the consequences if this call fails, mainly whether I leave the system in a consistent state in such cases. Another issue worth mentioning is the reordering of asynchronous network calls in the microservices environment. This refers to the fact that we cannot assume a network call initiated earlier will be processed before another call made afterward.
Finally, I want to drop a few links. Firstly, the Raft white paper ![]() which was my guide in my Raft journey. Secondly, the open-source implementations: etcd-io/raft
which was my guide in my Raft journey. Secondly, the open-source implementations: etcd-io/raft ![]() and hashicorp/raft
and hashicorp/raft ![]() used under the hood respectively by etcd
used under the hood respectively by etcd ![]() and consul
and consul ![]() .
.


