


As data continues to grow in both size and complexity, it is becoming increasingly difficult for organizations to extract valuable insights from it. This is where data wrangling comes in.
Data wrangling, which is also known as data munging or data cleaning, is the process of gathering, cleaning, transforming, and preparing unprocessed data into a format that is more easily understood and analyzed. Data wrangling enables organizations to leverage the full potential of their data.
In this article, we delve into data wrangling, exploring what it is, why it is important and the key tasks involved in the process. We also discuss some of the challenges and the best practices associated with data wrangling, as well as the tools and technologies that can be used to streamline the process. Whether you are a data analyst, a data scientist, or simply someone interested in the power of data, this article provides a comprehensive overview of data wrangling and its role in the data analysis process.
What is data wrangling?
As mentioned, data wrangling is the process of taking raw data and cleaning it up so that it can be more easily understood and analyzed. This raw data can come in various forms. During the data wrangling process, different tasks are carried out to prepare the data for analysis, such as data cleaning, data integration, data transformation, data normalization, and data enrichment. Data wrangling can be accomplished manually or through automation. When dealing with a vast amount of data, an automated process is often necessary. Below are some examples of data wrangling:
- consolidating multiple data sources into a single data set to facilitate analysis;
- identifying and addressing extreme outliers in the data set, either by providing explanations for the discrepancies or removing them to enable analysis;
- eliminating data that is redundant, such as duplicate entries, or not applicable to the project being worked on;
- analysis identifying data gaps such as empty cells, either by filling them in or deleting them.
Data wrangling can be a part of both data science and data analytics. You can read about the difference between these two terms on our blog.
>> Discover our data science services.
Why is data wrangling important?
Data wrangling is crucial because it ensures the reliability and accuracy of data that is used for analysis. In data-driven companies, data often comes from multiple sources and may have inconsistencies that could impact further analysis. By cleaning and transforming raw data, more accurate insights can be obtained.
Data wrangling also improves efficiency. Raw data is often messy and difficult to understand. By standardizing and organizing the data, data wrangling streamlines the analysis process and saves time.
Without a proper data wrangling process, it may be difficult or even impossible to analyze data. Data wrangling converts raw data into a desired format that can be easily analyzed, providing insights that might have otherwise gone unnoticed.
The insights gained from analyzing data can help inform better decision-making. By preparing data through data wrangling, organizations can make better decisions based on accurate and reliable data. This is why we provide professional data engineering services.

The data wrangling process
Data wrangling procedures involve several steps that can be followed to transform and clean raw data. The exact procedures followed can vary depending on the specific data and the goals of the analysis, however, there are some common steps involved in data wrangling.
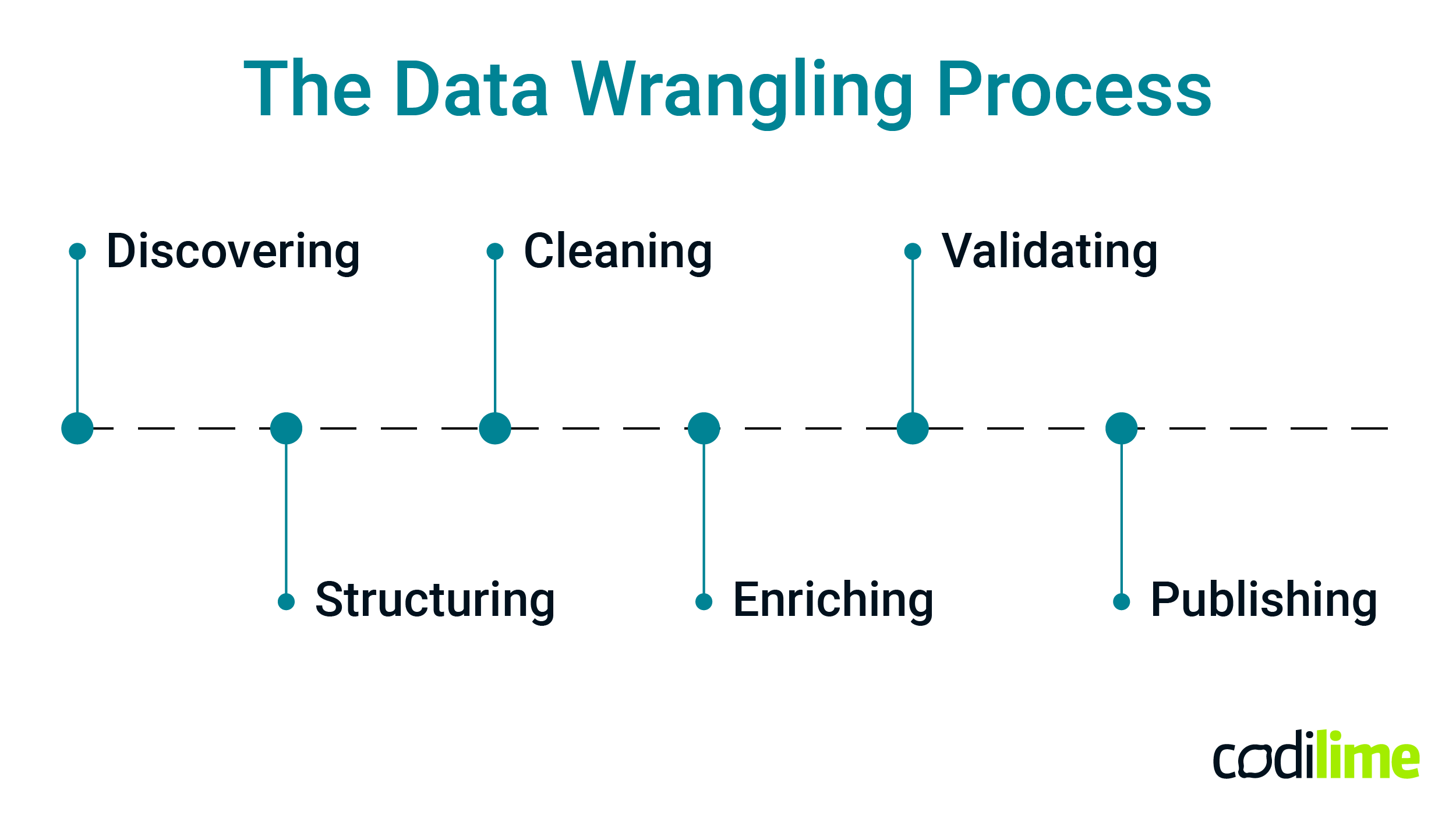
Discovering
This is the initial step in data wrangling. Discovering involves systematically examining the data and identifying criteria for dividing it into meaningful segments. Through this step, the relevant characteristics of the data are identified to inform the following wrangling procedures.
Structuring
Raw data is often incomplete or not formatted appropriately for its intended use, making it difficult to analyze. Data structuring is an important step in data wrangling, as it involves organizing and formatting the data in a way that facilitates analysis. The specific format of the data will depend on the analytical model used to interpret it. This could also be called data normalization.
Cleaning
The cleaning step involves thoroughly reviewing the data and removing any outliers or errors to ensure the high quality of further analysis. This includes inputting any missing values and standardizing the formatting to create a more consistent and reliable database. Ultimately, the goal of cleaning the data is to ensure that the quality of the data set is the highest possible for more accurate and insightful analysis.
Enriching
Once the data has been initially processed and cleaned, the next step in the data wrangling process is often to enrich it. This covers taking a closer look at the data and strategizing about how it can be improved or perhaps augmented through various techniques - for example upscaling, downsampling, or data augmentation. The choice of technique depends on a deep understanding of the data and its subsequent use.
Validating
Validating is also a very important step of data wrangling. Verifying the consistency and quality of the data after it has been processed and cleaned includes checking for accuracy in the data fields or ensuring that attributes are distributed normally. Through iterative programming steps, data validation helps to confirm that the data is consistent and reliable, and further analyses can be conducted with greater confidence.
Publishing
The final stage of data wrangling is publishing. This is simply the process of making the data available for use by others, including data analysts, data scientists, business analysts, and business users, typically for further analysis or decision-making. The key is to ensure that the data is accessible and usable by others who may need to work with it in the future.
Data wrangling tools
Data wrangling involves a variety of tools and technologies to streamline the process. Below are some of the most frequently used ones.
- Microsoft Excel
Excel is a widely used spreadsheet program that can be used to clean, manipulate and transform data.
- Python
Python is a commonly used programming language for data wrangling. Its libraries, including pandas and NumPy, offer robust data manipulation functionalities.
- R
R is another widely used programming language. It has a variety of libraries, including dplyr and tidyr, that provide numerous data manipulation functions.
- SQL
Structured Query Language is a widely used language for managing and querying relational databases. It is commonly used to extract, filter and transform data.
- OpenRefine
This is a powerful, open-source tool for cleaning and transforming raw data. It can handle large data sets and supports a variety of data formats.
- Apache Spark
This is a distributed computing framework used for processing big data. It includes several libraries, such as Spark SQL and Spark DataFrames, that provide data wrangling capabilities.
- Talend
Talend is a data integration tool that includes features for transforming, cleansing, and mapping data.
There is a wide variety of data wrangling tools and technologies available, and the selection of a particular tool depends on the specific needs of the project and the data being processed.
Best practices for data wrangling
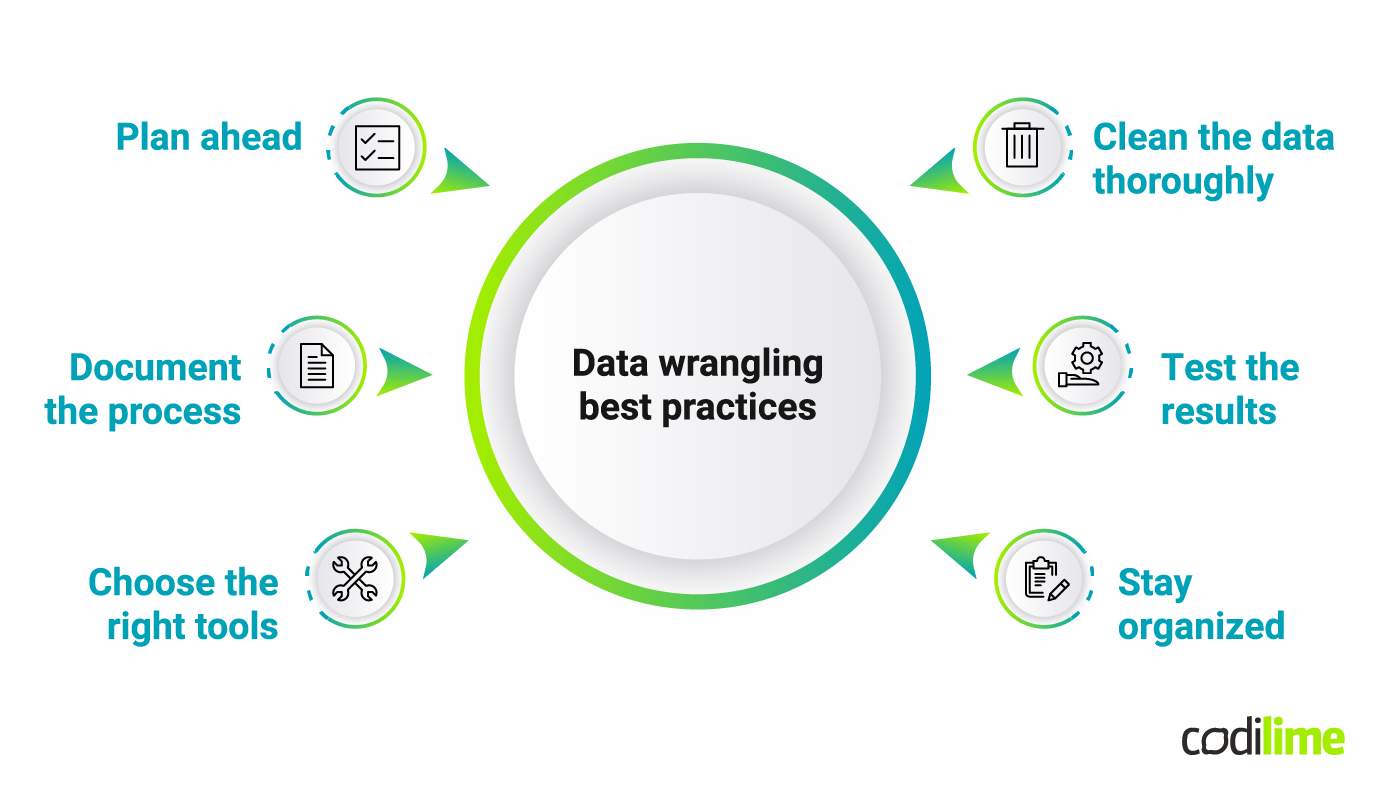
To ensure that the final output of a wrangling process is accurate and useful, some best practices should be followed. These practices involve planning ahead. Before diving into data wrangling, take the time to plan your approach. This should include identifying your objectives, defining data sources, and setting up a workflow that can help achieve the goals efficiently.
Another good practice is to document the whole process. Keep detailed notes about the steps taken during data wrangling, including any assumptions, decisions, and changes made. Such documentation can help repeat the process in the future or, what is even more helpful, troubleshoot in case of any arising issues.
As mentioned already, there are many software tools available for data wrangling, such as Python and R programming languages, as well as specialized tools like OpenRefine and Trifacta. Choosing the right tools for specific data and workflow needs should be a thought-through business decision to avoid future inconvenience.
Another best practice to mention is to clean the data thoroughly. Ensuring that null values are handled appropriately, identifying outliers, and standardizing the data formatting.
Testing the results would be another good practice to follow. This process is to ensure that the output meets the predefined objectives. Using statistical tests or data visualization tools can be very helpful to check that the data is suitable for the intended use.
Lastly, staying organized by using consistent naming conventions, version control, and backup procedures to ensure data security and accessibility.
Adhering to these best practices can enhance the efficiency, accuracy, and quality of the data wrangling.
Conclusion
Data wrangling is a significant step in the data analysis process that ensures the accuracy, reliability, and ease of analysis of data, ultimately leading to better decision-making. Although data wrangling can be a daunting and time-consuming task, it can be simplified using the right tools, techniques, and processes, thereby enhancing the efficiency and effectiveness of data analysis efforts, which is especially important in the era of big data.
The importance of data wrangling will only increase as data continues to grow and companies collect more and more complex data. It helps organizations to derive extremely valuable insights from their data. By investing in data wrangling capabilities and acquiring the latest technologies and best practices, companies can stay ahead of the market and gain a competitive advantage in today's data-driven world.


