


This story describes the process of coming up with a solution for maintaining the consistency of business-level operations after more and more parts of once almost monolithic applications are being carved out to form a Kubernetes-based microservices environment.
It stems from working on an orchestration platform, the beginnings of which I described in an article about migrating our application to microservices. But the problems we encountered, the possibilities for solving them, the considerations and analyses in computer science theory, best industry practices, as well as the arguments we were bound to, are all common to a whole host of services operating in distributed systems.
In order not to get bogged down in a world of under-described problems, vague stories, nebulous statements, or even pure theory, I will rely on examples written in concrete Python code. The following are not excerpts from the projects we are working on, but something written completely from scratch, and hosted in our GitHub repository ![]() , to make this article more down-to-earth. The intention of publishing the code was only to illustrate the issues raised in this article, and it should not be used as a model for writing serious applications.
, to make this article more down-to-earth. The intention of publishing the code was only to illustrate the issues raised in this article, and it should not be used as a model for writing serious applications.
Atomic operations
Consider the following snippet, which handles a hypothetical delivery process:
@router.post(
"/",
status_code=status.HTTP_201_CREATED,
response_model=models.WarehouseResponse,
)
async def create(
warehouse_repository: dependencies.WarehouseRepository,
stock_position_repository: dependencies.StockPositionRepository,
session: dependencies.DBSession,
delivery: models.Delivery,
) -> models.WarehouseResponse:
warehouse_repository.use_session(session)
stock_position_repository.use_session(session)
try:
warehouse = warehouse_repository.find_by_id(delivery.warehouse_id)
for position in delivery.positions:
if warehouse.capacity < position.quantity:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="delivery cannot be processed because "
"it exceeds current warehouse capacity",
)
try:
stock = stock_position_repository.find_by_warehouse_id_and_material_id(
warehouse_id=warehouse.id,
material_id=position.material_id,
)
stock.quantity += position.quantity
stock_position_repository.update(stock)
except RepositoryException:
stock = models.StockPosition(
warehouse_id=warehouse.id,
material_id=position.material_id,
quantity=position.quantity,
)
stock_position_repository.create(stock)
session.commit()
return models.WarehouseResponse.model_validate(warehouse, from_attributes=True)
except Exception:
session.rollback()
raise
This code is an implementation of a FastAPI ![]() endpoint that handles the delivery of materials to a warehouse. Notice also how in this request handler, an SQLAlchemy database session
endpoint that handles the delivery of materials to a warehouse. Notice also how in this request handler, an SQLAlchemy database session ![]() is added as one of the dependencies of the function. It is important, especially once we look into the implementation details of both repositories. Here are the subsequent snippets, outlining the two functions of the repositories (the other repositories’ methods are very similar):
is added as one of the dependencies of the function. It is important, especially once we look into the implementation details of both repositories. Here are the subsequent snippets, outlining the two functions of the repositories (the other repositories’ methods are very similar):
def find_by_id(self, id: uuid.UUID) -> Model:
if self._session is None:
raise RepositoryException("database session not initialized")
if self._model is None or not hasattr(self._model, "id"):
raise RepositoryException(f"{self._model_name} has not got an 'id' attribute.")
try:
return self._session.exec(select(self._model).where(self._model.id == id)).one()
except NoResultFound as exc:
raise RepositoryException(f"{self._model_name} not found") from exc
def create(self, record: Model) -> Model:
if self._session is None:
raise RepositoryException("database session not initialized")
self._session.add(record)
self._session.flush()
return record
What is immediately noticeable is that the single database session is used for every operation across both repositories. In the case of SQLAlchemy, sessions basically correspond to database transactions ![]() . From a consistency of operations point of view, this is a key point. This is due to the fact that several database operations need to be performed within a single logical business operation. First, warehouse information must be retrieved, and then, for each delivery position, if the warehouse capacity is still sufficient, an existing stock entry is updated or a new one is created. When all these steps go flawlessly, the session is committed, and information about the warehouse to which the material has been delivered is sent in response. On the other hand, if an error occurs at any stage of the process, the whole session is rolled back, and the response is an error message. This characteristic of an operation is called atomicity
. From a consistency of operations point of view, this is a key point. This is due to the fact that several database operations need to be performed within a single logical business operation. First, warehouse information must be retrieved, and then, for each delivery position, if the warehouse capacity is still sufficient, an existing stock entry is updated or a new one is created. When all these steps go flawlessly, the session is committed, and information about the warehouse to which the material has been delivered is sent in response. On the other hand, if an error occurs at any stage of the process, the whole session is rolled back, and the response is an error message. This characteristic of an operation is called atomicity ![]() .
.
| An atomic operation is a type of operation that executes as a single, indivisible unit without interruption. This means it either completes fully or does not happen at all, with no intermediate states visible to other threads or processes during its execution |
|---|
Thus, in the case of a system built as a monolith using a single database, the atomicity of business operations, and therefore also the coherence of the system, is ensured by a correctly implemented database layer.
What changes once we move (parts of the system) to microservices
When we change an application (or build it from scratch) to run in a microservices architecture, we lose the ability to leverage individual database sessions (transactions). Now, there are several possible architectures for splitting the database across services (more on this in the previous article “Why are we rewriting our solution to microservices?”), but common to all of them is the impossibility of using the same database session across different microservices. In the accompanying codebase, every service (e.g., warehouse or stock_position) is built with a separate database, and of course uses separate (non-shared) sessions for its database.
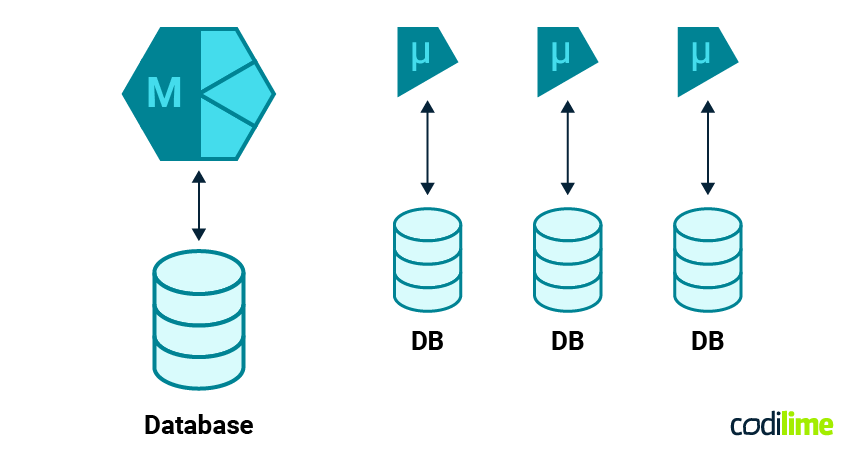
| Architectural changes describing the transition from monolithic to distributed microservice architecture are described in more detail in an article about migrating our application to microservices. |
|---|
Database calls performed within a single transaction will be replaced by requests to one of the remote services, using an API technology of one kind or another (REST, gRPC, GraphQL, etc.). Now, repositories’ methods will look more like this:
async def find_by_id(self, id: uuid.UUID) -> Model:
if self._model is None or not hasattr(self._model, "id"):
raise RepositoryException(f"{self._model_name} has not got an 'id' attribute.")
async with httpx.AsyncClient() as client:
resp = await client.get(
f"{self._base_url}/{self._model_path}/{id}",
headers=self._headers,
)
resp.raise_for_status()
return Model.model_validate(resp.json())
async def create(self, record: Model) -> Model:
async with httpx.AsyncClient() as client:
resp = await client.post(
f"{self._base_url}/{self._model_path}",
headers=self._headers,
json=record.model_dump(),
)
resp.raise_for_status()
return Model.model_validate(resp.json())
The database session is gone and no longer relevant in the context of business operations, and with it, the enforcement of transaction atomicity. A new challenge therefore arises, and that is one of ensuring the consistency of operations in a distributed microservices application environment. The delivery operation (or any other business process for that matter) still needs to remain an atomic one, but a new mechanism is needed to enable this.
About (not) reinventing the wheel
Fortunately, maintaining the consistency of operations in applications running on distributed systems is not an entirely new issue, and a lot of thought has already been given to this topic. This is not surprising when you note that vertical scaling encounters physical and budgetary constraints much more quickly than horizontal scaling. Thus, runtime environments consisting of multiple cooperating components were already being built more than 40 years ago, some of which began to be used to run database-based OLTP ![]() applications, which of course had to retain ACID
applications, which of course had to retain ACID ![]() features. As is often the case, vendors developing their custom solutions came together at some point in a consortium that proposed the “X/Open Distributed Transaction Processing Model”
features. As is often the case, vendors developing their custom solutions came together at some point in a consortium that proposed the “X/Open Distributed Transaction Processing Model” ![]() specification, which became the de facto standard just over 30 years ago. The X/Open XA standard was based on the previously devised two-phase commit protocol (2PC)
specification, which became the de facto standard just over 30 years ago. The X/Open XA standard was based on the previously devised two-phase commit protocol (2PC) ![]() .
.
| Vertical scaling is a method of increasing the performance and capacity of an IT system by adding resources to a single server or component. This means that instead of expanding the infrastructure by adding more servers (as in horizontal scaling), the computing power of an existing machine is increased, for example, by adding more RAM, processors, or disk space. |
|---|
| Horizontal scaling is a method of increasing the performance and capacity of an IT system by adding new units, such as servers or instances, to the existing infrastructure. Rather than expanding a single server (as in vertical scaling), horizontal scaling involves increasing the number of servers that collectively handle the growing load on the system. |
|---|
| OLTP (Online Transaction Processing) is a data processing system that enables a large number of short, simple transactions to be performed quickly and efficiently in real time. Examples of such transactions are banking operations, retail sales, order placement, or the recording of events in information systems. |
|---|
| ACID properties are a set of four key features that guarantee correct and reliable processing of transactions in databases. The acronym ACID is derived from the English words: Atomicity, Consistency, Isolation, and Durability. |
|---|
Two-Phase Commit Protocol
The protocol consists of two steps for each operation. During the preparatory phase, a coordinator service asks all participants if they can commit. During the commit phase, if all participants agree, the coordinator instructs the participants to finalise the operation, otherwise it aborts the transaction. The role of the coordinator service, as can be seen, is crucial throughout the process.
C - coordinator; P0, P1 - participants
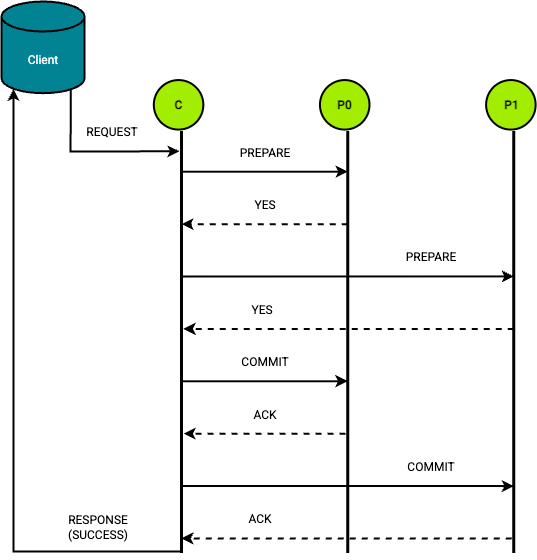
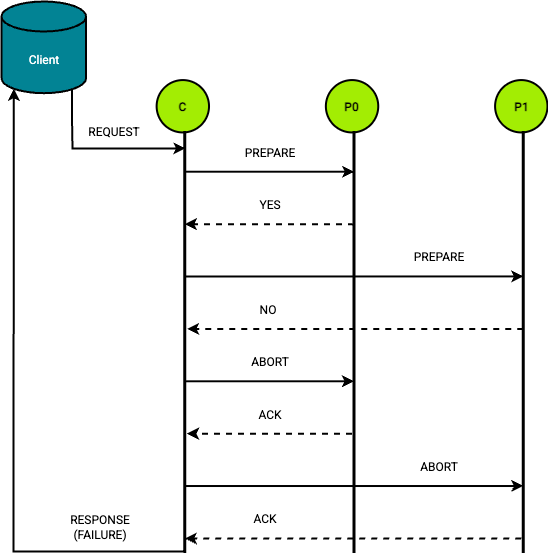
The advantages of this protocol include:
- Data consistency and atomicity: 2PC ensures that either all participants validate a transaction or all participants abort it, preventing data inconsistency.
- Simplicity and transparency: The protocol's design is simple and easy to understand, making it relatively easy to implement.
- Widespread adoption: Many database management systems natively support 2PC, allowing developers to use existing transaction management tools.
- Reliability in failure scenarios: The Two-Phase Commit Protocol can handle multiple temporary failures with logging and recovery mechanisms, ensuring transaction integrity even if some nodes or communication links fail.
- Compliance and auditability: With a single “source of truth”, it is possible to reliably maintain a consistent state and audit trail, which is essential in regulated industries such as banking and e-commerce.
But as every rose has its thorns, so does the Two-Phase Commit Protocol:
- Blocking nature: if the coordinator fails after participants have voted “yes”, those participants remain blocked, waiting indefinitely for the coordinator's decision.
- Single point of failure: failure of the coordinator can cause the entire transaction to become stalled until manual intervention.
- Performance impact: The protocol involves multiple rounds of communication and locks up resources during a transaction, which increases latency and reduces system throughput.
- Scalability challenges: As the number of participants increases, communication overhead and coordination complexity also increase, making 2PC less suitable for very large distributed systems.
Because of some limitations of the Two-Phase Commit Protocol, especially once runtime environments started to grow bigger and bigger, a new approach had to be adopted, one that would overcome the shortcomings of the 2PC.
The SAGA Pattern
It very quickly became apparent that the blocking nature of the 2PC made it very difficult, if not impossible, to use it to handle LLTs (long-lived transactions). Addressing this problem, in January 1987, Hector Garcia-Molina and Kenneth Salem of Princeton University's Department of Computer Science published the paper titled “SAGAS” ![]() . In the article (which, by the way, summarises research conducted with the support of DARPA), the authors propose a solution of breaking up long-lived transactions into a series of shorter ones (Ti), each having a complementary compensating operation (Ci). What is important is the assumption that a compensating transaction does not necessarily restore the system to its exact state before the transaction, but to a state that is identical in terms of business logic.
. In the article (which, by the way, summarises research conducted with the support of DARPA), the authors propose a solution of breaking up long-lived transactions into a series of shorter ones (Ti), each having a complementary compensating operation (Ci). What is important is the assumption that a compensating transaction does not necessarily restore the system to its exact state before the transaction, but to a state that is identical in terms of business logic.
Ti - transactions; Ci - compensating transactions



This approach proved to be an excellent fit for the distributed microservices architecture that has emerged some 30 years later. The Saga Pattern provides a clean way to handle large tasks that involve a number of different services working together, especially when each service has its own database. Once an individual service completes handling a transaction, it publishes an event or message to trigger the next transaction in the sequence.
The key characteristics of the SAGA Pattern include:
-
Transaction locality: Each step is a local transaction that atomically updates the database of a single service.
-
Event-driven coordination: The completion of one transaction triggers the next transaction via events or messages.
-
Compensation transactions: If a transaction fails, compensating transactions are executed to undo the effects of previous successful transactions, ensuring final consistency (Image 4)
-
Two styles of coordination:
- Choreography, where services communicate directly by publishing and consuming events without a central coordinator. [fig 6 below]
- Orchestration, where a central coordinator (Saga Execution Coordinator) manages the sequence of transactions and compensation. [fig 7 below]
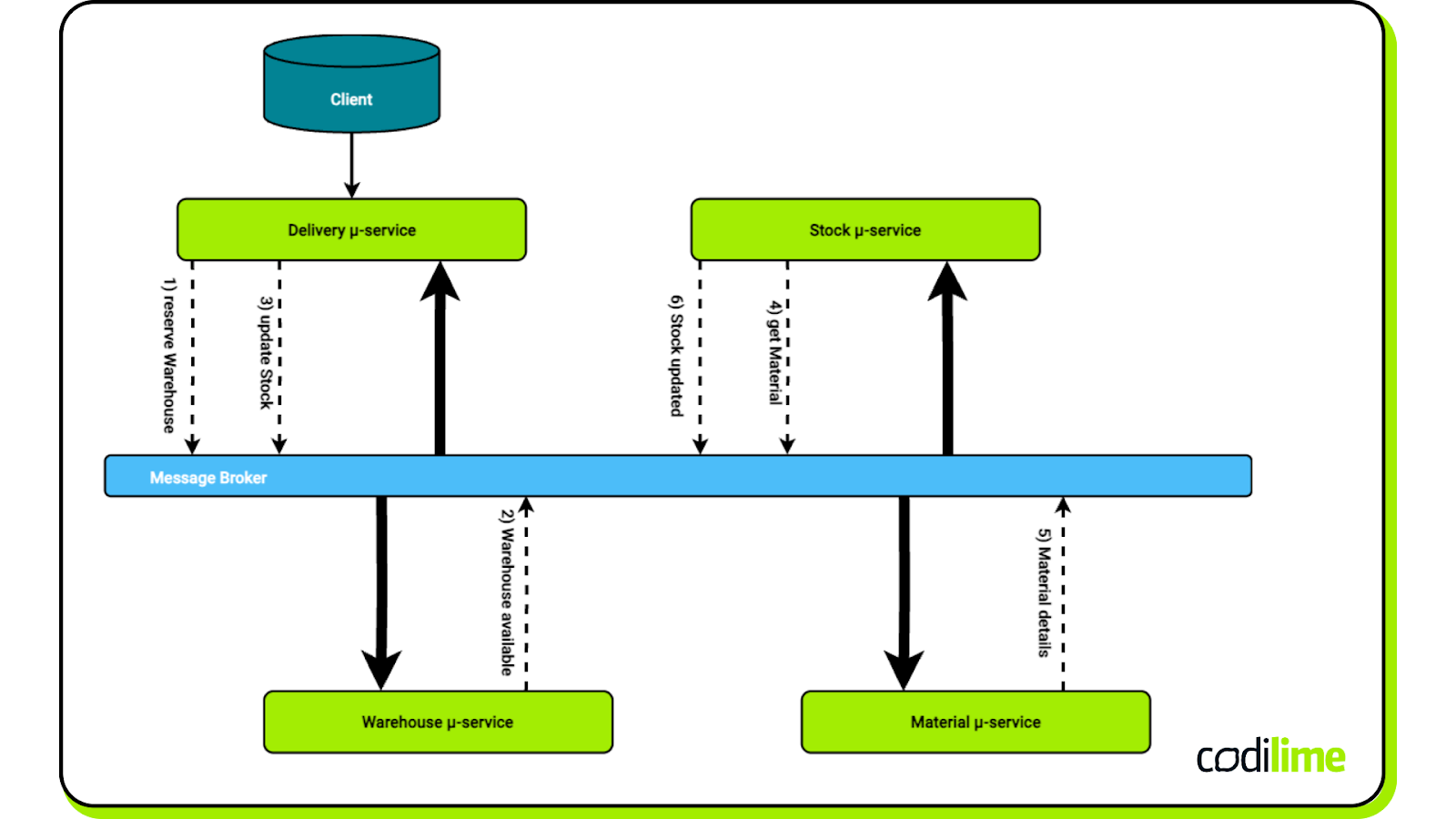
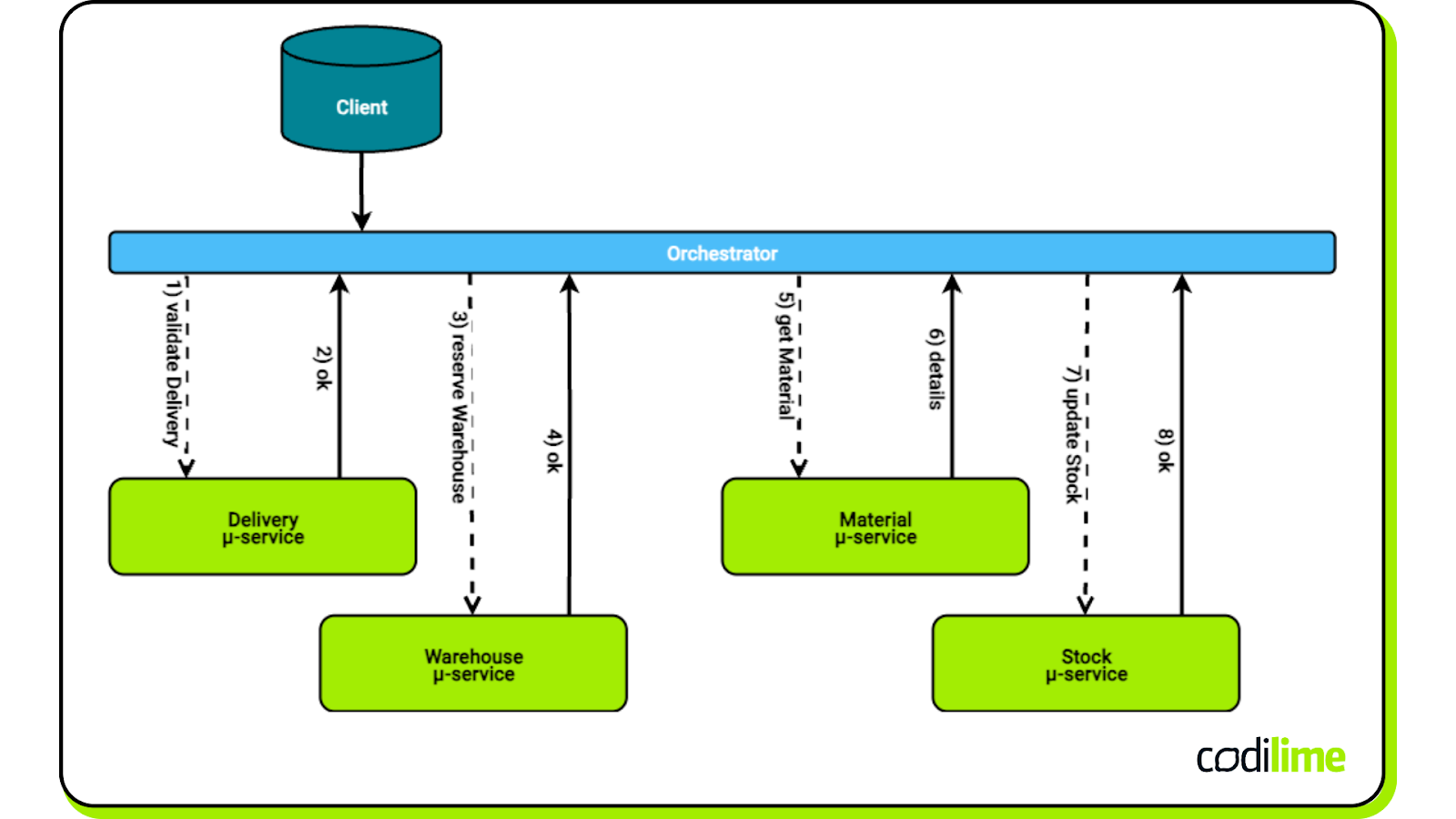
Conclusions
The design and implementation of applications running on distributed systems present new challenges that engineers working on monolithic applications do not face. Typically, most of the difficulties arise from the need to find a new solution, other than database transactions, to ensure the consistency of operations.
In an actual project where we encountered the problems described here, the fundamental challenge proved to be ensuring the atomicity of operations. In this article, I have focused on describing this difficulty and presenting the theoretical basis for its solutions.
There are other practice patterns used in distributed systems. Among these, it is still worth mentioning the methods often referred to collectively as “Eventual Consistency and Asynchronous Methods”. That means acting so that when data is updated on one node or in one service, the update will be propagated asynchronously to other nodes/services, and after some time, all nodes will reflect the same data state. This allows for temporary inconsistencies, but guarantees that if no new updates occur, all elements of the system will eventually converge to the same value.
Eventual consistency is, however, a style of operation that does not very strongly emphasise the consistency of the system (hence “eventual”) and the atomicity of the operations, so those methods are not strictly related to the topic of this article. The CAP theorem subject ![]() is quite interesting, though, and worth exploring on your own. As a matter of fact, we already have another publication on the subject - A closer look at Raft internals – leader election and log replication on our blog.
is quite interesting, though, and worth exploring on your own. As a matter of fact, we already have another publication on the subject - A closer look at Raft internals – leader election and log replication on our blog.


