


Increasing demands on computer hardware means higher demand for network technology. Unfortunately, computer systems remain largely inefficient, with the CPU serving as the key engine in a variety of computer applications. To solve this problem, one could take various approaches: use a bigger computer, distribute the software between different computers, or improve its performance.
In this article, we'll show you how a higher-end computing device can reduce CPU usage and the costs associated with hardware. This process is called hardware offloading.
What is hardware offloading?
Hardware offloading refers to the process of moving certain tasks or computations from a computer's main processor (CPU) to dedicated hardware components, such as network interface cards (NICs) or graphics processing units (GPUs), in order to improve system performance and efficiency. This can be done in various ways, using different techniques and devices. This article is focused on the case of hardware offloading in software-defined networks.
Moreover, here you can read about hardware software as a service.
What are software-defined networks?
With the growing number of devices and the packet volume that is processed in computer networks, we need a new way to manage the computer networks that we use, for example in data centers. The popular solution is to move from a single device, which combines specialized hardware with the control plane and provides selected features, to three distinct layers.
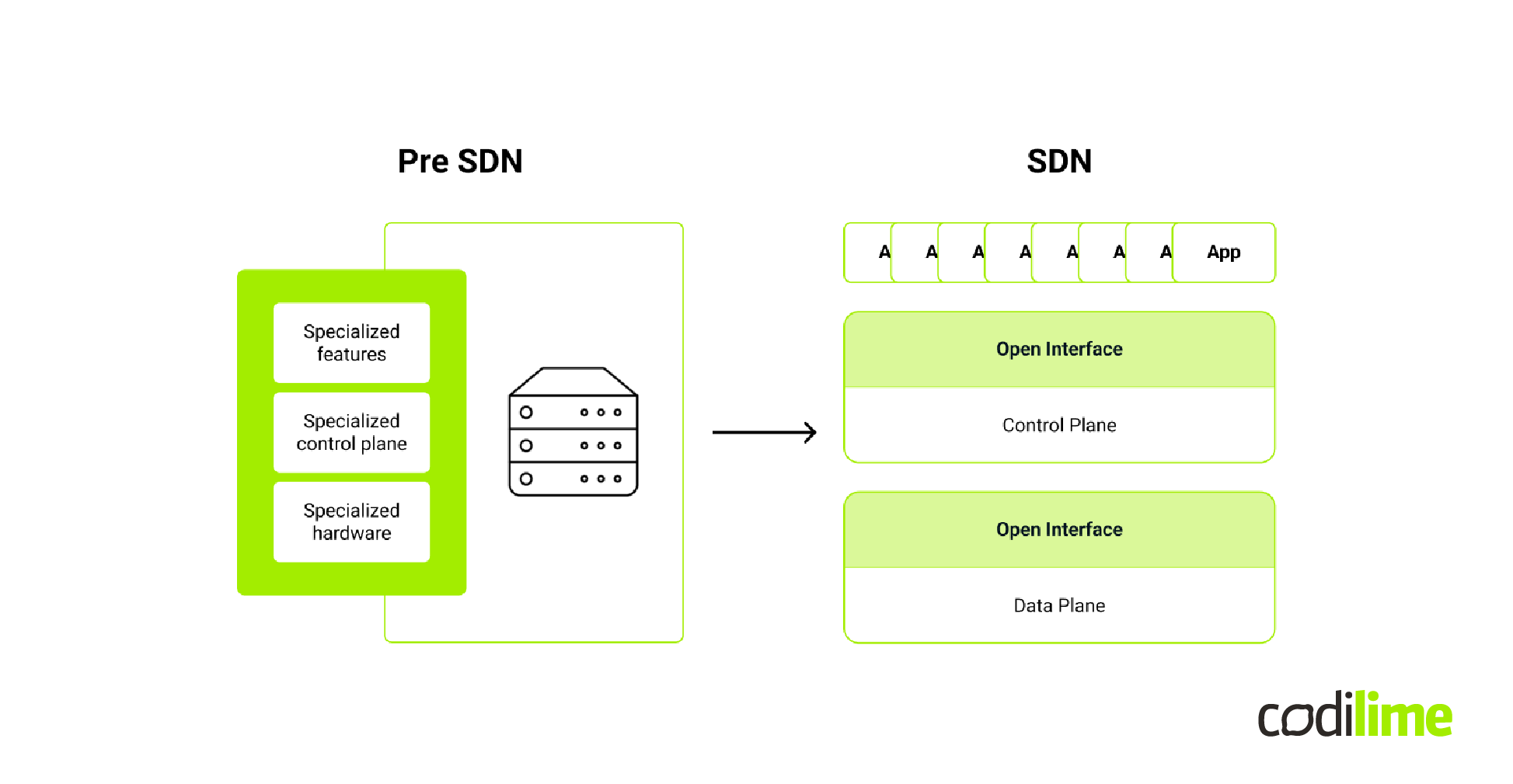
The first layer is the management layer or management plane. This is where applications such as OpenStack are located. It’s possible to apply some configuration to our network and utilize it in, for example, virtualization. The next layer is the control plane. This realizes the features used by the management API. And beneath that is the data plane. It consists of both hardware (e.g. whitebox switches) and software - the software data plane. This layer, the data plane, is where the hardware offloading happens.
The software data plane is a general term used to describe applications that process networking packets with user data. This means both forwarding applications like virtual switches, and more specialized applications, for example firewalls that could be deployed as a VNF. In the most common use cases, the software data plane enables SDN to provide network virtualization and distribute packets to VMs running on a virtualization host.
You can read a more thorough description of SDNs and their benefits in our gentle introduction to software-defined networking.
The challenge of software-defined networks
The software data plane runs packet forwarding and processing in software, which means a generic CPU running on a virtualization host. Although this can distribute packets to different VMs, it comes with a certain cost.
Packet forwarding in software can turn out to be not efficient enough, both in terms of latency and in packet throughput. It’s also necessary to allocate resources from the host operating system to actually run the forwarding data plane. CPU resources, like time and memory, are needed, and performance reliability can be challenging - certain packet traffic characteristics or high workloads can impact software data plane performance. In the next section, we demonstrate how hardware offloading can be used to circumvent these issues.
How can hardware offloading help?
There are some purely software techniques or approaches to mitigate these issues. Instead of relying on interrupts to acquire packets, we can use hardware polling on network devices. Instead of copying memory or packets between user space and kernel space, we can use a direct memory access technique. However, this often results in a need to dedicate more resources.
The high costs of running a software data plane suggest that using hardware might be a better choice.
Hardware offloading in SDN
There are two kinds of hardware offloading: partial offloading and full offloading. In the first one, processing simple network tasks, like matching fields in packet headers or replacing some headers is delegated to the hardware, but the packet must still enter the software to be processed by some virtual switch and forwarded to the appropriate destination.
In full hardware offloading the responsibility for packet forwarding is delegated to the hardware. The hardware not only matches fields or replaces headers, but also forwards the packet to the proper port, which usually is a virtual function of the card.
There are pros and cons with both solutions. Partial hardware offloading has all the advantages of software switching because the packet still enters the software and is processed there, but we have much lower performance. In full offloading, the network performance is much better because hardware fully processes the packet, but we lose flexibility. For example, it is harder to migrate virtual machines because they are directly attached to the hardware.
Hardware offloading with NICs
In hardware offloading, the best solution to start with is a conventional NIC, also called a network interface card or a network interface controller. It's a popular device that you have probably already deployed in your software defined network. Most of the NICs available on the market enable hardware offloading, supporting such features as VLAN or VXLAN encapsulation and decapsulation or matching packets by their headers. This device is known to be cost and power efficient, and it's relatively fast. Another advantage is that the vendor provides reliable resources, which include documentation and support during the whole lifecycle of the device.
However, a network interface controller also has some disadvantages. The vendors choose not only the features, but also the API to use those features. So if the NIC doesn’t have the features you’re looking for, you might need another device.
The next step - SmartNICs
A SmartNIC can be a way to get around the limitations of a network interface card. A SmartNIC is similar to a NIC, but it has a programmable part added, usually a FPGA or ASIC. This addition makes it possible to program the FPGA on your own so you can just implement the missing feature.
Implementing features is not the only advantage. Since a FPGA is fully programmable hardware, you can implement even more complex programs, like an L3 router. That way, you can do all the routing in hardware. But even then there is one connection between software and hardware. In this L3 router example you still need a routing table and routing entries to be inserted into the card, and the software is still responsible for that.
Check out our previous article if you want to learn more about SmartNICs, their types, features, and how to use them.
IPU/DPU - the next generation of SmartNICs
To fully transition from software to hardware, you need another device. Enter the next evolution of SmartNICs, called IPU, DPU, or next gen SmartNICs. This is basically a SmartNIC with another CPU added on board.
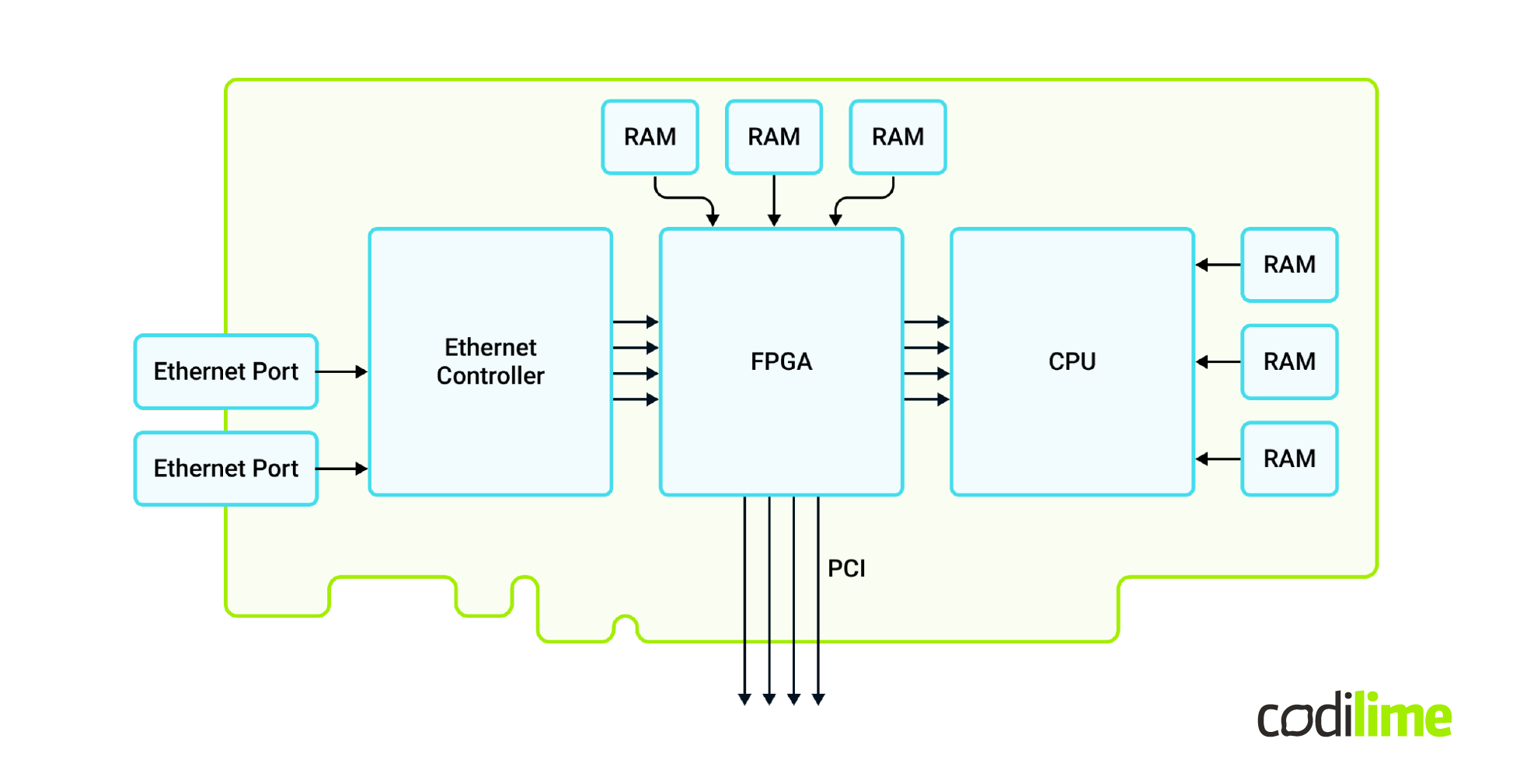
When you use this device, your hardware has its own CPU. You can even run a separate operating system on the card and run your software applications that are responsible for, for example, inserting rules in the router. That way you achieve a full separation from software and all resources on the host are available for workload.
Hardware offloading - real-life example
With that general overview of hardware offloading, let's consider a use case in software-defined networking. Our engineers developed a demo showcasing the possibilities of hardware offloading. The goal of this solution is VXLAN tunneling offloaded in OpenvSwitch.
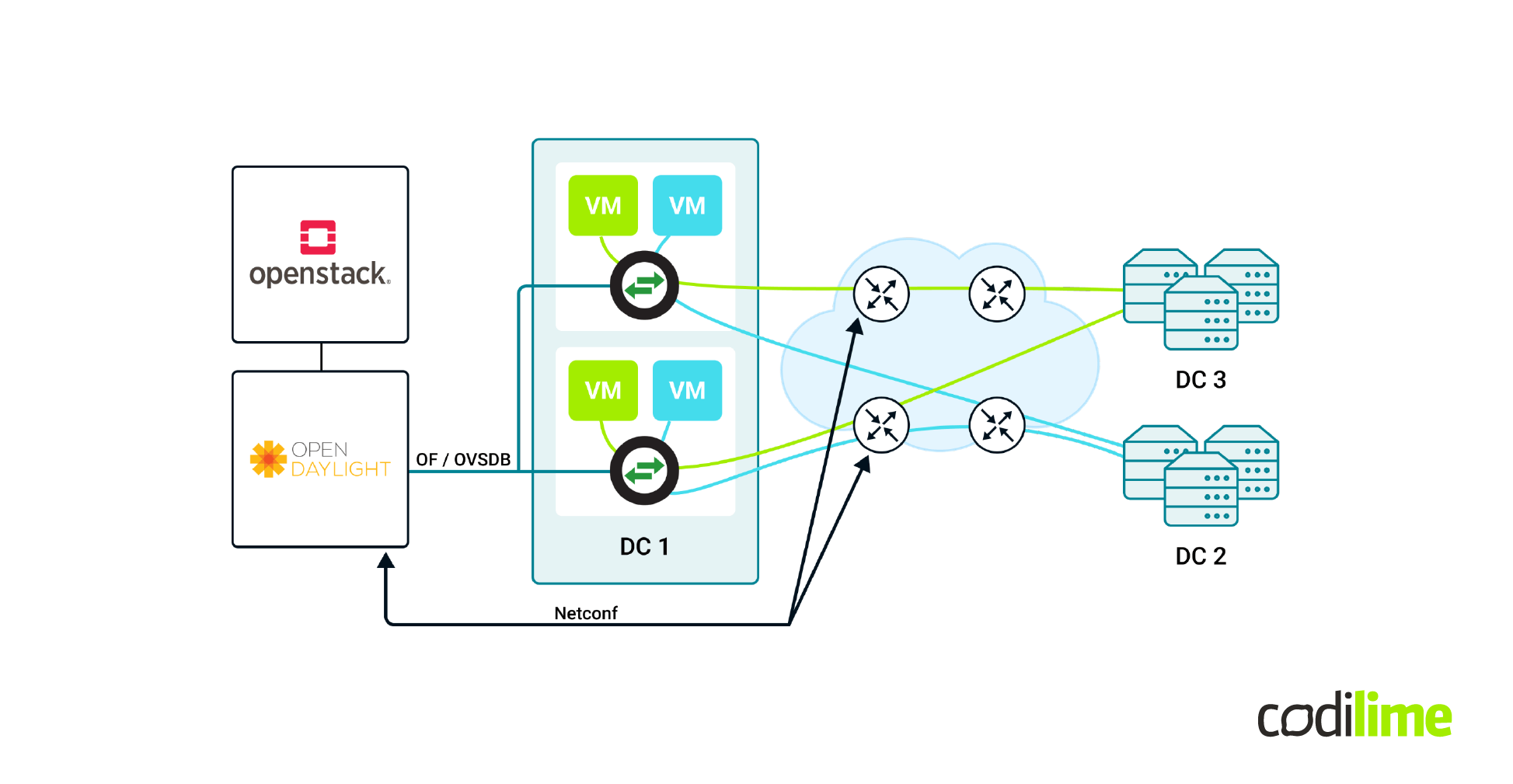
In this diagram, there is a rather complicated software-defined networking environment where we have OpenStack as virtualization orchestrator. We have OpenDaylight as a control plane, and it manages both Open vSwitch instances and hardware routers. For the open vSwitch instances, OpenFlow and OVSDB protocols are used, and in case of hardware routers, NETCONF protocol is used. With that infrastructure we can provide VXLAN tunnels from our VMs to geographically independent data centers.
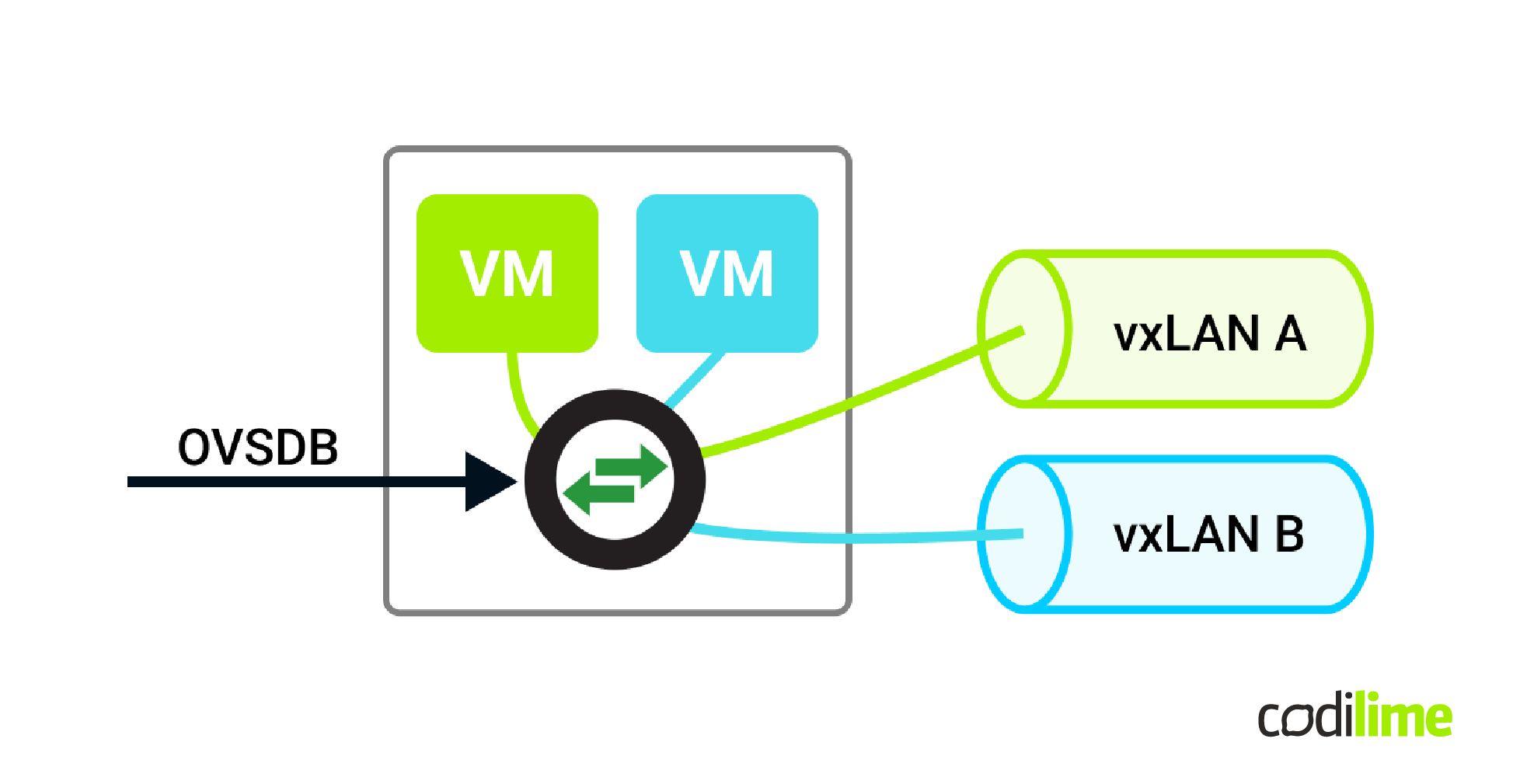
For this particular example there’s no need for such a complicated environment. Because of the SDN approach all we need is an Open vSwitch instance. There will be some configuration needed to create the VXLAN ports and that will be done via the OVSDB protocol. On the actual packet processing and forwarding we need to distribute packets to appropriate tunnels and VMs.
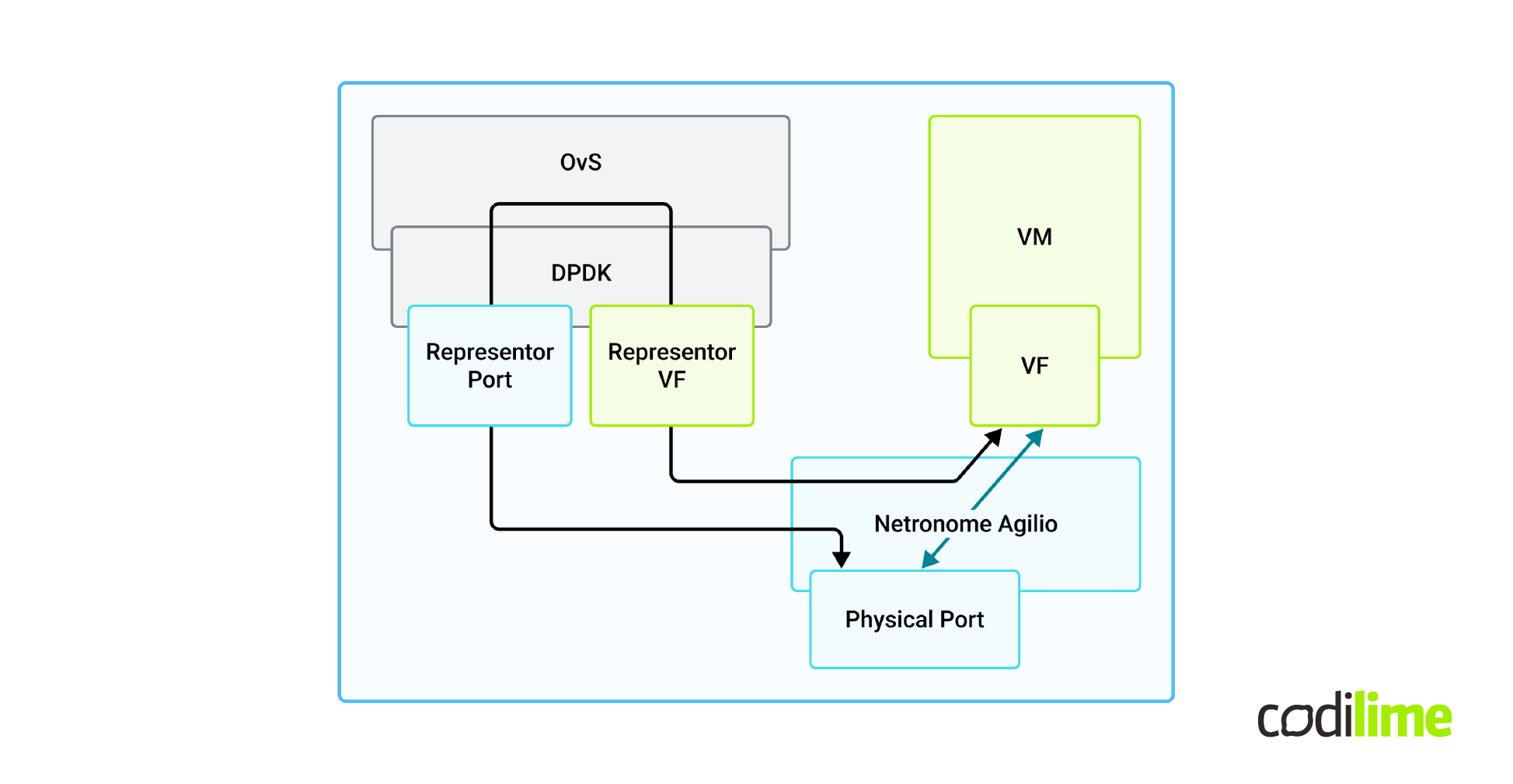
In this image, you can see the high-level architecture of the solution with all the important parts. There’s a virtual machine that is managed by an OvS instance. It’s connected to the rest of its overlay network via a VXLAN tunnel. In this setup we used the DPDK version of OvS and Netronome Agilio as a SmartNIC programmed with firmware we’ve written in the P4 language. It is worth noting that we used the default version of OVS without any customization. The only customization needed was in DPDK.
There are two paths that a packet can take. We call it the slow path and fast path. The slow path is represented by the black arrows. The packet goes from a virtual machine via Netronome Agilio to an OvS instance where it is encapsulated in a VXLAN tunnel. Then, it’s sent via a physical port to the net. The returning packet follows the same route and is decapsulated by the OvS.
Since it is a SmartNIC, it can process the packet fully on its own. So the fast path is where the packet is sent from the virtual machine, then it is processed and encapsulated by Netronome Agilio, and sent directly to the physical port. The returning packet can also be decapsulated by the NIC and forwarded directly to the virtual machine. This path is much shorter, so the packet goes faster. This case is an example of full offloading.
Finally one could ask - why do we even need a slow path? That's because OvS uses a reactive flow insertion mechanism. The OvS needs to see a packet to create a flow for it. So the first packet always has to enter the OvS, where the flow for this packet is created, and then it is offloaded to the Netronome Agilio. The following packets can be processed by Agilio and take the fast path.
Development process
First, we needed to understand the OvS tunneling and offload mechanisms. Then we implemented the slow path part in P4 firmware and the slow path driver in DPDK. With this done, we implemented the fast path part in P4 firmware and the mechanism to insert flows into the Netronome Agilio.
You can see a demonstration of this solution ![]() on our YouTube channel.
on our YouTube channel.
Results of the hardware offloading demo
To test the solution, we used a TRex traffic generator and analyzer. We ran L2 forward instead of VXLAN due to our setup limitations and used an Open vSwitch with a kernel bridge as reference. As you can see in the graph, the latency improved significantly.
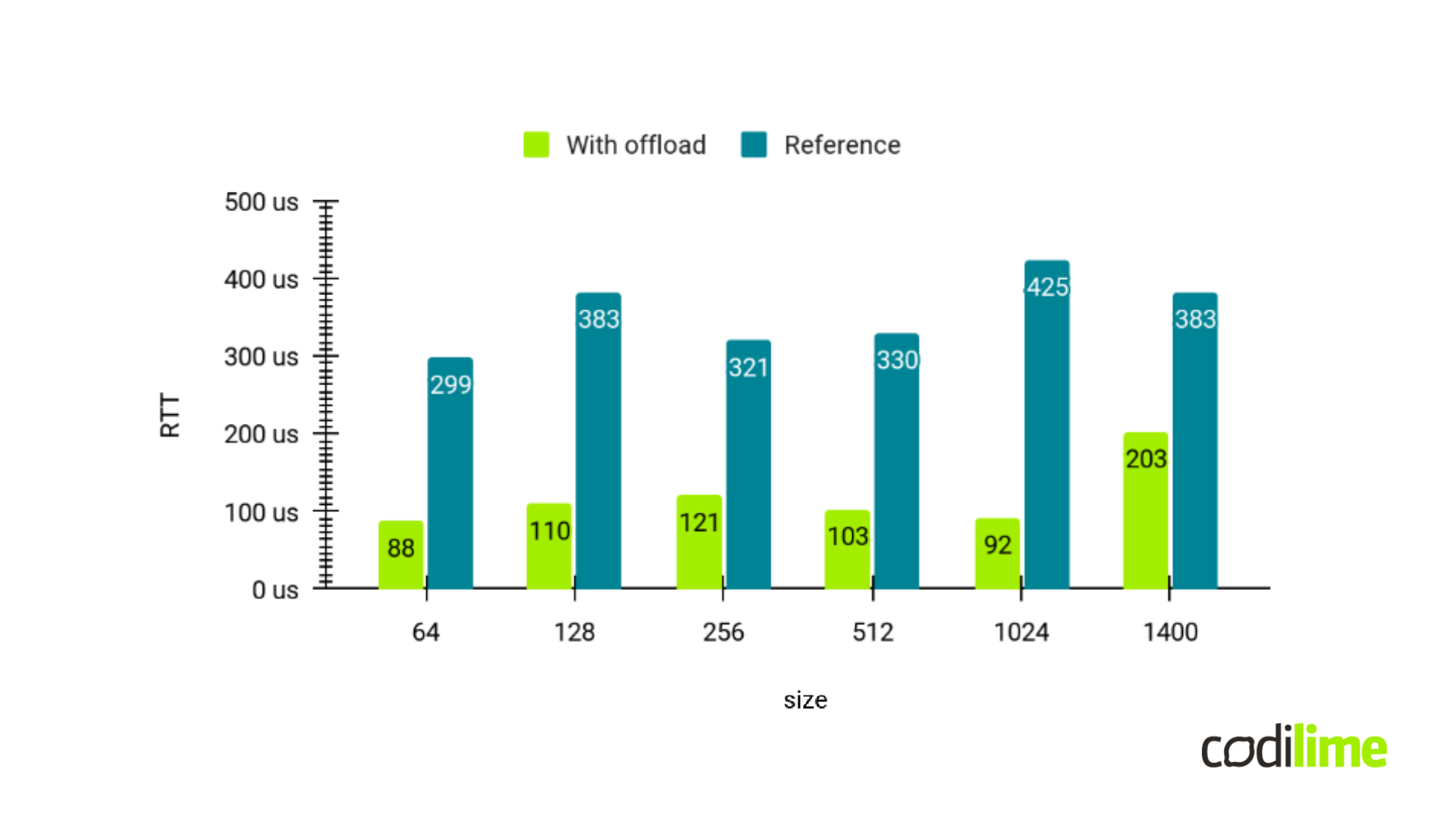
Not only is the latency better. The packets passing through the fast path do not present much jitter at all. This means that all the packets are processed in equal time through the hardware.
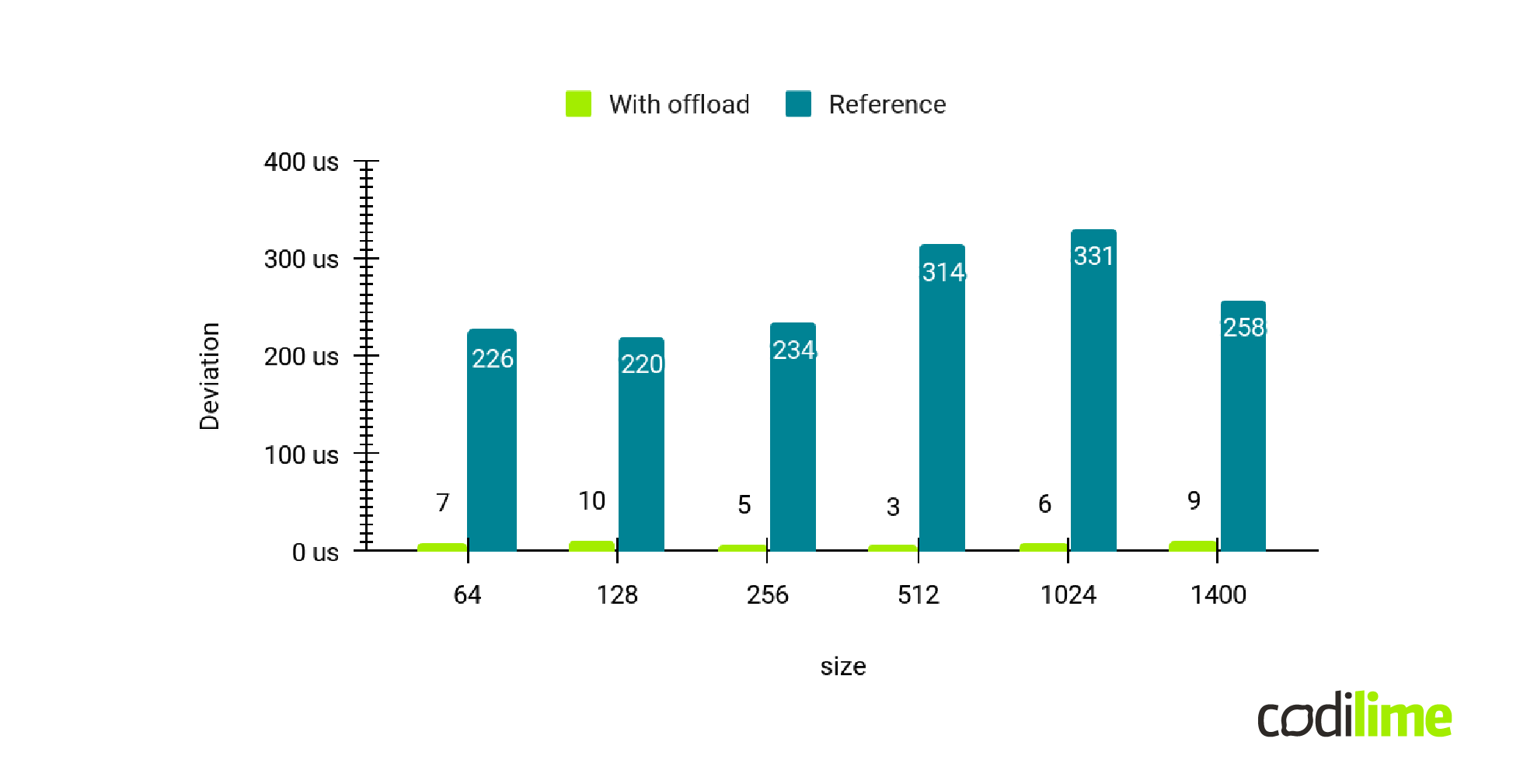
On the other hand, in the reference there is significant jitter. This showcases the mentioned issues with interrupt handling from the NIC and interrupts from other software running in the kernel.
Conclusion
Hardware offloading has limited impact on control plane software. Usually, there’s no need for any input from it at all, and that's because of the SDN approach. On the other hand, in terms of data plane software, there is wide support available, as Open vSwitch and other projects support hardware offloading as well. Tungsten Fabric or VPP are just two examples. There are different software strategies, and in terms of hardware, there are mature solutions such as conventional NICs. There is also the possibility of creating your own hardware solution for niche applications.
This article is based on a webinar that took place on March 28th, 2023.



