


How a P4 pipeline and an FPGA-compiled ML model work together to classify network traffic on the NIC itself, without host CPU involvement.
If you need to detect SYN floods at 100 Gbps+ without burning host CPU cycles, running ML inference inline on a Field-Programmable Gate Array (FPGA) SmartNIC is one viable solution. This article walks through a working demo built by CodiLime and Altera that does exactly that. Using a P4 pipeline and an FPGA-compiled classifier to identify attack traffic on the NIC itself, in microseconds, before packets ever reach the host.
It's also a useful lens on a quieter discipline. Most enterprise AI conversations right now revolve around generative models underneath chatbots, copilots, RAG pipelines, and agentic workflows. The work shown here is something else: classical machine learning, pushed into hardware. Done well, it requires deep expertise in model design, feature engineering, optimization, and deployment constraints. Done well and pushed into hardware, it becomes something hard to replicate.
This article is for network architects, security engineers, and platform teams evaluating whether packet classification should run on the NIC rather than on host CPUs.
The problem: SYN floods are fast, and so must the response be
A SYN flood is one of the oldest tricks in the denial-of-service playbook. An attacker sends a torrent of TCP connection requests (SYN packets) to a server but never completes the three-way handshake. The server holds each half-open connection in memory, waiting. Eventually, the connection table fills up, and legitimate users can no longer get through.
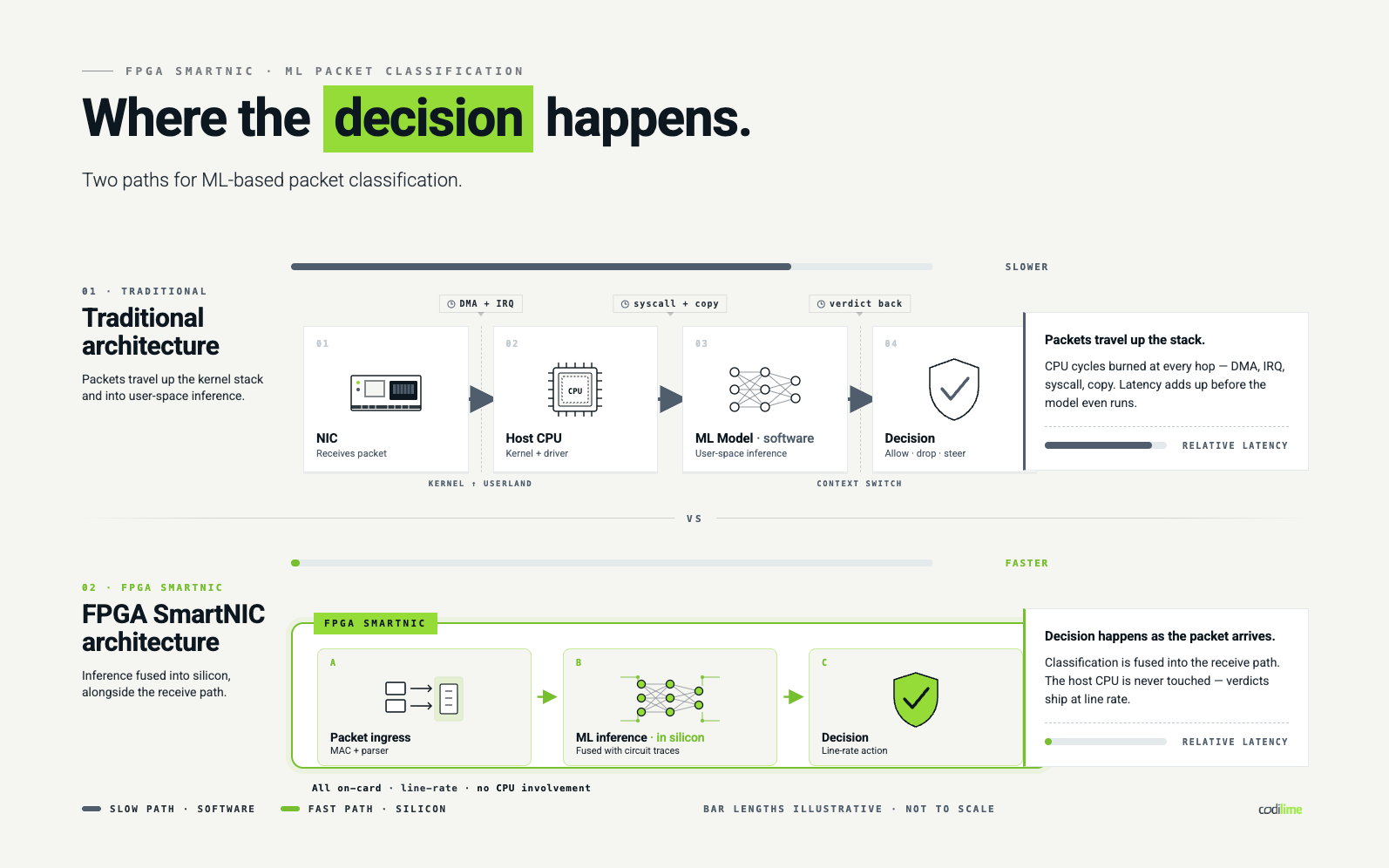
The defensive challenge is not knowing what a SYN flood looks like. The challenge is reacting fast enough, at high enough throughput, without slowing down the legitimate traffic sharing the same wire. Modern data center NICs handle traffic at 100 Gbps and above. Any detection mechanism that requires pulling packets up to the host CPU, running a classifier in software, and then sending a decision back down is already too slow and too expensive in CPU cycles.
The interesting question is: what if the detection ran on the network card itself, before the traffic ever reached the host?
The architecture: P4, FPGA, and a machine learning model in silicon
The demo combines three technologies that are rarely seen working together in a single device.
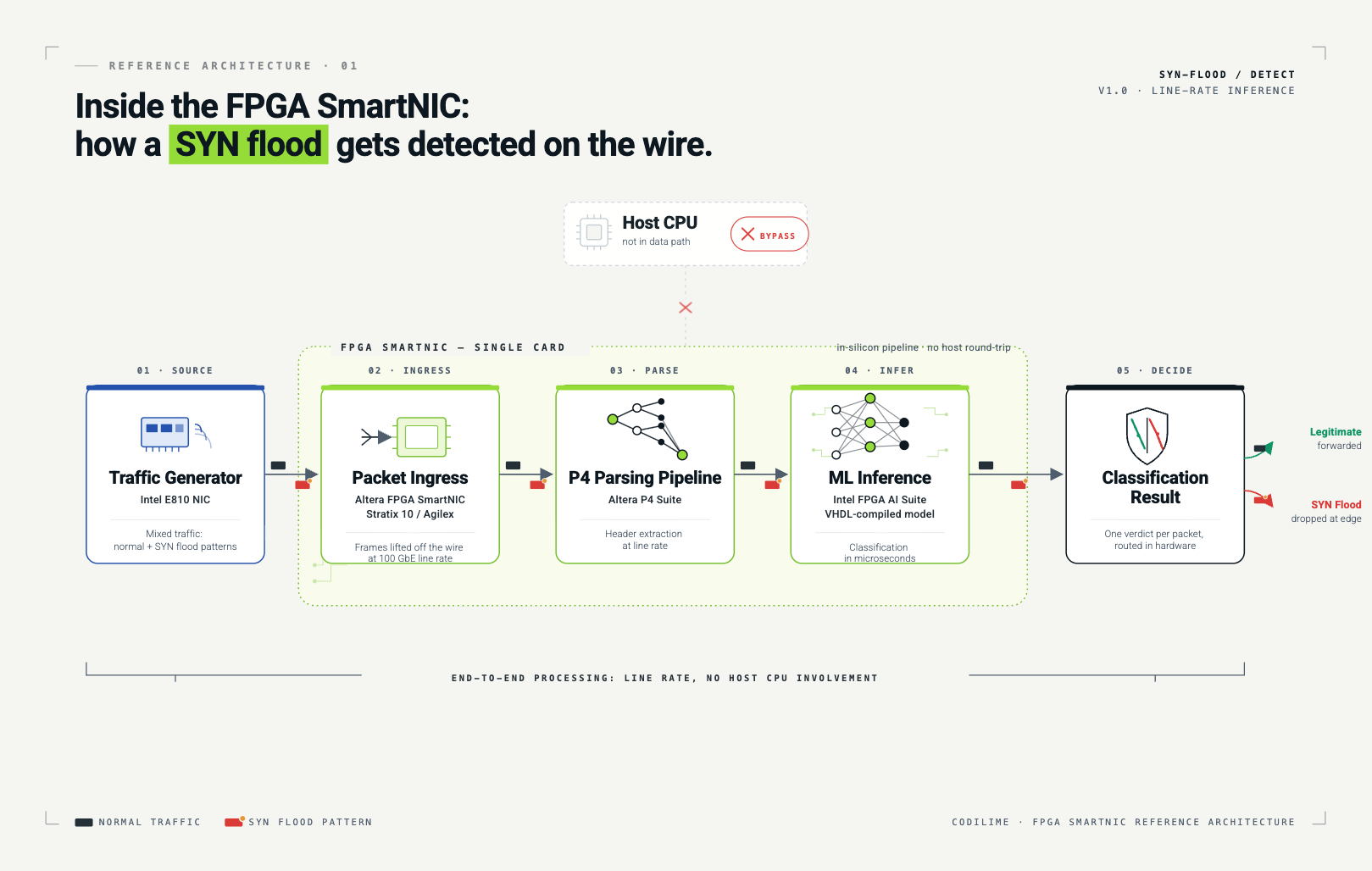
FPGA SmartNIC. The hardware platform is an Altera-based SmartNIC built around either a Stratix 10 or Agilex FPGA. Unlike a fixed-function ASIC, an FPGA can be reprogrammed to implement custom logic, which means the same physical card can be reshaped into different network functions as requirements change. This is the foundation that makes everything else possible.
P4 for the data plane. P4 is an open, protocol-independent programming language for describing how packets should be parsed and processed on the data plane. It lets engineers define custom packet pipelines without writing register-transfer level (RTL) code, then compile that pipeline down to FPGA logic using a vendor toolchain, in this case, Altera's P4 Suite. The result is line-rate packet processing that can be updated like software but executes like hardware.
An ML model converted to FPGA logic. This is the unusual part. A trained machine learning classifier, that being the model that decides whether a given traffic pattern looks like a SYN flood, has been compiled directly into the FPGA fabric using the Intel FPGA AI Suite. The model does not run on a CPU or GPU adjacent to the FPGA. It is part of the FPGA, sitting inline with the P4 pipeline.
How the ML model gets into the chip
This is the step that tends to surprise people, because it sits at the intersection of two disciplines that usually do not share an office.
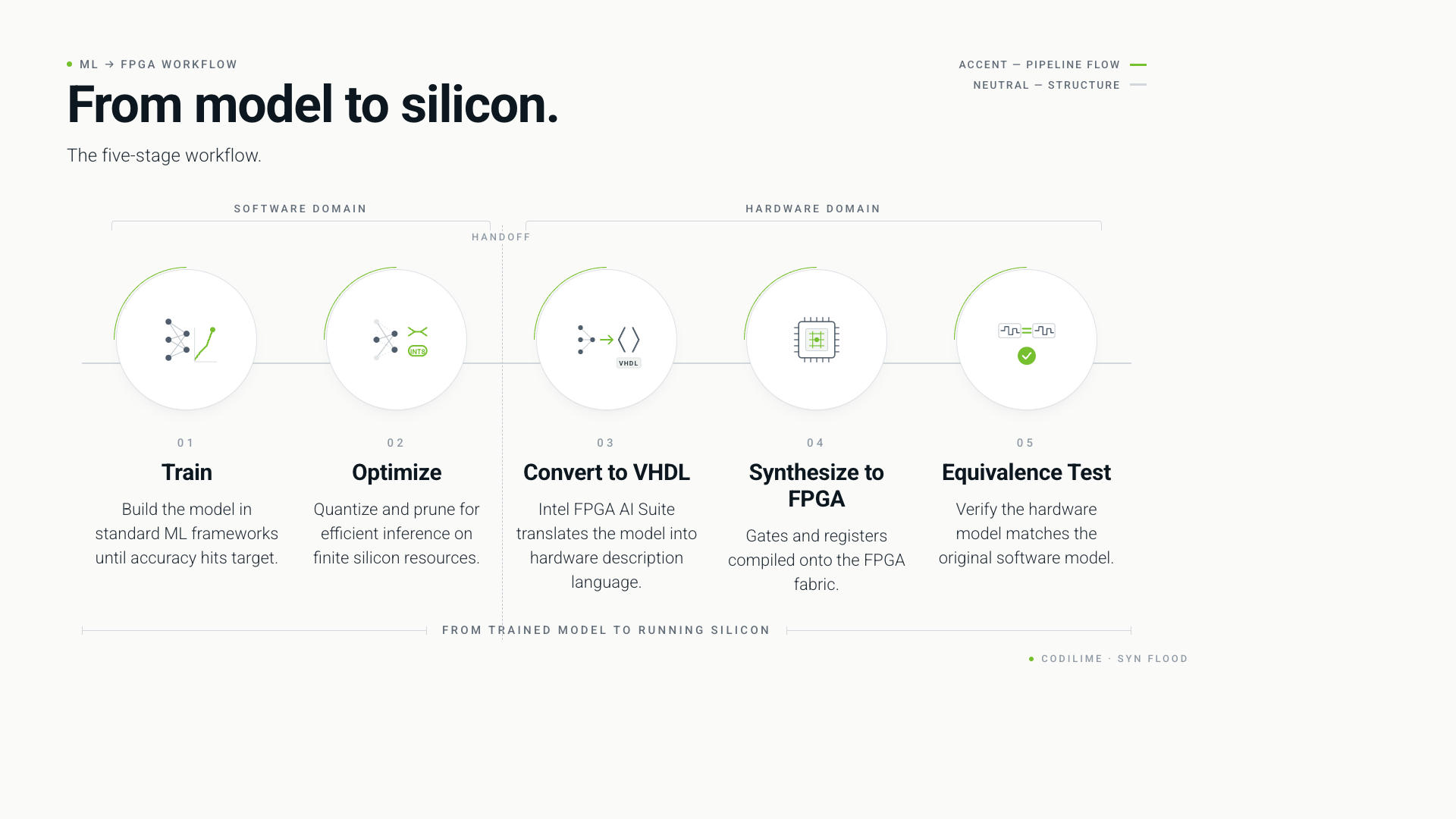
The workflow looks roughly like this:
A data science team trains a model in a standard framework, like any other ML project. Once accuracy hits the target, the model is optimized for efficient inference using techniques like quantization (reducing the numerical precision of weights so they consume less silicon) and pruning (removing connections that contribute little to the output). These optimizations are critical: FPGA logic resources are finite, and an unoptimized model will not fit, or will not run fast enough to matter.
The optimized model is then converted into hardware description language (VHDL), using the Intel FPGA AI Suite. The Suite handles the model conversion automatically, sweeping the design space to balance resource usage against performance targets. The output is no longer a model file you load into TensorFlow; it is gates and registers, ready to be synthesized into the FPGA.
A final equivalence-testing step verifies that the hardware version of the model produces the same outputs as the original software version, within acceptable tolerances. Without this, you have no guarantee that what you trained is what you deployed.
What the demo actually shows
The setup is straightforward to describe and harder than it looks to build. A single server holds the SmartNIC under test. A separate Intel E810 network card acts as a traffic generator, producing two streams of traffic simultaneously: normal application traffic and a SYN flood attack pattern interleaved with it. The traffic flows into the SmartNIC, gets parsed by the P4 pipeline, hits the ML inference block, and is classified. All in hardware, all at line rate, all without involving the host CPU.
The result is detection that happens at wire speed, in the same pass the packet is making through the card. No software loop, no kernel context switch, no model server, no GPU. Just a decision delivered as the packet arrives.
Why this matters for businesses thinking about AI
Most organizations exploring AI/ML in network operations today are choosing between off-the-shelf models and lightly customized versions of them. That is a reasonable starting point, but it also means competing on a layer where the differentiation curves are flat. Everyone has access to roughly the same tooling.
The work shown in this demo lives on a different layer entirely. It requires a team that can:
- Train and optimize ML models with deployment constraints in mind, not just accuracy
- Understand the P4 data plane, FPGA architectures, and the toolchains that connect them
- Run hardware-software co-design across the full stack, from packet parsing through model quantization to silicon synthesis
- Validate that all of it actually works under real traffic conditions
Very few teams can do all of this. For the businesses that need this kind of capability, such as telecom operators, hyperscalers, cybersecurity vendors, and anyone building specialized network infrastructure, the value of working with engineers who can deliver it is not theoretical.
CodiLime has spent more than a decade building this depth, working alongside Altera and others in the networking and hardware space. The SYN flood detector is one demonstration of what comes out of that. It is not the only one.
The takeaway
AI implementation is becoming a wider field than the conversation around it suggests. Above the waterline, there is the visible world of agents, copilots, and chat interfaces. Below it, there is hardware-accelerated inference running inside network cards, custom silicon, and edge devices, solving problems that cannot be solved any other way, by teams that can operate across the full hardware-software boundary.


