


In the beginning, all planning or designing operations were done using pen and paper. With the rise of computers, more and more management operations were done with the help of a machine - from simple calculations, data storage and visualisation, to managing various processes. As their computing power grew, fueled by the need for faster and more reliable operations, whole sectors were switching to computer-based systems. Soon enough, with the number of tasks in every process rising rapidly, scheduling the operations by hand became impractical, so the automation scripts were the natural next step: faster, repeatable, and more reliable than a human hand.
However, in today’s complex world, those scripts are not enough. There’s a need for something more, something that would manage the automation execution, observe its state, etc. - like once automation did for manual task scheduling - that’s orchestration! You can read more about what orchestration is in the orchestration intro blog post.
In real life, the domains we want to orchestrate can get big and complex - and the networks are no exception. It may be cumbersome to remember all the bits and details as the operator - our brains can keep track of only so many things at once. Trying to perfectly reflect reality in the models that operators interact with can lead to inefficient and counterproductive systems due to the sheer amount of data they need to work with.
Take a network device as an example. Its configuration model contains: loopback IP address, Ethernet ports details, BGP routing parameters, OSPF routing parameters, CPU thermal sensor alert threshold, and much more.
Sample schema for node configuration model
loopback:
v4: IPv4 address
v6: IPv6 address
ports:
[name: string]:
front_panel_index: int
speed: string
auto_negotiation: boolean
admin_status: boolean
mtu: int
port_id: int
routing:
bgp:
router_id: int
route_maps: [...]
peer_groups: [...]
asn: int
...
ospf:
router_id: int
areas: [...]
...
alerts:
cpu_thermal_threshold: int
cpu_usage_threshold: int
mem_usage_threshold: int
The experienced operator working with such a model will probably move around with ease, knowing which parameters can be left as defaults or straight up ignored for some use cases. But for a newcomer, many things won’t be so clear - is the thermal threshold important, do I still have to configure BGP even if I don’t use it, and so on. What does an empty or “zero value” field mean? Will it be ignored, defaulted to something, or written to config as is? It’s not clear at all, and operators will have to go to the docs or ask someone else to find the answers. Now multiply this by hundreds of devices in the network and this is a recipe for a slow, cumbersome, unmanageable system.
This detail noise can be countered by introducing abstractions into the models. By grouping the details into higher-level concepts, user-facing models can stay simple, lightweight, while staying expressive and thorough.
Abstraction not only helps the operators, but developers writing the applications can also benefit from decluttered models. The simple thing of explicit separation between domains can massively improve code readability, maintainability, and extendability.
Abstraction
What is abstraction?
Let’s go back to the theory - what is abstraction? In the simplest terms, abstraction is a technique of hiding details behind simpler concepts. As humans, we use it all the time, even in day-to-day things, without realizing it. Take this picture as an example:

What is it? The answer is obvious - it is an equilateral convex 4-vertex right-angled polygon with the HSL(7, 92, 49) color. While precise (and correct), it wouldn’t make sense to name it like that, so for all practical purposes, it’s just a red square. That’s an abstraction in play! We took a detailed and precise description of reality and reduced it to a simpler concept that is understandable and descriptive enough in a given context.
The same thing can be applied to networks and orchestration. Take the previous network device example - instead of directly providing all configuration details, the operators could introduce labels and behavioral abstractions in place of explicit configuration values. Does it matter if the CPU thermal sensor alert threshold is set exactly to 79 or 80? Probably not, but the meaning of Low, Medium, and High is plain and obvious to everyone. Just use one of those labels and let your application take care of converting it to a reasonable value. It doesn’t mean you should put some label-to-value hardcoded mapping in your code and call it a day. That conversion could be configurable or even have a complex algorithm for determining the value hidden behind the simple label-driven abstraction. Thanks to this, we can take a big, bloated device configuration model and transform it to a smaller, optimised and human-friendly one, more convenient to use and (very important for users) requiring less typing.
What’s even more powerful is that the abstraction can stack, resulting in broader, higher-level concepts. This can further reduce the detail clutter and drive the design discussions by the ideas, instead of losing focus on the real goal because of tons of implementation details. Then, as you unpack those ideas, you can start looking inside the abstractions to focus on their internal mechanisms.
Like with the simple abstractions, we do it naturally on a daily basis. Think about it like planning a road trip: At the start, you just need a sense of general direction. If you’re in a nearby area, knowing the main road is enough. And finally, when you’re close to your destination, you’d like to have detailed instructions on where you should go.
Abstraction in a Network Domain
Now let’s see how all of this can work in the world of networks. The diagram below shows the simple 3-tier SPINE-LEAF topology with all of its details (leaf-spine based network layout, often called a fabric, is commonly used in a data center). The bottom tier is simplified (no spine redundancy for leafs) and split into two parts to showcase different roles the TORs fulfill in the example (see later in the text). If you’re experienced and you know what you’re looking for, you can get a decent grasp of it after a while and see what’s going on there. But if there were a couple of hundred nodes instead of just eight, it would take much longer.
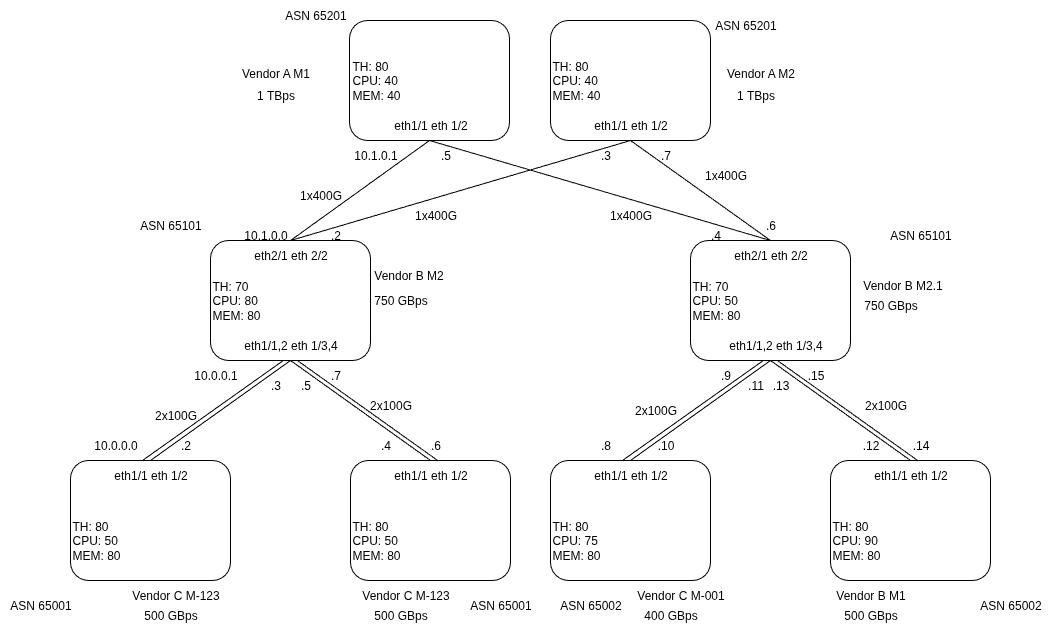
If we pick those nodes’ characteristics and group them together, it’s now much easier to wrap your head around the topology. This is just a simple example but you can imagine this scaled up to hundreds of nodes with dozens of parameters hidden behind just a few abstractions.
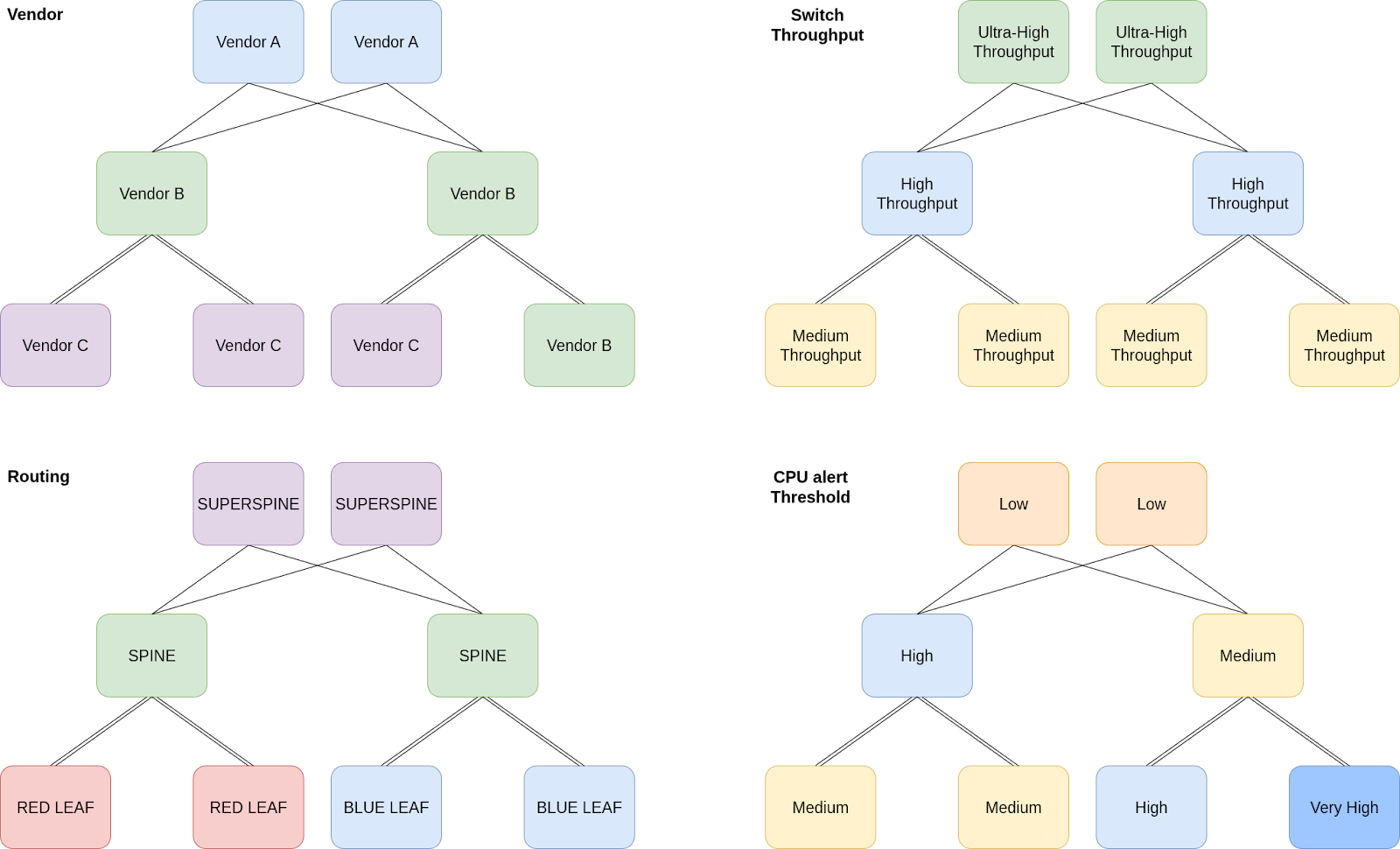
As you can see, the nodes can be grouped differently, all based on the same underlying data. Each node is assigned to a number of groupings, so you can create various “views” depending on the context and your needs. The same topology is seen differently, whether you’re focusing on inventory management or network engineering, and those views will cut off all irrelevant details.
Why should you use abstraction?
All of this may look great on paper, but should you really consider introducing abstractions to your system? Of course, there are a plethora of benefits you could get.
First of all, there is a massive reduction in the cognitive load when you talk about things using simpler concepts. Going back to the red square example - by being precise, during the discussion, you have to remember that its color is HSL(7, 92,49), the newcomers will wonder where this value comes from, someone else could suggest going with HSL(8, 93, 50), completely hijacking the meeting’s goal. Instead of focusing on the purpose of that square, people will shift attention to the exact color value - it must be important since the explicit value was given, right?
Having fewer things to explain during onboarding will make introducing a new person to the system faster and smoother. In combination with using intuitive abstraction names, the newcomers will be able to deduce and internalise how to move around the system efficiently and with ease. They also won’t have so many places to put in some arbitrary values, so the chance of error is much smaller.
Thinking about proper abstractions could help you notice common patterns and operations in your system. In turn, this can lead to moving them to their own dedicated component or library. It’s especially impactful in orchestration systems, since the problem of process and dependency management is a difficult one, centralizing and “black-boxing” it will hide the complexities behind simple APIs. Having less code or a dedicated component reduces maintenance overhead and speeds up code changes, since they don’t have to be redone in multiple places.
When to use abstraction?
Hopefully, you’re convinced that abstractions can be a great addition to your system, and you may wonder when you should start to introduce them.
The first sign is usually a natural feeling. Our human brains are practically designed to recognise patterns, so it should come up naturally. If you find yourself subconsciously omitting some details or grouping things together, then you’ll know they could be abstracted. Don’t underestimate your intuition, because these kinds of abstractions are usually the most useful ones.
You probably know that feeling, when you make a change in a single model and suddenly you’re crushed by the avalanche of functions and components you have to adjust. They aren’t even related to the change, but the code doesn’t compile, the tests don’t pass, and the number of red crosses in your IDE keeps growing instead of going away. This is the perfect time to slow down and think about abstractions instead of putting on a band-aid with another workaround.
Finally, do it when you start to notice the similarities between models or components. These similarities could be functional, structural, behavioral, or anything else you notice. What’s important is that one entity isn’t restricted to being under just one abstraction - it can be assigned to multiple ones depending on the context, like in the Network Example mentioned above.
What to look out for when you're using abstraction!
Although abstractions do look amazing and you may be tempted to use them for everything from now on, you need to be careful because everything is good in moderation (except cheese of course). There are pitfalls that may cause your abstractions to become counterproductive, cumbersome, and frankly, completely useless.
The most common thing to fall into is that you introduce too many layers of abstraction, trying to categorize everything into abstractions. This may (and will) result in so much granularity that you’ll have a separate abstraction for every single item, and you’re back where you started. Don’t force it, don’t overdo it.
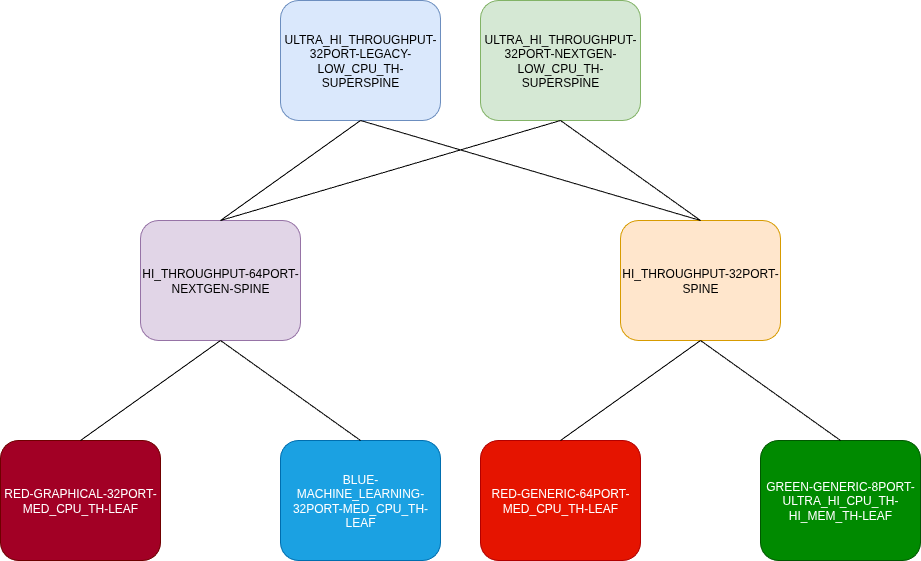
The other trap is working on incorrectly defined abstractions. They are usually the result of coming up with abstractions first and then trying to map reality onto them. The outcome is usually not satisfying, leading to confusion, quick hacks, or frustration. Additionally, bad abstractions will start holding back developers and operators in places where they should help them. They can become too limiting - the developers can suddenly find themselves expanding the models with more and more details, and operators will add labels for every possible value as workarounds.
Abstractions can help developers to follow good programming practices or principles such as DRY ![]() or SOLID
or SOLID ![]() . However, by trying to follow every single rule of those principles in scenarios where they simply don't make sense, you’ll introduce unnecessary complexity to your code. Abstractions should be there to help you and other developers be more efficient, and not to bury you under heaps of restrictive principles and rules.
. However, by trying to follow every single rule of those principles in scenarios where they simply don't make sense, you’ll introduce unnecessary complexity to your code. Abstractions should be there to help you and other developers be more efficient, and not to bury you under heaps of restrictive principles and rules.
How can abstraction help in orchestration systems?
Now that you’re the expert in abstraction, let’s think about how it could be leveraged to ease the development of your orchestration systems. The advantages can be split into 3 areas: Design, Development, and Usage
Design
-
Simplification of the orchestrated domain
- It’s easier to paint a mental picture of the domain using the concepts in place of implementation/configuration details
- The design discussions aren’t sidetracked by focusing on whether some parameter should be set to 69 or 70, because it doesn’t matter at that moment
-
Simplification of the issues to solve
- Divide and conquer - tackling one thing at a time allows to fully focus on the problem at hand, for example: routing, inventory management, and traffic monitoring can be discussed independently
- Modular design - detecting common logic in the system enables modularising it into components; doing this early on will prevent reinventing the wheel later or misusing functionalities in a new component
Development
-
Simplification of the issues to solve
- Divide and conquer - tackle one problem at a time
- Fewer details to keep track of - instead of juggling a full set of details around the system, the relevant components can just deduce them from abstractions
-
Easier modification and extension
- Decoupled components’ responsibilities - separating the components’ responsibilities will reduce the burden and fear of suddenly breaking a completely unrelated piece of orchestrator with a new change; tracking down bugs is much easier if you can narrow down the number of places it can occur
- Module reusability - introduction of common, modular libraries will reduce the amount of code you’ll have to maintain, lower the boilerplate for new functionalities, and ensure that any components taking the same actions will perform exactly the same underlying operations
- New layers can introduce new features without breaking the compatibility - by adding a new layer on top, you can add new functionalities without changing the underlying library's logic
-
Different parts of the system can evolve at their own pace
- Because the components aren’t intertwined and they operate on abstractions, they can evolve independently; any setbacks happening in one component shouldn’t affect the progress of the other ones
- Developers can deliver required functionalities faster and work on continuously improving the product
-
Easier prototyping, testing, and integration
- Developers can easily write prototypes by mocking the abstraction implementation and swapping it later with the proper one
- The testing is simplified since the developers can mock the abstractions or use a simple implementation
Usage
-
Only the relevant set of information is exposed to users in a human-readable way
- Domain simplification
- Better UX for day-to-day usage
- Lower risk of accidental input data errors
-
By hiding the implementation details behind the abstraction, modifications inside the system can be invisible to users
Business advantages of using Abstraction
Given the usefulness and versatility of abstractions, what are the business benefits of using them in your orchestration system?
First of all there is a massive cost reduction. Abstractions in code tend to simplify the flow and structure of applications. Simpler code means easier maintenance, quicker developer onboarding, and lower user entry levels. As a result, less time is needed for efficient use, which in turn means lower costs of running the business.
The big thing for developers is that the system will be able to smoothly evolve to fulfill new requirements. Since the system design isn’t tightly coupled with implementation, those requirements or feature requests can be added without outright breaking up the system and starting from scratch. In combination with the independent nature of components, the new features can be shipped faster, safer, and backwards-compatible. The last point is a massive advantage for end users who don’t have to learn how to use the orchestrator over again.
We’ve made the developers happy, but the end users will benefit greatly too. Remember that at its base, abstraction aims to hide unnecessary details behind higher-level concepts. By reducing the amount of data the operator has to provide, you vastly diminish the chance of accidental errors. After all, the details are inferred or calculated from abstractions. As mentioned before, having less data to input will result in faster and better onboarding processes. Moreover, it will simplify the user documentation and, at the same time, reduce the amount of tribal know-how needed to work with the system.


