


After ONUG Spring 2026, one thing stayed with me very clearly: AI is no longer just another workload that the network has to carry. AI is starting to reshape the way we think about the network itself.
Many conference discussions came back to the same core idea: enterprises are no longer asking only how to use AI in applications. They are asking how to build infrastructure that can support AI safely, efficiently, and at scale. At the same time, they are asking how AI can help operate, secure, and modernize that same infrastructure.
For me, the most useful way to summarize the conference is through two connected perspectives.
AI for networks: how AI, GenAI, and autonomous agents can improve network operations, troubleshooting, security, observability, automation, and remediation.
Networks for AI: how data center fabrics, cloud architectures, Kubernetes platforms, and security models must evolve to support AI-heavy and AI-specific workloads such as training, inference, RAG systems, agentic workflows, and distributed AI applications.
Key takeaways from ONUG Spring 2026
- AI is shifting from a workload the network carries to a force that reshapes network design.
- Two frames matter: AI for networks (agents, automation, security ops) and networks for AI (fabrics, hybrid cloud, Kubernetes, observability).
- Trust (not model quality) is the real adoption barrier for AI in the network operations center (NOC).
- Graph-based operational knowledge is becoming the memory layer for network AI agents.
- Hybrid public-private AI cloud architectures are now a network architecture problem, not just a hosting choice.
Why ONUG Spring 2026 mattered
This was also reflected in the ONUG Spring 2026 agenda ![]() , which included sessions such as “AI Runs on Networks: Rethinking Enterprise Network Infrastructure for the AI Era
, which included sessions such as “AI Runs on Networks: Rethinking Enterprise Network Infrastructure for the AI Era ![]() .” ONUG positioned the Spring 2026 summit around the role of AI in enterprise infrastructure and innovation.
.” ONUG positioned the Spring 2026 summit around the role of AI in enterprise infrastructure and innovation.
What also became clear to me is that AI networking is a cross-domain discipline, not one clean technology track. It connects data center fabrics, hybrid cloud, Kubernetes, security, observability, automation, agent governance, vulnerability management, and operational data models. Some areas are already mature, while others are still early. Many topics were known before ONUG, but the conference made the combined complexity much more visible.
My main conclusion is simple: we are moving from isolated AI experiments toward AI-native infrastructure. This does not mean that every enterprise will rebuild its data centers immediately. But it does mean that networking, security, observability, cloud, and automation teams need to prepare for a very different operating model.
A recurring lesson for me was also that AI in the NOC will only be adopted if engineers can trust it. Hallucinated or ungrounded answers will quickly push teams back to their existing tools. That is why the AI discussion cannot be separated from data quality, evidence, topology, historical incident knowledge, and the way operational context is represented.
AI for networks: how AI is transforming network operations
From automation to trusted agents
One of the strongest themes I noticed was the shift from traditional automation toward something more continuous and intelligent.
For years, network automation has mostly meant scripts, templates, pipelines, pre-checks, post-checks, and configuration validation. These are still very important, and I do not think they are going away. In fact, without solid automation foundations, AI-based operations will be risky. But ONUG showed that the industry is now looking one step further.
The next stage is not only “automate this task.” It is closer to a continuous AI network agent: let it continuously inspect the environment, correlate signals, suggest actions, and help the operations team react faster.
A continuous AI network agent could monitor topology, configuration changes, device state, routing behavior, Kubernetes networking, firewall rules, service dependencies, capacity trends, and incident history. It could also compare a current incident with historical problem and solution tracks: similar symptoms, similar topology dependencies, similar alerts, previous root causes, remediation steps, and validation results.
Instead of waiting for an engineer to manually collect all this information during an outage, the agent could already have a view of what changed, what is abnormal, what happened in similar cases before, and what might be the likely root cause.
However, I would be careful not to present this as magic. AI agents will only be useful if they have access to reliable data and if their actions are controlled by strong guardrails. A network agent that gives a wrong recommendation is one problem. A network agent that pushes a wrong change automatically is a much bigger problem.
So, for me, the real topic is not simply “AI copilots for NetOps.” The real topic is trusted, policy-controlled, auditable AI operations.
Trust is still the real adoption barrier for AI in network operations
Trust is critical in network operations. An AI assistant does not need to be wrong many times before engineers stop using it. A single confident but hallucinated answer during troubleshooting can damage credibility very quickly. If the assistant invents a root cause, references a non-existing configuration, recommends an unsafe command, or misinterprets telemetry, experienced NOC engineers will simply go back to their normal tools.
For me, this means that AI assistants for network operations must be designed less like generic chatbots and more like evidence-driven operational tools. They should cite the telemetry, logs, tickets, topology, configuration fragments, commands, or API calls they used. They should separate facts from assumptions, admit when they do not have enough information, and allow engineers to verify the reasoning quickly.
This also means that context will matter more than the model alone. In many enterprises, operational data is still fragmented. Logs are in one place, metrics in another, topology in another, tickets in another, and documentation somewhere else. Engineers often spend a lot of time just collecting context before they can even start solving the issue.
That is why I believe source of truth, source of intent, telemetry quality, automated validation, and structured operational knowledge are becoming even more important in the AI era. AI does not replace these foundations. It increases their value.
Graph-based operational knowledge as agent memory
One area that deserves more attention is graph-based operational knowledge. Networks are naturally graph-shaped. Devices connect to other devices. Interfaces belong to devices. Services depend on paths. Applications depend on clusters, databases, firewalls, load balancers, DNS, identity systems, and cloud services. Incidents are also connected to changes, alerts, tickets, configuration drift, software versions, previous failures, and known resolutions.
A graph model can connect topology, device inventory, interfaces, routing domains, Kubernetes services, cloud resources, security policies, alerts, incidents, tickets, known errors, previous root causes, remediation steps, and post-incident outcomes. This can help AI agents correlate data more like an experienced engineer. Instead of looking at one alert or one device in isolation, the agent can follow relationships: which service is affected, which devices are on the path, what changed recently, whether similar symptoms happened before, which fix worked last time, and whether that fix is safe in the current context.
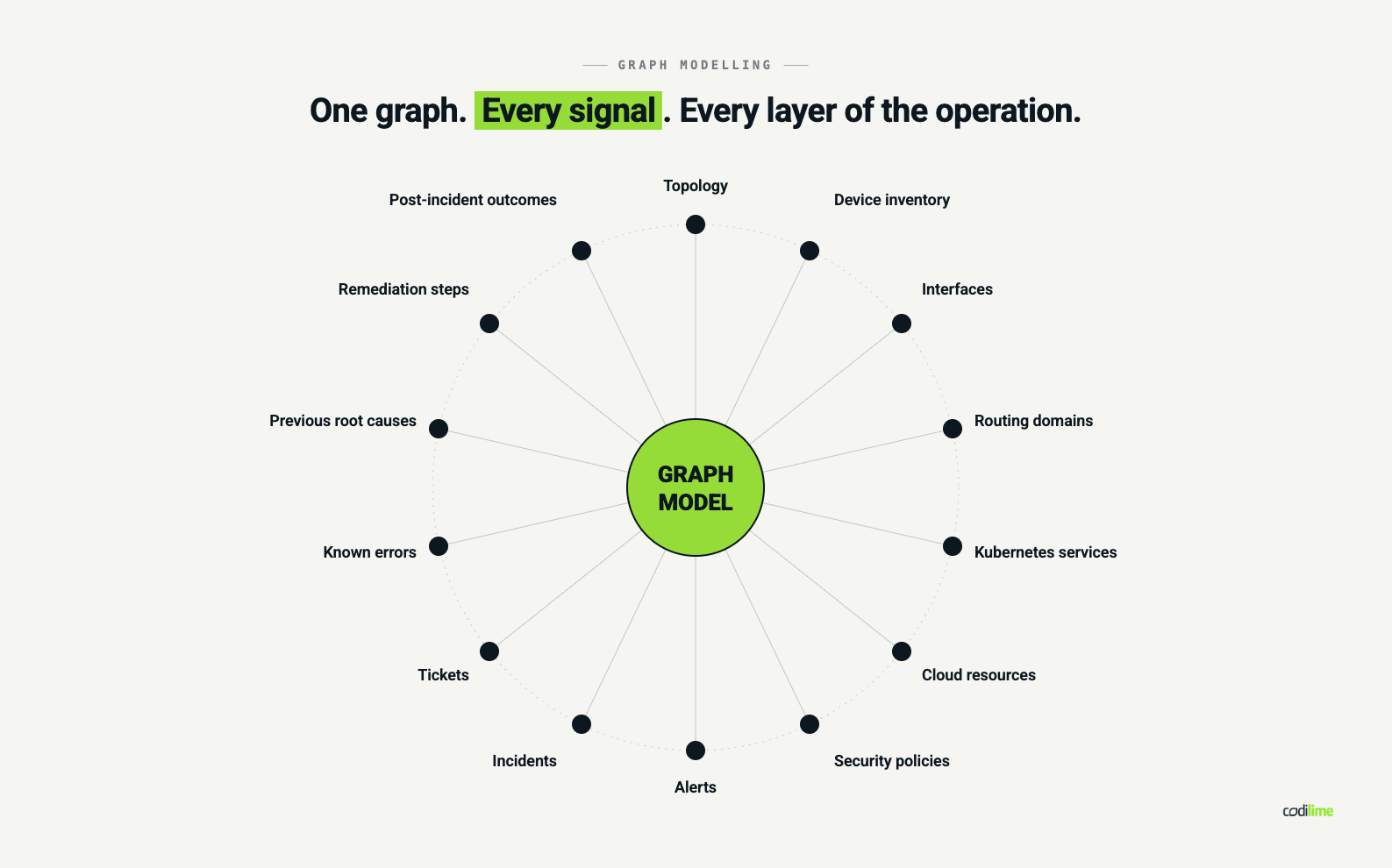
The most interesting part is the historical problem and solution track. Every resolved incident contains valuable knowledge: symptoms, investigation path, failed hypotheses, final root cause, remediation steps, validation checks, and lessons learned. Today, much of this knowledge stays hidden in tickets, chats, postmortems, or individual engineers’ memories. If we represent this history in a structured graph, AI agents can become progressively more useful by retrieving previous cases, ranking likely causes, suggesting proven remediation paths, and avoiding actions that failed before.
This is also where trust and graph-based knowledge meet. Trust does not come only from a better model. It comes from the assistant’s ability to show how it connected topology, alerts, tickets, changes, previous incidents, and known resolutions.
So the real goal is not only to make AI assistants smarter. The goal is to make them grounded, transparent, auditable, and useful under pressure.
Agentic security and authorization by intent
Agentic security addresses a new category of identity in enterprise systems. AI agents are not just users, and they are not just applications. They can interpret human intent, use tools, call APIs, inspect systems, generate plans, and sometimes execute actions. This creates a new security challenge.
In the traditional model, we usually ask: is this user allowed to do this action? In the agentic model, authorization has to consider the user, the agent, the tool being used, the original intent, the data being accessed, and the operational risk of the action. Basic role-based access control (RBAC) will not be enough for autonomous or semi-autonomous agents.
The security model needs identity, tool authorization, policy checks, approval workflows, sandboxing, and auditability. It also needs to connect user intent with tool execution. If a user asks an agent to “check why latency increased,” the agent should not suddenly perform unrelated actions or access systems outside the scope of that intent.
AI-driven vulnerability discovery and the patch storm
A related topic is the acceleration of AI-driven vulnerability discovery. Anthropic introduced Project Glasswing ![]() to give selected partners access to Claude Mythos Preview for finding and fixing vulnerabilities or weaknesses in foundational systems. Anthropic says this work focuses on areas such as local vulnerability detection, black-box binary testing, endpoint security, and penetration testing.
to give selected partners access to Claude Mythos Preview for finding and fixing vulnerabilities or weaknesses in foundational systems. Anthropic says this work focuses on areas such as local vulnerability detection, black-box binary testing, endpoint security, and penetration testing.
For me, this is one of the clearest signals that cybersecurity operations are entering a new phase. AI can help defenders find vulnerabilities faster, analyze complex code, test systems, and prepare patches. But if AI accelerates vulnerability discovery, attackers may also move faster. Even responsible disclosure and patching can create pressure, because once a patch is released, adversaries may analyze what changed and try to build exploits quickly.
This creates a patch storm problem. Enterprises may face more vulnerabilities, shorter remediation windows, and greater pressure on change management. Security teams will need to prioritize faster. Infrastructure teams will need to patch faster. Network teams will need to validate changes faster. Application teams will need to test faster.
To survive this new rhythm, organizations will need better asset visibility, risk-based prioritization, automated testing, staged rollout, fast rollback, segmentation, compensating controls, and strong coordination between SecOps, NetOps, platform engineering, and application teams.
Networks for AI: how AI workloads are reshaping infrastructure
The second big part of my ONUG takeaway is about the network itself.
AI workloads change the data center fabric
AI workloads are not just “more traffic.” They create different traffic patterns. Training, inference, retrieval-augmented generation (RAG) systems, and agentic workflows can stress the data center fabric in different ways, especially through east-west traffic, latency sensitivity, storage access, and GPU utilization.
Traditional enterprise applications often generate a lot of north-south traffic: users to applications, applications to databases, applications to the internet, and so on. AI workloads, especially training and distributed inference, can generate massive east-west traffic inside the data center.
This changes the design problem. AI clusters are sensitive to latency, congestion, packet loss, jitter, flow completion time, synchronization delays, storage throughput, and GPU utilization. A traditional application may tolerate some delay. A large AI training job may suffer significantly if the network cannot keep accelerators fed with data.
That is why AI networking is becoming a serious data center architecture topic, not just a bandwidth upgrade.
The industry is responding with new Ethernet-based approaches for AI and high-performance computing (HPC) workloads. The Ultra Ethernet Consortium describes its Specification 1.0 ![]() as an Ethernet-based communication stack engineered for AI and HPC workloads. Broadcom positions Tomahawk 6
as an Ethernet-based communication stack engineered for AI and HPC workloads. Broadcom positions Tomahawk 6 ![]() as providing up to 102.4 Tb/s on a single chip and being optimized for scale-up and scale-out AI networks.
as providing up to 102.4 Tb/s on a single chip and being optimized for scale-up and scale-out AI networks.
The key point for enterprise architects is that AI-ready networking is not only about speed. It is about predictable performance under extreme parallelism. This includes congestion management, load balancing, telemetry, topology awareness, and the ability to understand workload behavior.
Training may require tightly coupled GPU clusters and very high east-west bandwidth. Inference may be more distributed and closer to applications, users, or data sources. RAG systems may depend heavily on storage, vector databases, and internal knowledge systems. Agentic workflows may constantly interact with APIs, tools, monitoring platforms, and infrastructure systems.
SONiC and more economical open fabrics
SONiC also deserves attention in this discussion. SONiC, or Software for Open Networking in the Cloud, is an open-source Linux-based network operating system that runs on switches from multiple vendors and ASICs. The SONiC Foundation describes it ![]() as offering network functionality such as BGP and RDMA and giving teams flexibility through a broad ecosystem and community. The Linux Foundation says SONiC moved under its open networking projects
as offering network functionality such as BGP and RDMA and giving teams flexibility through a broad ecosystem and community. The Linux Foundation says SONiC moved under its open networking projects ![]() and notes continued alignment with Open Compute Project on hardware and specifications such as Switch Abstraction Interface (SAI).
and notes continued alignment with Open Compute Project on hardware and specifications such as Switch Abstraction Interface (SAI).
For me, SONiC matters because it gives enterprises a way to think about data center fabrics in a more modular and hardware-flexible way. This is relevant for AI infrastructure because the cost pressure is already high. GPUs, storage, optics, power, cooling, and data center space are expensive. If the network can be built with more hardware choice and less dependency on a single vertically integrated stack, the business case becomes attractive.
At the same time, SONiC is not a shortcut. A SONiC-based environment requires strong automation, testing, observability, lifecycle management, and operational discipline. Its value is strongest when enterprises are ready to operate networking more like software, with source of truth systems, CI/CD-style validation, and clear ownership of the operating model.
Hybrid public-private AI clouds
Another important ONUG Spring 2026 theme was the shift toward hybrid public-private AI clouds.
Public cloud is attractive for experimentation, flexible compute, managed AI services, GPUs, model platforms, and fast prototyping. Many enterprises will continue using public cloud for experimentation, burst capacity, and selected AI workloads.
But not every AI workload can go outside the enterprise.
Some AI operations must stay private because they involve sensitive data, regulated information, internal documentation, proprietary knowledge, network configuration, security telemetry, or privileged infrastructure access. This is especially important in financial services, healthcare, telecommunications, government, critical infrastructure, and large enterprises with strict compliance requirements.
The future AI platform will not live only in the public cloud. It will likely span public cloud, private cloud, on-premises data centers, Kubernetes platforms, edge environments, and specialized accelerator infrastructure.
The main question becomes: which AI workload should run where?
A training job using non-sensitive data may be suitable for public cloud. A RAG assistant using internal engineering documents may need to stay in a private environment. A network operations agent with access to device APIs, topology, and configuration history may need to run under strict enterprise control. Real-time security inspection may need to happen close to the data path, possibly on-premises, at the edge, or on accelerated hardware.
This is where the network becomes the connective tissue of the hybrid AI platform. It must provide secure connectivity, predictable performance, segmentation, telemetry, policy enforcement, and data movement controls across public and private environments.
For me, hybrid cloud in the AI era is not just a hosting strategy. It is a risk management strategy, a cost strategy, a security strategy, and a network architecture strategy at the same time.
Kubernetes, observability, and low-level visibility as part of the AI platform
Kubernetes was another major topic at ONUG Spring 2026. It is already widely used for cloud-native applications, and it is increasingly becoming a platform for AI workloads as well. But AI workloads are not the same as traditional microservices. They may need GPUs, accelerators, high-throughput storage, topology-aware placement, inference routing, and specialized network paths.
From a network perspective, understanding these workloads and their traffic patterns becomes critical. AI workloads may generate very different flows depending on whether they are training jobs, inference services, RAG pipelines, or agentic workflows. Some will create heavy east-west traffic between compute nodes, storage, and accelerators. Others will be more latency-sensitive or will frequently call external APIs, vector databases, observability tools, or internal services. Without understanding this behavior, it is difficult to design proper segmentation, quality of service (QoS), routing, capacity planning, congestion control, and security policies.
What I also noticed in panel discussions and vendor booth conversations is that the visibility layer around these platforms is becoming just as important as the orchestration layer. Teams need to understand how AI workloads behave across applications, containers, kernels, networks, accelerators, and infrastructure.
This is where techniques such as eBPF were often mentioned as one practical example. But I would not reduce the topic only to eBPF. The broader point is that AI infrastructure needs richer and more correlated telemetry, including flow data, Kubernetes events, logs, traces, GPU and accelerator metrics, storage performance, and security signals. Without this combined view, teams may design the network around assumptions instead of real workload behavior. Cilium ![]() is one example of an eBPF-based networking, observability, and security solution for cloud-native environments.
is one example of an eBPF-based networking, observability, and security solution for cloud-native environments.
This becomes even more important when AI agents start interacting with infrastructure systems. If an agent uses tools, calls APIs, or triggers automation, enterprises need visibility into what it actually did and whether its actions matched the original intent.
So for me, Kubernetes and observability are becoming part of the AI platform itself: Kubernetes as the orchestration layer, and low-level visibility techniques, including eBPF as one important example, as the evidence layer needed to operate AI workloads safely and to design the network around real workload behavior rather than assumptions.
Centralized and inline AI security
AI security will require both centralized and inline approaches. Some decisions will happen in SIEM, SOAR, identity platforms, and governance tools. But other decisions may need to happen much closer to the traffic, especially for DDoS detection, traffic classification, inline anomaly detection, WAF inspection, or data path enforcement.
Sometimes inference can run in the cloud. Sometimes it should run on-premises. Sometimes it may need to run at the edge. And in some cases, it may need to run directly on accelerated infrastructure such as GPUs, DPUs, SmartNICs, or FPGAs.
The location of AI inference is not only a performance decision. It is also a security, privacy, latency, and cost decision.
Practical steps for enterprises adopting AI networking
Because the number of related topics is so large, the practical path matters more than trying to solve everything at once. The next steps are becoming clearer, but they are still difficult because they cut across teams, tools, data models, security policies, and infrastructure domains.
Based on the ONUG Spring 2026 themes, I would group the practical steps into six areas.
- Classify AI workloads and traffic patterns. Separate experimentation, training, inference, RAG systems, internal assistants, security analytics, and autonomous agents. Each category has different networking, security, hosting, and observability requirements.
- Define what must stay private. Enterprises should identify which data, systems, models, and agentic workflows cannot leave controlled environments. This is the foundation for hybrid public-private AI architecture.
- Assess the data center fabric and hybrid connectivity. AI workloads can expose weaknesses in east-west bandwidth, congestion handling, latency, telemetry, topology design, segmentation, and interconnect strategy.
- Strengthen the operational data foundation. Build a graph-based operational knowledge layer that connects topology, inventory, telemetry, tickets, incident history, known resolutions, and postmortem data. This will make NOC assistants more context-aware, more explainable, and more capable of improving over time.
- Establish agent guardrails and safe automation. Even before agents are allowed to execute changes, enterprises should define agent identities, permissions, tool access, audit trails, approval workflows, validation checks, rollback mechanisms, and patching processes that can keep pace with faster vulnerability cycles.
- Treat AI networking as an architecture program, not as a single tool purchase. New switches, fabrics, platforms, models, and network operating systems matter, but the bigger challenge is integration into a secure, observable, explainable, and trusted operating model.
Summary: from ONUG Spring to ONUG Fall
My main takeaway from ONUG Spring 2026 is that enterprise infrastructure is entering a new phase. AI is no longer only consuming the network. It is starting to influence how networks are designed, operated, secured, and modernized.
For me, the most important message is that this transition is not about one tool, one platform, or one vendor decision. It is about building a trusted operating model for AI-ready infrastructure with better data foundations, stronger automation, clearer security boundaries, and more flexible network architectures.
The discussion will continue at the next ONUG AI Networking Summit in New York ![]() , taking place October 28-29, 2026, where ONUG says enterprise IT leaders will focus on successful AI implementation and adoption.
, taking place October 28-29, 2026, where ONUG says enterprise IT leaders will focus on successful AI implementation and adoption.
Many enterprises are already on this path. The challenge now is to make these efforts more structured, secure, and operationally mature. The practical steps are becoming clearer, but they still require coordination across networking, cloud, security, platform, and operations teams. In the AI world, six months between ONUG summits is a long time, and by the fall event, priorities and maturity levels may already look different. That pace of change is the strongest argument for flexible infrastructure and operating models.


