


Service mesh and Ingress are two solutions used in the area of application networking in Kubernetes and are often compared as Kubernetes traffic management mechanisms. In this article, you will see what characterizes each of them and understand where the real difference between Kubernetes Ingress and service mesh is.
What is a service mesh?
A service mesh is a kind of special “system” for communication between applications, different components of an application based on microservices architecture, or between various other workloads running in virtual environments, such as Kubernetes. The solution provides a rich set of features in the fields of Kubernetes traffic management, reliability, resilience, security, and observability.
A service mesh, as such, has an application-centric focus because it deals mainly with Layer 7 (L7) of the OSI model with protocols like HTTP(S) or gRPC. Specifically, it is about proxying and securing connections between workloads deployed in the cluster as well as providing fine-grained control and insight over such traffic. On the one hand, this enables the unification of workload communication. On the other, equally important, hand, it saves developer time and effort by eliminating the need to implement this type of functionality directly at the application level.
A service mesh does not come out of the box when you deploy your Kubernetes cluster. This is additional logic that you need to add to the cluster as extra software. There are many different Kubernetes service mesh implementations available today, e.g., Linkerd, Istio, Kuma, or Traefik Mesh. They differ both in terms of maturity and the number of supported functionalities.
When a particular service mesh implementation is installed in the cluster, an additional container acting as a sidecar proxy is injected into each Pod. It is a kind of L7 proxy that works in both forward and reverse mode. This proxy handles calls to and from the workloads on behalf of which it acts.
To configure and coordinate the behavior of the proxies, a service mesh has a dedicated control plane which is the brain of the entire system. This is a very powerful system - by introducing a proxy to each Pod, it gains a deep insight into the communication between workloads running in the cluster and allows control of such service-to-service traffic in a sophisticated way.

What is Kubernetes Ingress?
Ingress is a Kubernetes API object that manages external (north-south) access to multiple resources running in a cluster. Most often, these resources are Kubernetes Services. Underneath, Ingress is a kind of proxy, typically for HTTP or HTTPS traffic, so it works at Layer 7 (L7), similar to a service mesh. More specifically, it implements L7 routing, which is also sometimes called HTTP routing or path-based routing.
In short, Ingress exposes HTTP routes from outside the cluster to Services in the cluster. For example, if requests containing different endpoints, e.g., example.com/api/v1, example.com/blog, example.com/stats come to the Kubernetes Ingress controller, they can be routed to three different Services deployed in the cluster.
It is important to understand that to make Ingress work, an underlying mechanism executing Ingress logic is needed. This is called an Ingress controller. Creating a "dry" Ingress object without having any Ingress controller running in the cluster has no practical effect. Kubernetes does not offer any native Ingress controller implementation by itself.
Instead, you are free to choose one of the many Kubernetes Ingress controller solutions available, such as Nginx Ingress Controller, Kong, Contour, Gloo Edge, and Voyager, as well as implementations offered by cloud Kubernetes providers (AWS, GCP, Azure) and well integrated with their cloud services, etc. Usually, these are based on one of the available reverse proxy engines, such as Envoy, Nginx, or HAProxy, etc.
There is also another Kubernetes API, which is called Gateway API. You can learn more about it in this video:
Kubernetes Ingress vs. service mesh - where is the difference?
If you are not familiar enough with Kubernetes Ingress and service mesh concepts, and you have not had any prior experience with them, you could easily get the impression that they are basically similar solutions in Kubernetes networking. They both process traffic on the L7... They both act as proxies... So, where is the difference between Kubernetes Ingress and service mesh? Maybe it is about the set of offered functionalities? Let's check.
In general, all the features offered by Kubernetes service meshes can be grouped into four categories:
-
The first encompasses functions related to routing and traffic management.
In short, it is about proxying and performing sophisticated load balancing (at L7) for various types of protocols, e.g., HTTP/1.x, HTTP2 (including gRPC), WebSocket, and other TCP-based protocols. -
The second group includes reliability and resilience mechanisms.
One example is the so-called circuit breaker, allowing you to block incoming connections to the application when given conditions are met (e.g., the maximum number of concurrent connections has been reached, or a failure threshold defined for some app has been exceeded). Other examples here are timeouts and retries settings that prevent workloads running in the cluster from being overwhelmed with requests (e.g., when some failure occurred and the given application is temporarily unavailable). -
Security features are another category.
Here you can apply advanced mechanisms for authentication and authorization, as well as mutual TLS between workloads inside a Kubernetes cluster. -
The last group is the so-called observability functions.
In general, observability can be defined as the ability to measure a current state of some system or software environment by examining the different types of data it generates. It is based on three pillars: monitoring (a process of continuous gathering of various types of metrics - numerical data, most often related to the system performance), logging (a process of registering all kinds of events that happened within the system) and tracing (a process that helps to observe and analyze the entire life cycle of information flows going across the system).
In the context of service mesh, observability is about collecting various types of metrics, e.g., request volumes, success rates, latencies, etc. (monitoring), gathering data needed to troubleshoot latency issues (tracing), and providing verbose logging capabilities. To make all these possible, a given Kubernetes service mesh solution can be integrated with different observability back ends, such as Prometheus for monitoring, Zipkin or Jaeger for tracing, Fluentd for logging, etc.

How about Ingress in Kubernetes?
Well, the official Kubernetes Ingress API link-icon ![]() only offers a way to perform path-based routing for HTTP traffic. This is much less than a service mesh can give you, in general. However, you should be aware of one very important fact. Most of the Ingress controller solutions implement much more functionality than the Kubernetes Ingress API would normally offer. These features are exposed through the so-called CRDs (Custom Resource Definitions). Moreover, in many cases, the extended functionality may be (more or less) similar to that offered by various service mesh implementations.
only offers a way to perform path-based routing for HTTP traffic. This is much less than a service mesh can give you, in general. However, you should be aware of one very important fact. Most of the Ingress controller solutions implement much more functionality than the Kubernetes Ingress API would normally offer. These features are exposed through the so-called CRDs (Custom Resource Definitions). Moreover, in many cases, the extended functionality may be (more or less) similar to that offered by various service mesh implementations.
So is the set of supported functions something that distinguishes Kubernetes Ingress vs service mesh? Basically, yes, though it doesn't have to be a big difference in many cases. The real difference between Ingress and service mesh lies elsewhere.
And here we come to the key point. It is very important to know how to correctly identify which cases Ingress applies to, and for which a service mesh is more suitable, because this may not always be clear.
Imagine a case where you have deployed several applications in the same Kubernetes cluster. They are all completely independent workloads and have nothing to do with each other. But each of them will handle HTTP(S) requests coming from outside the cluster. What you want to do is configure a common entrypoint for them that will allow external users to use the same domain name, followed by a path specific to a given application when they connect to those applications using web browsers.
This is an ideal Kubernetes use case for employing Kubernetes Ingress, as it will allow you to handle the HTTP(S) traffic entering the cluster from outside and route it to your applications appropriately. This is sometimes called north-south traffic (see Fig.1).
If you assume external users can reach your applications from the Internet, the full picture requires further actions to be carried out (e.g. putting a cloud load balancer or on-premise reverse proxy server in front of the cluster, depending on where it is deployed, obtaining a public IP address, public domain name and its registration, adding all the necessary configuration) but we won’t go into details here.
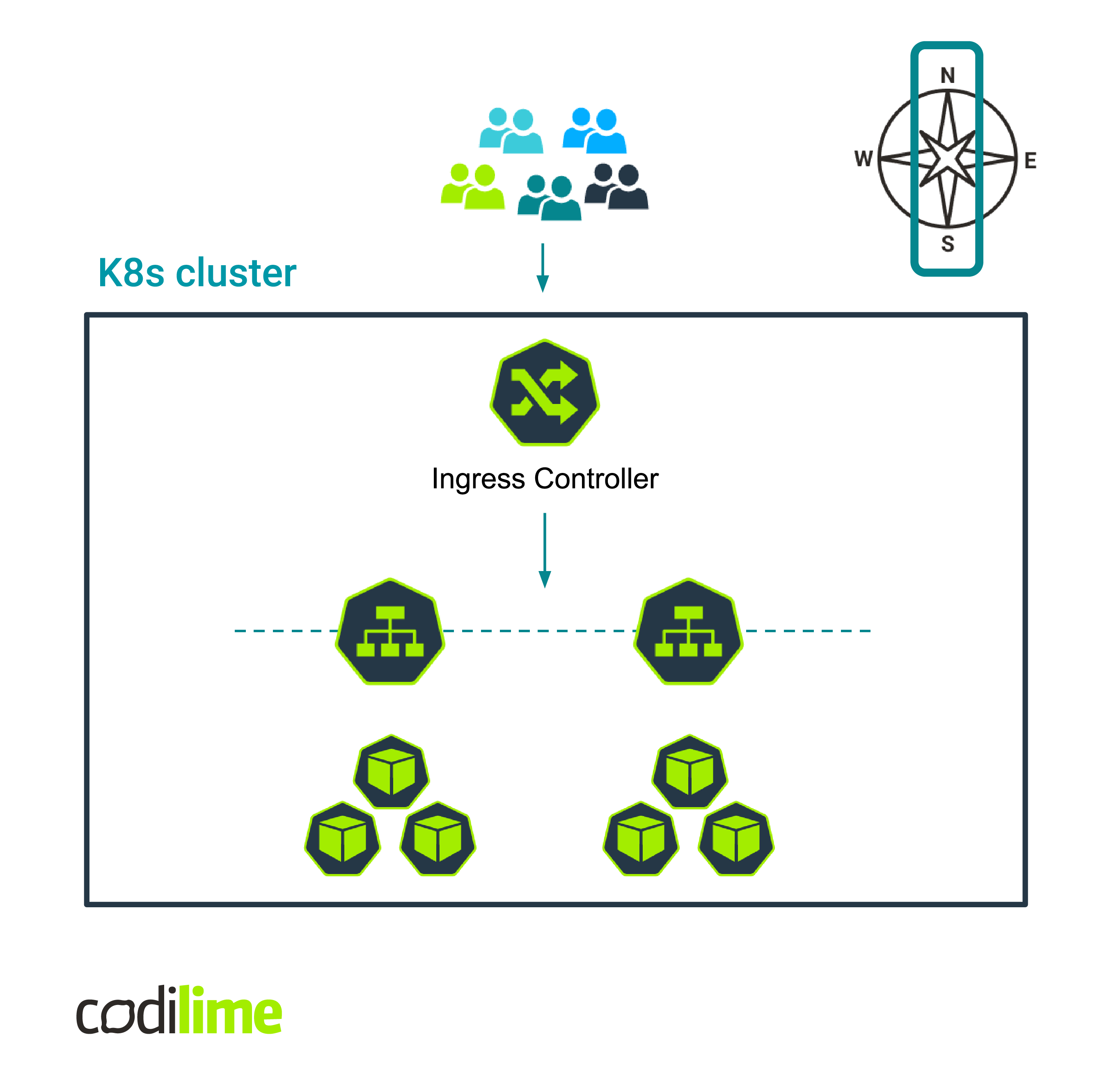
On the other hand, there might be cases where you need more control over east-west traffic (see Fig.2), meaning the traffic between workloads running in a cluster. A good example of this would be a scenario where you deploy in Kubernetes an application based on a microservices architecture that contains many components (they are then called services).
If you want a deeper insight into the communication between services on the higher layers of the network stack and you need to control such traffic in a sophisticated way (e.g., using advanced load balancing and resilience mechanisms), then using a service mesh for this purpose will be a good idea.

Of course, this is a very general distinction. There may also be use cases when you need to use Kubernetes Ingress and a service mesh together at the same time. For example, if in the above-mentioned scenario (the application based on a microservices architecture) we add the assumption that multiple applications’ components are supposed to serve HTTP(S) requests coming from outside the cluster, then such north-south HTTP traffic must be properly handled.
Here, in addition to the service mesh, Ingress will also come in handy. By the way, it is worth knowing that some of the Kubernetes service mesh implementations offer such functionality out of the box, i.e., they allow you to control not only east-west traffic but also north-south traffic in Kubernetes. Then, you do not need to onboard any additional Kubernetes Ingress controller into your cluster.
>> Read more about our network professional services.
Summary: Service mesh vs Kubernetes Ingress
The functionality offered by various implementations of Kubernetes service mesh and Ingress controllers may differ from each other to various degrees. But that's not where the real difference between the two concepts is. While Kubernetes Ingress is targeting north-south traffic, service mesh focuses on east-west traffic, that is, communication between workloads running in the cluster. It is worth understanding this in order to know which one should be used in specific Kubernetes networking use cases.


