


Usually, in our blog posts, we talk about networks, and today we will not stray too far from our main topic. As is the case with networking technologies, storage undergoes constant evolution. Some areas that are seeing rapid development are solid-state drives and remote access. This article will delve into how those technologies are bridged with NVMeoF.
NVMe protocol
Most people know NVMe as a type of SSD that can be used in computers. And that is indeed true - there are two interfaces commonly used for SSDs: SATA and NVMe. Using SATA for the new generation of drives works great when compatibility between legacy components is needed, and performance can be of secondary importance. But SATA originated in 2000 and was created for hard disk drives with rotating platters and heads. Although these devices offer a solid throughput, they contain a lot of mechanical components that introduce significant latency to each read/write operation. Those hardware limitations influence the SATA interface specification and its performance. For enterprise applications, instead of SATA, a SAS interface is used. Both of those interfaces are evolutions of previous interfaces (respectively: ATA and SCSI), utilizing existing commands set over a serial link. Both of these interfaces require a hard drive controller between the CPU and disks.
Consequently, when a new generation of solid-state drives becomes available and theoretical performance becomes closer to RAM than HDD, the need for a new access interface arises. Thus, finally, the NVMe (Non-Volatile Memory Express) interface was developed and introduced in 2011. This interface is designed to take advantage of the low latency and high flash storage performance. Physical connectors vary depending on the application: for customer devices, M.2 form factor is usually applicable since the devices don’t require hot plugging, and weight and space are important. PCIe devices can be attached as USB-C pluggable devices thanks to the Thunderbolt 3 interface, so NVMe drives are commonly found in this form (although only the newer USB standards allow the bandwidth to exceed that of SATA and make sense to present the device as an NVMe drive).
Some NVMe drives can be found as PCIe extension cards used in PCIe slots, though this form is very niche since it takes a slot preferably used for GPU cards by PC enthusiasts. In compute servers, NVMe drives usually come as M.2 drives (commonly used as boot devices) and U.2 for data. The former allows for hot-plugging devices; although this is only a standard for connectors, it is most commonly used with 2.5” SSDs. Consequently, the devices have a high capacity and enable the construction of high-density storage clusters.
At a high level of design, the NVMe specification describes a simple protocol with a set of only 13 commands. In order to enable high parallelism, the commands can be executed on up to 64K I/O queues, with each able to hold 64K commands. This is nearly three orders of magnitude more than the SATA specification.
Remote block storage protocols
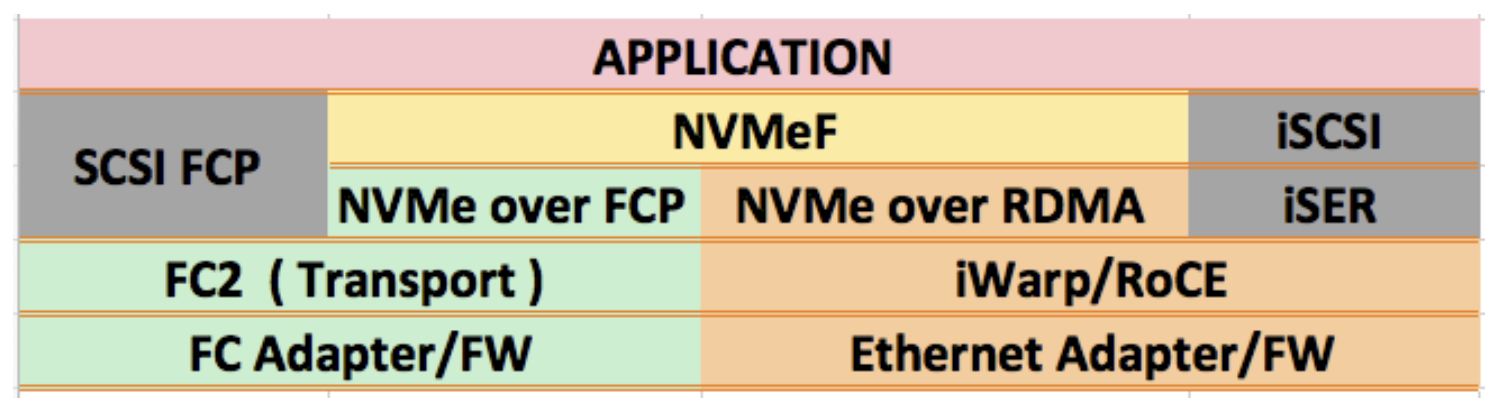
In terms of remotely accessible storage, there are two approaches: NAS (network-attached storage) and SAN (storage area networks). The first one is aimed at personal users and small teams, while large-scale organizations and enterprises often use the second. NAS is often used within the context of small, household file servers, and it is characterized by a set of easy to use network protocols for mounting the storage. Most commonly, NAS devices allow usage of NFS (network file system), and SMB (server message block) to access the file system. And that is one of the key disambiguations from SAN: NAS devices handle the filesystem layer and act as file servers. On the other hand, SAN devices are meant to serve only the block storage and leave the file system layer to the client. That leaves us with the question: What protocols allow the client to access the block devices on a remote server?
Before we go any further, we should consider SCSI, which is a standard for accessing storage that emerged in the 1980s. It has evolved over the years, and its command set has been reused in newer protocols such as SAS (serial attached SCSI) and USB attached SCSI. However, even more interesting applications of the command set were found in storage area networks (SAN). SCSI was used in SAN as a protocol to access block storage remotely. In order to allow this, SCSI commands are encapsulated over a network protocol and exchanged between initiator (iSCSI client) and target (iSCSI server with storage resources). The two main transports used with SCSI are TCP (iSCSI) and Fibre Channel Protocol, though FCP itself can be encapsulated [again] over Ethernet (FCoE).
Network fabrics
Both iSCSI and NVMe can be used as protocols for accessing block storage remotely, and similarly, both of these technologies use fabric networks as their transport. In this context, a fabric network is a general concept of abstracting away the infrastructure. Fabric networks, as a term, are associated with the emergence of network virtualization and cloud computing. Consequently, it does not matter whether the devices are connected over a local network or cross-data center using a tunnel. Regardless of actual implementation, the hosts expect the top-most performance from the network in terms of peer-to-peer bandwidth and latency.
NVMe over Fabrics
Initially, NVMeoF was published as a standalone specification, separate from NVMe. After successful implementation, it became part of the standard. It allows encapsulation of NVMe commands over a choice of transports, extending the usability of the protocol to data transfers between hosts and storage across network fabrics. The concepts are very similar to SCSI-based protocols (such as iSCSI or iSER), a command set that was initially developed for accessing local storage is reused to communicate between the storage server and host across the network.
Similarly to iSCSI, an initiator and a target (client and server, respectively) establish a connection and exchange commands. Predominantly, their NVMe stacks are implemented purely in software, but since targets often serve multiple initiators and initiators may require access to multiple disaggregated drives, better performance could be achieved by offloading command de/encapsulation to the dedicated hardware (e.g. DPU).
Contrary to SCSI, NVMe protocol allows for parallel I/O operations and does not require inter-process locking. Furthermore, compared to SCSI, NVMe improves session interaction: for a single data transfer only one round trip and two interactions are required, while SCSI requires two round trips and four interactions. Those benefits are translatable to NVMeoF, and with latency introduced by the network, halving the round trip time is an important factor for overall performance.
NVMe transports vary in some key characteristics. An excellent classification taxonomy is provided in the NVM Express Base Specification:
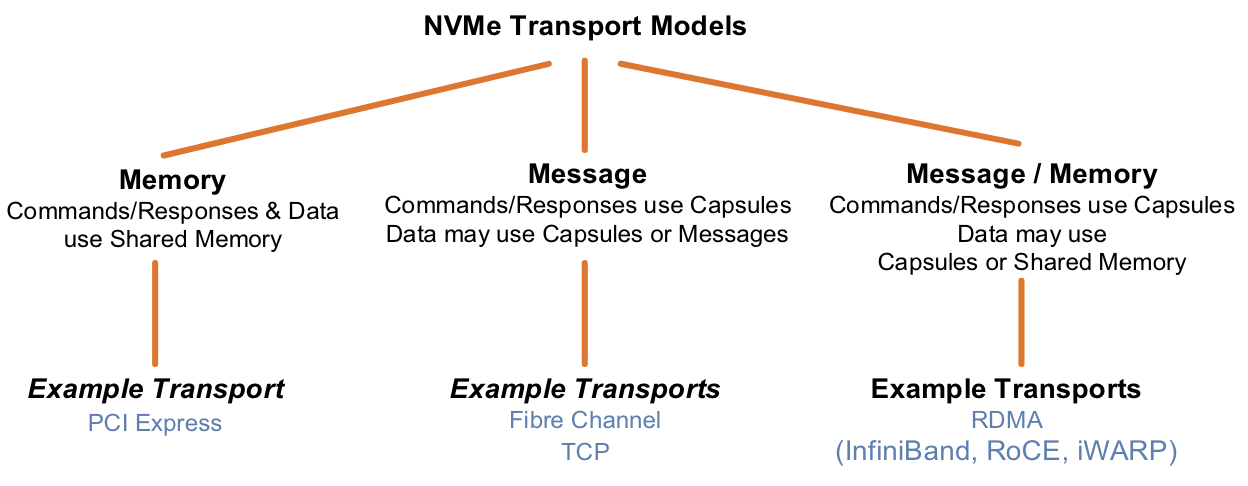
Firstly, we have memory transports used to access local storage within the host. It uses a local bus to communicate with the storage device. The devices are usually connected with PCI Express or other local bus technologies like CXL or AXI.
NVMeoF extends the usage of the NVMe command set over message-based transport. Currently, the RDMA and TCP Transport are specified by NVMe, while NVMe over Fibre Channel (FC-NVMe) is governed by INCITS. In case of NVMe/TCP, a TCP connection is established between initiator and target, and the NVM subsystem communicates over this connection exchanging NVMe/TCP protocol data units. This TCP connection is used for both command and data transfers, and is typically handled in software, by the kernel network stack. This results in reduced performance and requires additional compute resources, on the other hand, such an approach does not typically require any special configuration from the network.
FC-NVMe utilizes Fibre Channel’s reliability, parallelism and multi-queue capabilities to provide efficient message transport over existing FC networks. Compared to NVMe/TCP, FC introduces less CPU overhead since the protocol is simpler.
Nevertheless, neither NVMe/TCP nor FC-NVMe-2 utilize modern, offloading NICs capable of accelerating remote direct memory access (RDMA). Fortunately, NVMe specifies RDMA transport.
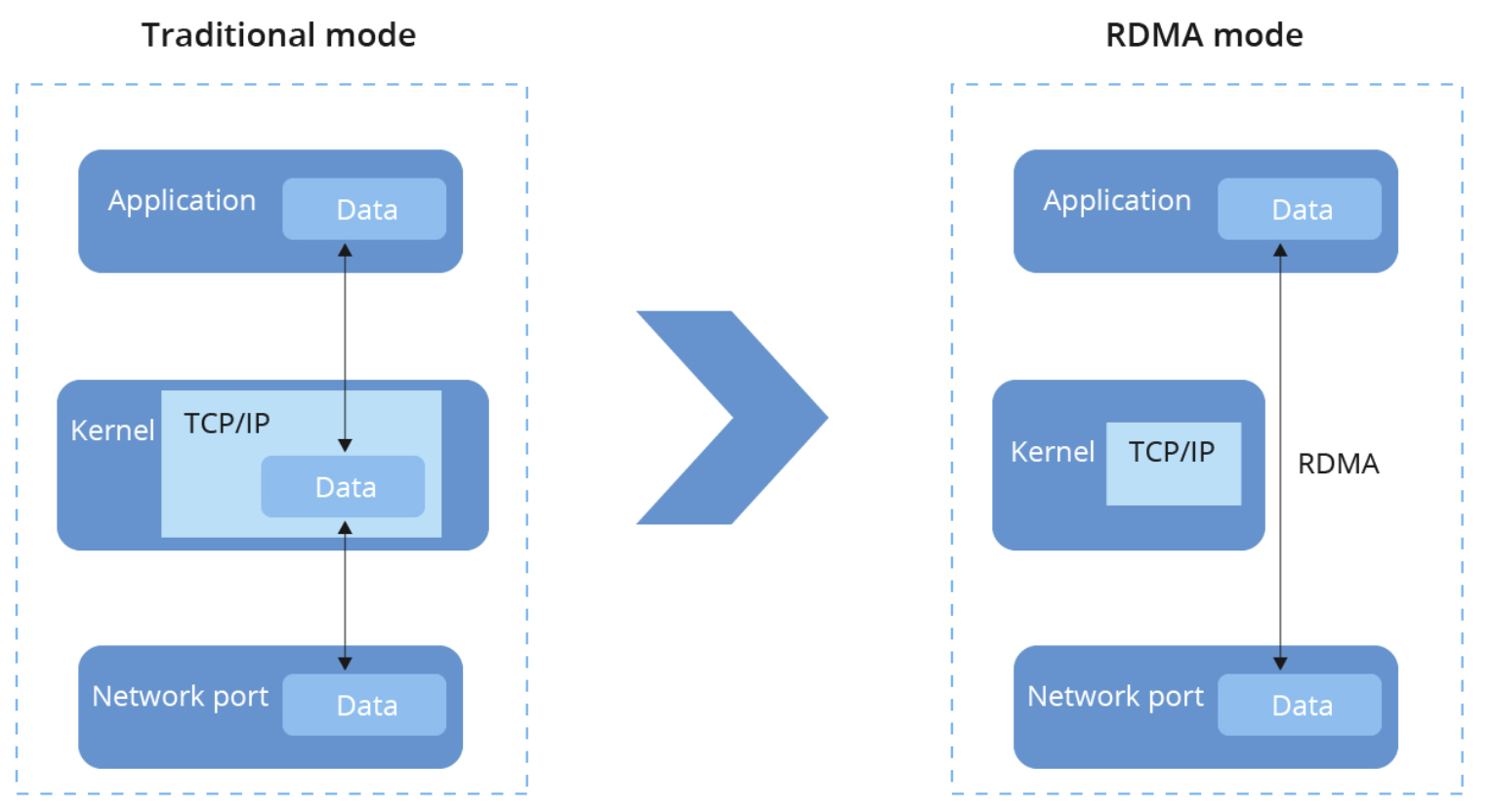
RDMA (remote direct memory access)
The general concept here is that applications (i.e. databases using NVMe) and devices (i.e. NVMe drives) read and write to network card memory buffers directly, bypassing the kernel's network stack.
The available RDMA network technologies are based either on InfiniBand or Ethernet networks. InfiniBand is an L2 network standard mainly developed by Nvidia. RDMA is a standard defined feature of InfiniBand, in contrast to Ethernet which does not support RDMA directly.
The design of InfiniBand is mainly focused on allowing HPC data center networks and can be characterized by high throughput, low latency and QoS features. InfiniBand uses its own link, network, and transport protocols (differing from Ethernet, IP, and TCP respectively). In IB networks, RDMA packets are sent over IB Transport. Due to the limited set of vendors for InfiniBand network devices and NICs, an Ethernet-based approach is desirable. But in order to enable RDMA, the network fabric must provide lossless transmission. This is not guaranteed by the standard Ethernet and requires enhancements, or usage of an upper layer transport protocol. Since the modern approach to networks is very elastic, with support from hardware vendors it’s possible to achieve this goal.
In terms of noteworthy implementations, there are:
- RDMA over Converged Ethernet (v1 and v2) and iWARP. All differ slightly in transports used (and consequently characteristics).
- RoCE v1 uses IB network layer packets over the Ethernet network; this means that the packets cannot be routed since no IP encapsulation is used.
- RoCE v2 uses UDP on the network layer, allowing for packet routing on IPv4 or IPv6 networks. Thanks to this, the protocol is sometimes called Routable RoCE (RRoCE).
Both RoCE v1 and RoCE v2 utilize the approach developed on InfiniBand and require data center bridging (DCB) enhancements to the Ethernet protocol to guarantee lossless traffic and quality of service. - iWARP uses TCP, which provides inherent reliability, so no enhancements on the Ethernet layer are necessary. However, compared to RoCE, using TCP introduces more overhead and complex implementation (remember that the packets are handled in NIC once the connection is established).
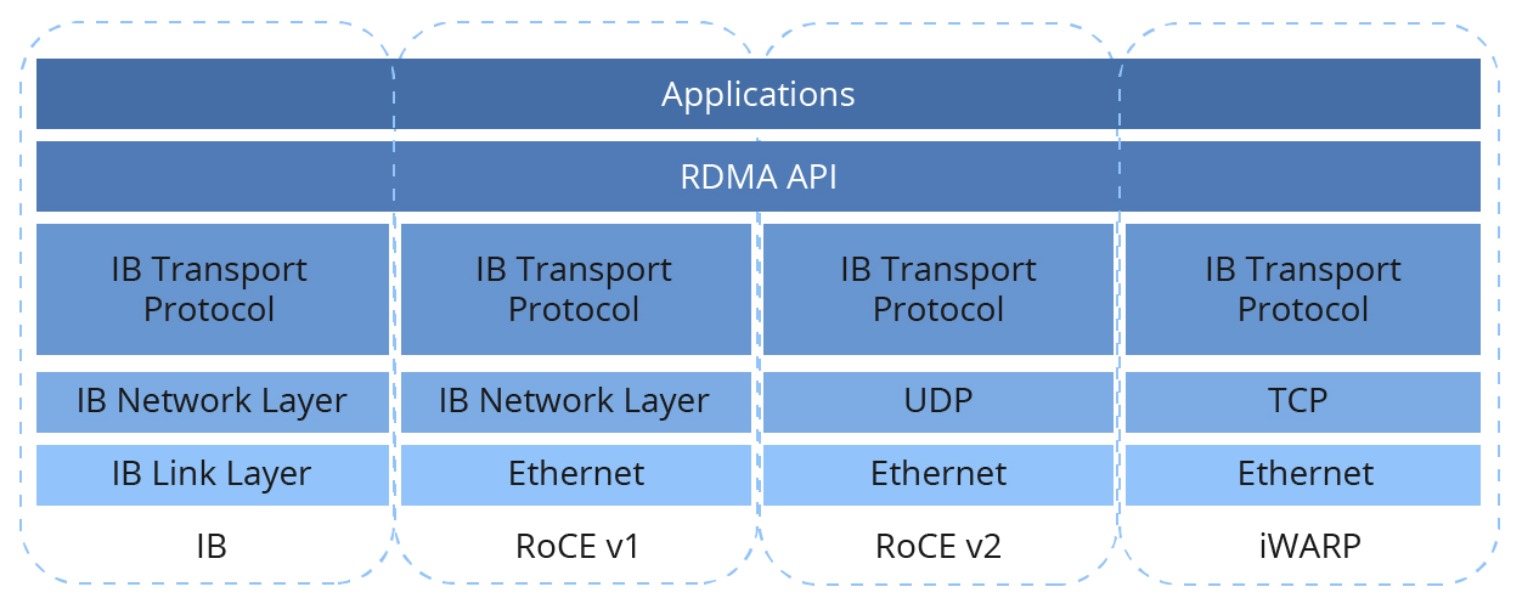
All of these technologies coexist and provide different benefits. Data centers usually utilize InfiniBand or RoCE to achieve top performance, and a dedicated cluster network is a viable solution. On the other hand, in deployments where DCB can be hard to configure or even when crossing public internet, iWARP is applicable and brings RDMA benefits.
Summary
NVMeoF is an evolutionary step from concepts introduced by SCSI specification. While the technology of the past proved to be dependable and useful, a widespread adoption of solid-state drives created a necessity for a better-suited protocol. Direct comparison of protocols itself can be cumbersome since the applications differ, and so finding a single device supporting NVMe and SCSI over RDMA is troublesome. Nevertheless, NVMeoF is a leading technology for the SAN networks of today, regardless of the transport used.
In the near future, we will take a deeper dive into RDMA technology, its implementations and performance impact, so stay in touch!


