


How P2P DMA between an NVIDIA BlueField-2 DPU and a GPU lets a machine learning model inspect every HTTP request, while the host CPU sits idle.
For decades, the CPU has been the middleman of computing. Every packet, every inference, every byte moving between devices passed through it. However, as CPU resources become more valuable, luckily for us, that assumption is now optional. This article walks through a proof of concept built by CodiLime in which a DPU and a GPU cooperate to run an AI-based web application firewall entirely between themselves. Packets arrive at the DPU, get inspected by a machine learning model on the GPU, and are handled however the application demands: dropped, forwarded, watermarked, or otherwise transformed, all on the DPU itself. All while the host CPU is never involved in any of it.
It's also a window into a kind of AI engineering that rarely makes the headlines. Most AI conversation today is dominated by generative models: chatbots, copilots, agents orchestrating other agents. The work here is different. A transformer-based classifier wired directly into the data path of a network device, with memory buffers, DMA semantics, and GPU scheduling designed so that the CPU is free to do other things. It's the kind of problem where ML expertise alone isn't enough, and neither is systems expertise alone. You need both, in the same room.
*This article is for network architects, security engineers, and platform teams evaluating how to add ML-based traffic inspection without sacrificing host compute, or who simply want to see what becomes possible when smart peripherals talk to each other directly.*
The problem: AI inspection is powerful, but the round trip is expensive
A web application firewall has one job: look at incoming requests and decide which ones are hostile before they reach the application. Traditionally, that decision came from static rules. Nowadays, machine learning allows you to do so much more. A trained model can recognize attack patterns like SQL injection in ways that rule sets struggle to, and it can generalize to variants it has never seen.
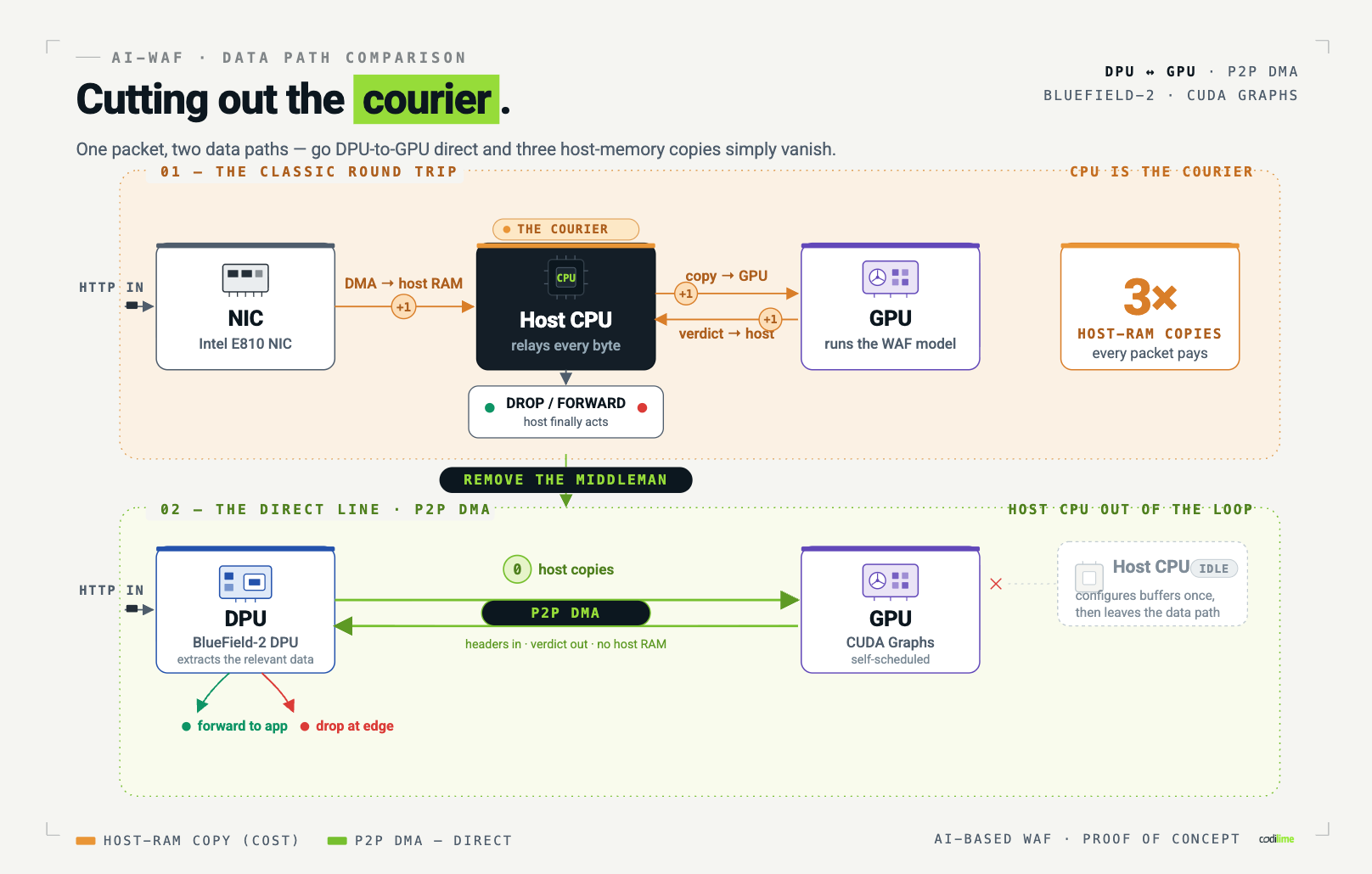
But ML inference wants a GPU, and that's where a classic setup starts to creak. In a conventional setup, every packet takes a scenic route: the NIC hands it to the host CPU, the CPU copies it to the GPU, the GPU runs the model, the verdict travels back to the CPU, and only then does the packet get dropped or forwarded. Every hop is a memory transfer. Every transfer costs latency. And the CPU, your most expensive general-purpose resource in the box, spends its cycles playing courier between two devices.
A question worth asking yourself becomes, if the DPU can process packets and the GPU can run the model, what exactly is the CPU still doing in the middle?
The architecture: a DPU, a GPU, and a direct line between them
The proof of concept removes the middleman using three building blocks.
NVIDIA BlueField-2 DPU. A data processing unit is a network card with a brain. In this case, an onboard ARM CPU purpose-built for packet processing. Sitting at the edge of the system, closer to the wire than any host processor, it receives traffic, parses it, and runs the firewall control logic itself. Crucially, unlike a regular NIC, a DPU can preprocess packets; it extracts just the HTTP header, which is the part the model actually needs, instead of shipping entire packets across the PCI bus.
A GPU running the WAF model. The classifier is mobilebert-sql-injection-detect, a transformer model tuned to spot SQL injection in HTTP requests. The interesting part isn't the model; it's how it runs. Using PyTorch's CUDA Graphs support, the entire computation is captured as a graph that the GPU schedules and launches on its own. No CPU thread sits in a loop dispatching inference jobs. Data lands in GPU memory, the model runs, results appear, and all of it self-managed on the card.
P2P DMA as the connective tissue. Peer-to-peer direct memory access lets two PCI devices read and write each other's memory without staging anything through host RAM. The DPU writes extracted HTTP headers straight into shared GPU buffers, then reads the model's verdict back the same way. The host CPU configures these shared buffers once, at initialization, and from that moment on, its work is done.
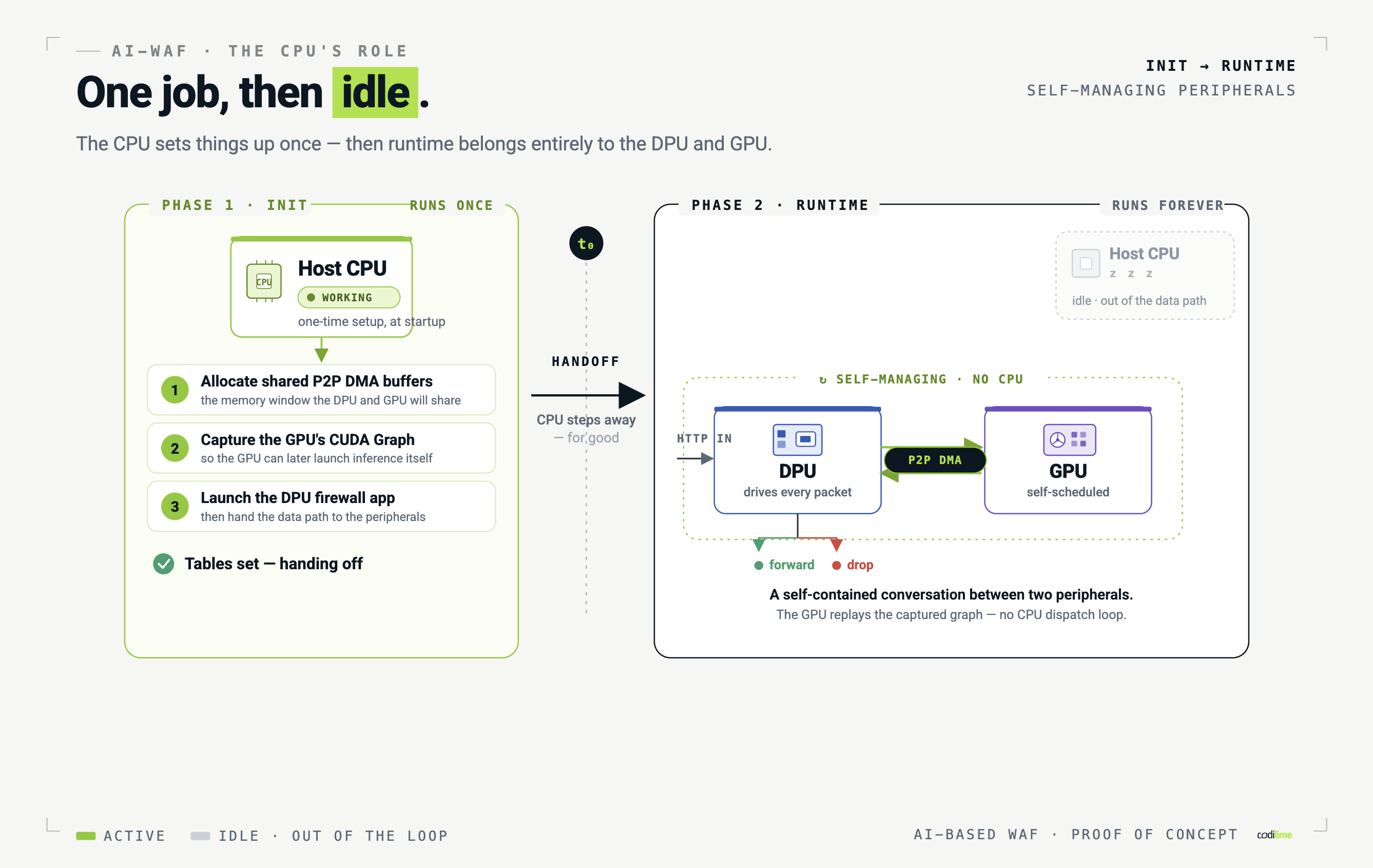
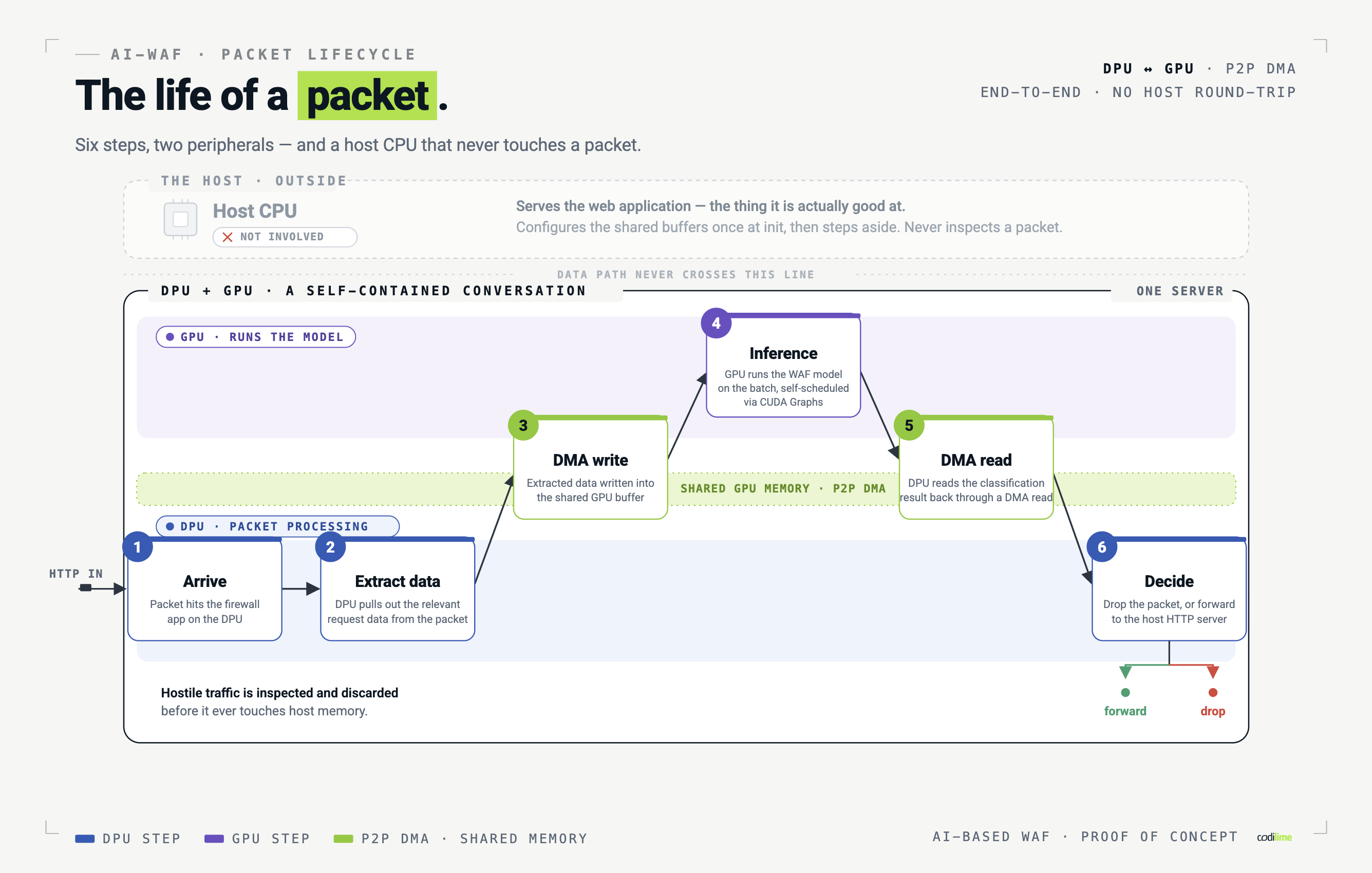
What a packet's life looks like The full path, end to end: A packet arrives at the firewall app running on the DPU. The DPU extracts the relevant request data from the packet. The extracted data is written via DMA directly into the shared GPU memory buffer. The GPU runs the WAF model on the incoming batch, scheduled by the GPU itself, via CUDA Graphs. The DPU reads the classification result back through a DMA read. Based on the verdict, the DPU drops the packet or forwards it to the host HTTP server. Notice what's absent from that list. The host CPU appears nowhere. It serves the web application, the thing it's actually good at, while the firewall runs as a self-contained conversation between two peripherals. There's a security bonus here too: hostile traffic is inspected and discarded before it ever touches host memory, isolating the system from the very data it's filtering. And because the DPU forwards only the slice of each request the model needs, rather than every byte on the wire, it shrinks PCI traffic between the two devices, winning on bandwidth and latency at the same time. How much of the request the model inspects is itself a design choice: the proof of concept focuses on a defined portion of the request, and extending that scope up to and including encrypted application traffic is a matter of expanding the same workflow rather than rethinking it.
Beyond the proof of concept
The PoC was built around one model and one attack class, but the architecture doesn't care. Any model whose input can be filled by the DPU through memory operations could slot in. CodiLime's team sees the natural next step as a framework: a programmable layer that lets engineers pair ML models with DPU-based preprocessing without rebuilding the architecture each time.
The preprocessing idea has more room to run as well. With mechanisms like DOCA Flow, the DPU could act on entire traffic streams by recognizing an attack once, then blocking the whole flow in hardware rather than classifying packet after packet.
And the pattern generalizes past networking. The same P2P DMA principle could move data disk-to-NIC for content delivery, mirror traffic NIC-to-disk for training data collection, or cache GPU inference results directly on storage. Anywhere the CPU is merely shuttling bytes between smarter devices, it's a candidate for removal from the loop.
Why this matters for businesses thinking about AI
Most teams adopting AI for infrastructure are integrating models at the application layer, like calling an API, deploying a container, or wiring an inference server into the stack. That works, but it competes on a layer where everyone has the same tools.
Building what's described here demands a rarer combination:
- Selecting and adapting ML models around hard deployment constraints like memory layout, batching, input formats, a DPU can write directly
- Deep fluency in DPU programming, GPU scheduling internals like CUDA Graphs, and PCI-level data movement
- Hardware-software co-design across the full path, from packet parsing to tensor buffers
- Making it all hold up under real traffic, not just in a diagram
For telecom operators, cloud providers, cybersecurity vendors, and anyone building network infrastructure where every CPU cycle is accounted for, this depth is the differentiator. CodiLime has spent over a decade accumulating it, and the AI-based WAF is one demonstration of what it produces. The SYN flood detector running inside an FPGA SmartNIC is another. They are not the last.
The takeaway
The hierarchy that defined computing, with the CPU at the center, everything else taking orders, is being dismantled by devices smart enough to manage themselves. AI doesn't only live in chat windows and agent frameworks. Some of the most consequential AI engineering happening right now runs in the spaces between devices: a model on a GPU, fed directly by a network card, making security decisions while the CPU does something more useful. Building in that space takes teams fluent on both sides of hardware and software, and that fluency is exactly what separates the demos from differentiation.
Download the fully detailed, fully free ebook showing just how we did it.


