


This is the second article in the series AI/ML for networks. In this article we focus on the two classes of ML methods: classification and clustering. We also mention anomaly detection, which is an important topic in the context of network-related data processing where various classes of ML algorithms can be used. The first article of the series can be found here.
Classification
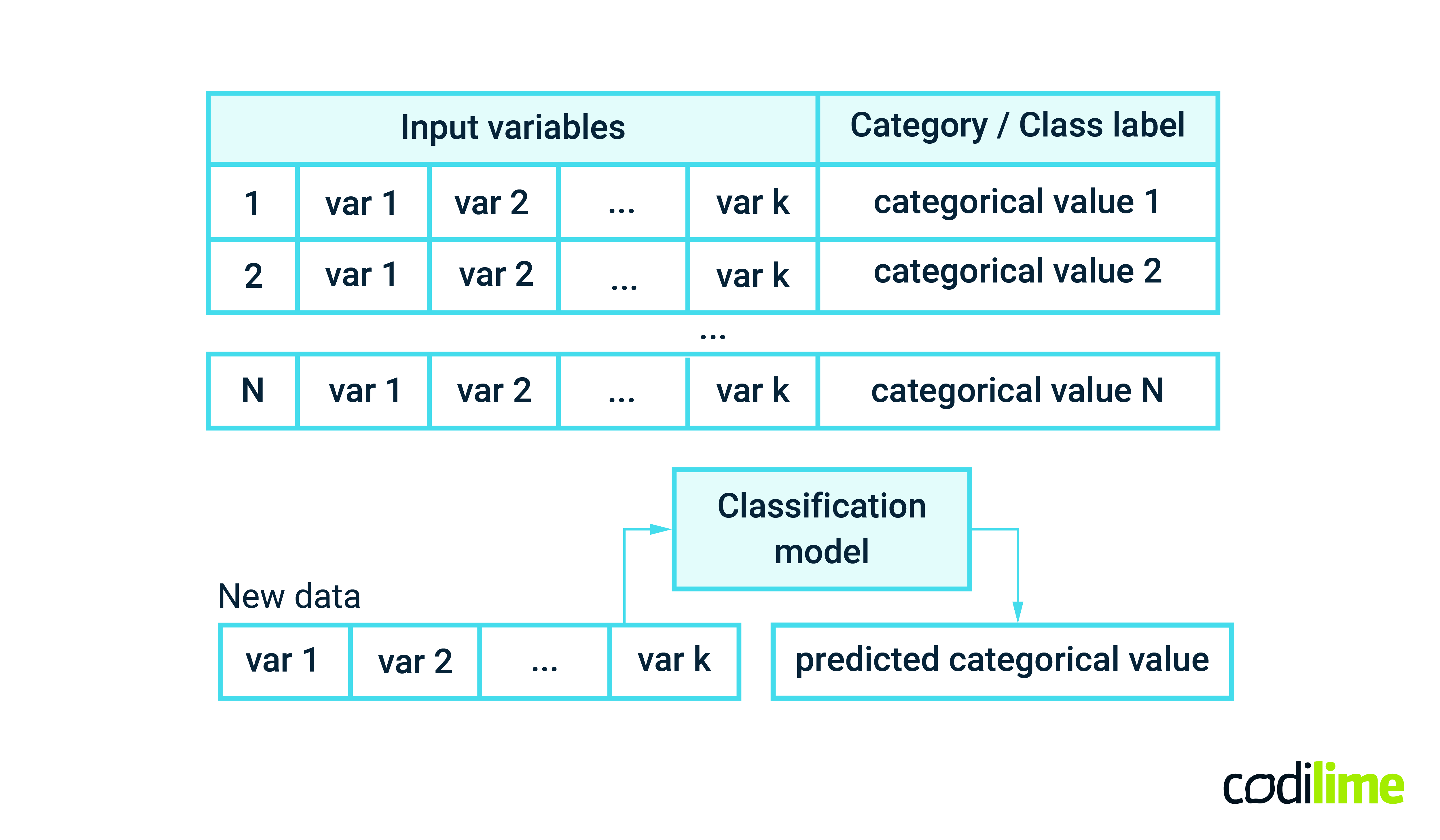
In machine learning, classification is a supervised learning problem of identifying to which category an observation (or observations) belongs to (see Figure 1). A category is often called a class label. Supervised learning means that both input variables (independent variables) and the output category (dependent variable) must be collected for the training process. The simplest example is classifying an email as spam/non-spam or a tweet as having positive or negative sentiment. These are examples of binary classification problems, as the class label can have only two values. When the number of classes is greater than two we are talking about a multi-class classification problem.
In a networking context, classification algorithms are often considered to distinguish different types of traffic such as video, voice or data and apply different routing or forwarding policies to them, for example. Also, classification methods can be used to distinguish various traffic categories such as “normal” traffic, bots, web crawlers and even attacks. Different traffic categories can then be handled in different ways or with different priorities. Automatic classification of users in terms of their behavior or traffic patterns is considered an important element of grouping them into classes and more efficient allocation of network resources, differentiating QoS and service offer or even targeted advertising.
The classification of alerts and trouble ticket data, in turn, can be used to prioritize tasks for administrators to identify the most critical in a given moment. Classification algorithms can also be helpful in analyzing logs of different device types and their performance indicators, classifying them as healthy or unhealthy.
An important usage of ML classification algorithms also takes place in the area of security. Detection and prevention of various types of attacks, such as malware infection, SQL injection and DDoS attacks are examples where trained classifiers can play a key role. Also, classification algorithms can help distinguish legitimate traffic from suspicious traffic, detect intrusion attempts of known attacks, and identify emerging threats.
Popular classification algorithms
Below a set of algorithms that can be helpful in solving the above-mentioned problems are listed.
- Logistic Regression

- Linear Discriminant Analysis
- Classification and Regression Trees
- Naive Bayes
- K-Nearest Neighbors (KNN)
- Learning Vector Quantization (LVQ)
- Support Vector Machine (SVM)
- XGBoost
The algorithms apply different statistical approaches, require different computation power to be trained, and are more or less resistant to occurrence of outliers in the data. The selection of appropriate algorithms is usually performed with an iterative experimental process. The final model accuracy is however strongly determined by the quality of properly labeled data. The process of data labeling can be expensive, especially when an automatic or semiautomatic approach is impossible in a specific use case.
Clustering
Clustering (also called segmentation) is a process of grouping similar entities into subgroups (clusters), where entities belonging to the same cluster are more similar to each other than to those of other clusters (see Figure 2). This is an unsupervised learning task, which means that it only interprets input data and finds natural groups taking into account feature space. Contrary to supervised learning, in unsupervised learning there is no output category or output variable.
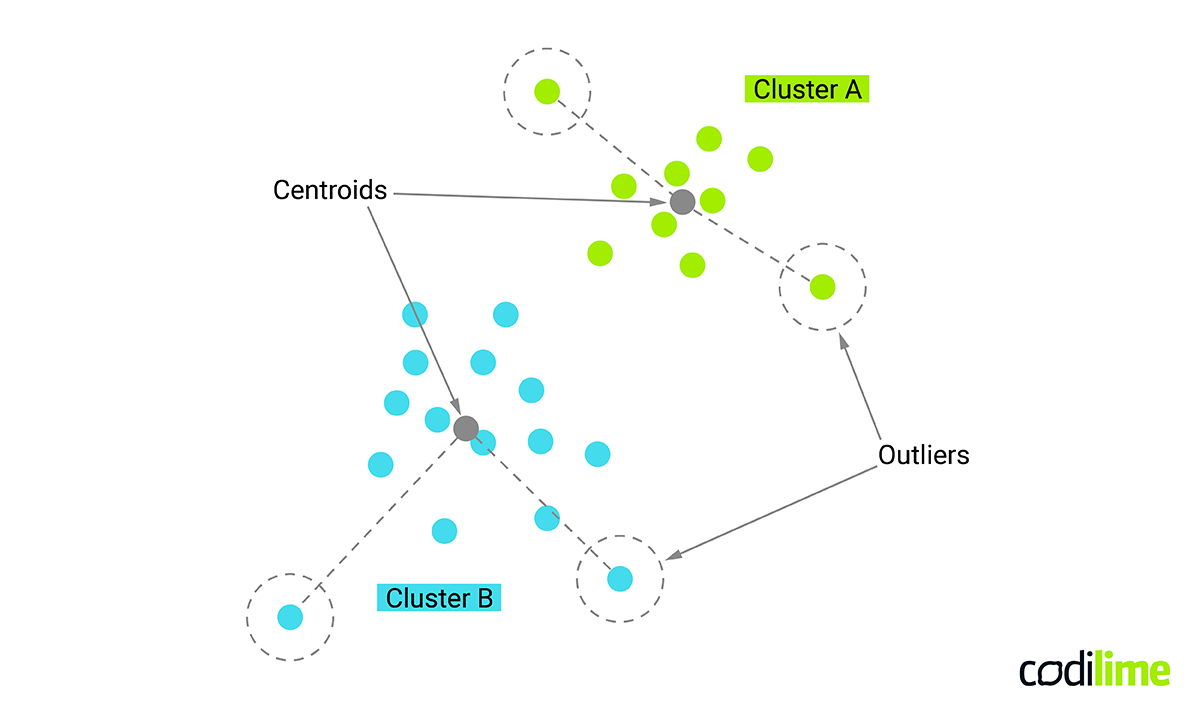
Each entity in a data set is described by numerical and categorical variables and a key point is to use the notion of a “distance metric” able to represent similarity between entities. In most cases the number of clusters is unknown a priori and evaluation of identified clusters is subjective. Clustering is a method for knowledge extraction by grouping data records that is difficult or time consuming, even for experts in the considered domain. However, a valuable clustering of particular data often requires tight collaborative work between a domain expert and a data scientist.
In the context of network/DC management, clustering can be used for analysis of trouble ticket data. Retrieval of data about each handled trouble ticket, such as the problem type, the customer, related infrastructure elements, number of involved engineers, handling time, keywords describing detailed technical issues, etc. is the first step in applying cluster analysis.
Analysis of proposed clusters and trouble ticket examples in each group allows you to gain useful knowledge, e.g. which groups of troubles took too much time to be served, which involved too many engineers, and which may indicate specific environment configuration problems (e.g. network routing) that seem to occur too often, and therefore need to be further analyzed and improved.
It is worth noting that a similar analysis can be done by querying prepared tabular data using SQL queries with ‘GROUP BY’ statements. Such an approach is often used, but the cluster analysis algorithms use a more holistic approach trying to find similarities taking into account features without imposing strict grouping criteria.
Another use case where cluster analysis could be used is the detection of anomalies. Many clustering algorithms use the notion of centroids, which describe the centers of the clusters. Such a centroid defines a typical or average representative of the group and the algorithms can also list outermost elements.
Being a little bit more practical, in the networking/DS management context, collection of configuration data for particular types of element (e.g. routers, switches, interfaces, firewalls, load balancers, applications, etc.) extended by recent operational statistics (performance counters, resource utilization, etc.) can be a good dataset for segmentation in the context of searching for those elements that are anomalies. Thus, there is a chance to discover some incorrect configuration of those elements leading to noticeable poor performance, potential vulnerabilities related to inconsistent settings, or applied policies. The general idea is to separate the potential anomalies, and examine why they are different from the rest of the other, similar elements.
Algorithms for cluster analysis
There are many algorithms for cluster analysis available. There are also some methods for assessment if the number of clusters is optimal for a given dataset. However, there is no clear theory as to which clustering algorithm best matches particular data or business objectives. Again, the key point is collaboration between a data scientist and a domain expert, who iteratively interpret the clustering analysis results for different experiments (for various sets of features and applied algorithms). Below is a list of the most popular algorithms utilizing different approaches for determining clusters.
- Affinity Propagation
- K-Means
- Agglomerative Clustering
- BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Mean Shift
- OPTICS (Ordering Points To Identify the Clustering Structure)
- Spectral Clustering

Here, you can check our data science expertise in practice.
Anomaly detection
Anomaly detection has already been mentioned several times in the previous sections. This section aims to clarify the terms related to anomalies and outliers when data is processed with the use of ML methods.
Anomaly detection in machine learning focuses on identifying data points or data patterns that significantly differ from the expected norm or behavior. Anomalies can be detected for structured data organized in a specific format (tabular data, XML, JSON, CSV, spreadsheet) and unstructured data (mail, post, document, audio, video, image). The characteristics of the data greatly influence the choice of specific techniques and algorithms.
Anomalies are often called outliers and the two terms are used interchangeably. They both represent unusual data points, however there is a significant distinction between them. The difference lies in the context in which they occur. Outliers are defined based on the distribution of the data, so they might be caused by natural variations. Anomalies are defined based on an expected behavior or norm. In practice, we would usually like to detect anomalies to diagnose potential problems and we would usually like to correct or remove outliers from data when we are preparing an ML model to increase its accuracy.
In the context of networking and DC management, detection of anomalies helps to ensure reliability and security. Anomalies in time series data representing various performance metrics can be quickly discovered compared to forecasted/expected values. The key point here is to define what should be treated as an important anomaly. For instance, in how many consecutive data points such differences occur and how much they differ from the forecasted values. Usually, only a domain expert can give valuable input defining which anomalies are important.
Also, classification models can be used to distinguish abnormal situations in the context of resource utilization. For instance, high CPU and memory utilization when the request rate is low for some services might indicate abnormal behavior that can be detected and the appropriate engineers alerted. Similarly, cluster analysis of configuration files can find repeating patterns, group them in terms of similarity, and indicate those files that do not belong to any cluster. Such a config file can be reviewed and modified when necessary. In the same way, trouble ticket data can be used to find tickets which were served too long, or engaged too many specialists.
Algorithms for anomaly detection
Below we listed a few ML-based algorithms that could be used for anomaly detection problems.
- Isolation forest
- One class SVM (one class Support Vector Machine)
- Local Outlier Factor
- KNN (K Nearest Neighbors)
- Gaussian mixture model
There are also other approaches, not necessarily based on ML techniques. What’s more, hybrid or multi-method approaches are very often used to increase anomaly detection accuracy.
Conclusions
In the second part of the series, we have presented two classes of ML methods: classification and clustering. We briefly described which data they work on and what they can produce as outputs. We suggested a few ideas for using them in the context of network and DC management and listed examples of the most popular algorithms. We also clarified the difference between the outliers and anomalies that are common when processing data using ML techniques.
In the next part, we will focus on two other classes of ML methods: natural language processing and reinforcement learning. Also, we will outline the major challenges that need to be taken into account when implementing ideas for applying artificial intelligence algorithms to network problems.


