


The significance of data cleaning is underscored by the principle of "garbage in, garbage out" in data analysis. This axiom highlights that the quality of output is determined by the quality of the input data. If the input data is flawed or of poor quality, the resulting analyses and decisions will be unreliable, potentially leading to costly mistakes and misguided strategies.
Clean data, conversely, ensures that analytics algorithms work with the most accurate and relevant information, leading to more trustworthy predictions and insights. It guarantees consistency across varied data sets, facilitating the integration and comparison of data from multiple sources.
Additionally, well-cleaned data streamlines data processing and analysis, enhancing efficiency and reducing resource expenditure. In this way, data cleaning is not just a preliminary task but a critical step in realizing the true value of data, empowering organizations and researchers to make informed, strategic decisions based on solid data foundations.
Understanding data quality
Data quality is a multifaceted concept that plays a pivotal role in the reliability and effectiveness of data-driven decisions. High-quality data is characterized by several key attributes: accuracy, completeness, consistency, and reliability. Accuracy refers to the precision and correctness of the data, ensuring it accurately represents real-world scenarios. Completeness is about having no missing elements and sufficient data for the task at hand. Consistency implies that the data maintains a uniform format, standards, and definitions across the data set. Finally, reliability means that the data can be trusted and is sourced from credible and authoritative origins.
To assess the quality of a data set, techniques like data profiling and exploratory data analysis are employed. Data profiling involves scrutinizing individual attributes to identify inconsistencies, anomalies, and patterns, while exploratory data analysis uses statistical summaries and visualizations to understand the data’s underlying structure and the presence of potential issues. Together, these methods provide a comprehensive view of the data’s health, guiding efforts to enhance its quality for more accurate and reliable analytical outcomes.
A process related to data cleaning is data wrangling. You can read more about it in our previous article.
>> Discover our data engineering services.
Handling missing data
Dealing with missing data is a complex but crucial aspect of data preparation, as the way missing values are handled can significantly impact the results of data analysis. Missing data generally falls into three categories:
- Missing completely at random (MCAR): Here, the missingness of data is independent of any other data, meaning the absence of data is completely random.
- Missing at random (MAR): In this scenario, the missingness is related to other observed data in the data set. The reason for the missing data can be explained by another variable.
- Missing not at random (MNAR): The missingness is related to the reason why it is missing, meaning the missing data is related to the unobserved data.
For each of these types, several strategies can be employed:
-
Imputation methods:
- Mean/median/mode imputation: Replacing missing values with the mean, median, or mode of the observed values.
- K-nearest neighbors (KNN) imputation: Using a KNN algorithm to predict and fill in missing values based on similar data points.
- Regression imputation: Utilizing regression models to estimate missing values based on relationships with other variables.
-
Deletion methods:
- Listwise deletion: Removing entire records that contain any missing values.
- Pairwise deletion: Using the available data while ignoring missing data during analysis, applicable in statistical calculations like correlation.
-
Algorithmic approaches:
- Expectation-maximization (EM): An iterative method to estimate missing data based on other available information.
- Random forest: Leveraging a random forest algorithm to handle missing values by finding the best fit from the observed portion of the data.
-
Advanced techniques:
- Multiple imputation: Generating multiple imputations for missing values and then averaging the results for analysis.
- Hot deck imputation: Substituting missing values with observed responses from similar respondents (or 'donors').
Each of these methods comes with its strengths and weaknesses, and the choice largely depends on the nature of the data, the pattern of missingness, and the specific requirements of the analysis. A nuanced understanding of these strategies is essential for effectively managing missing data, ensuring the integrity and reliability of the analytical outcomes.
Identifying and treating outliers
Outliers, or data points that significantly differ from the rest of the data, can greatly influence the results of data analysis and therefore require careful handling. Identifying outliers is the first critical step in this process:
-
Statistical tests: One common method is to use statistical metrics, like Z-scores or IQR (interquartile range), which help in identifying data points that deviate significantly from the mean or median of the data set.
-
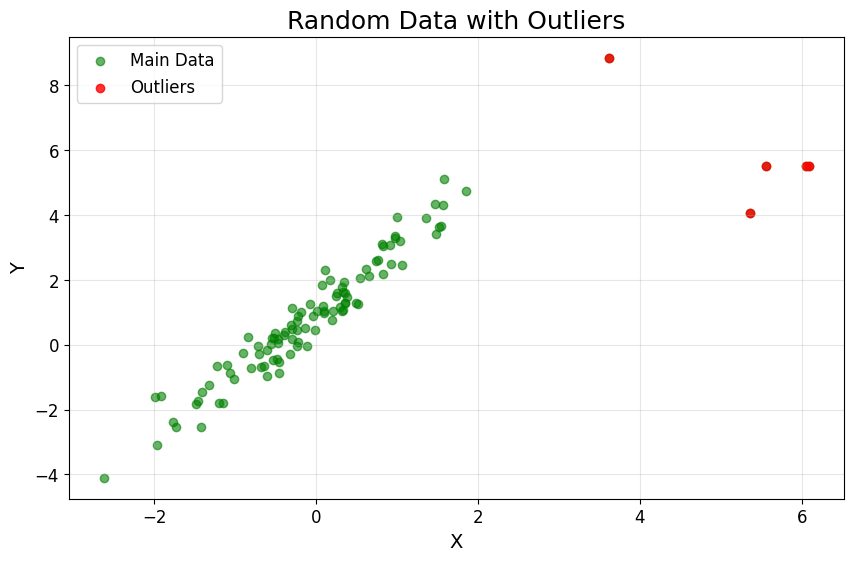
Visualization techniques: Visual tools like box plots, scatter plots, and histograms can be instrumental in spotting outliers. These plots make it easier to see points that fall far outside the typical range of values.
Fig.1: Random data with outlinersSource: Random data with outliners
-
Clustering methods: Algorithms such as DBSCAN (density-based spatial clustering of applications with noise) can identify outliers as points that do not fit into any cluster.
Once outliers are identified, there are several strategies to treat them:
- Removal: The simplest approach is to remove outliers, especially if they result from data entry errors or are not relevant to the analysis. However, care must be taken as this can lead to the loss of valuable information.
- Transformation: Applying transformations (like logarithm or square root) can reduce the impact of outliers on the analysis without removing them entirely.
- Separate analysis: In some cases, outliers are not just noise but signify important variations. Conducting a separate analysis for these outliers can provide additional insights.
- Capping: Outliers can be capped or a floor set at a certain value, thus limiting their effect.
It's crucial to understand the cause and nature of outliers before deciding on the treatment method. In some analyses, outliers hold significant importance, while in others, they may distort the results. The decision on how to treat outliers should be informed by the context of the data and the objectives of the analysis.
Ensuring data consistency
Data consistency is fundamental in data analysis. Inconsistent data can lead to incorrect conclusions and inefficient analyses. Two key approaches to ensuring consistency are standardization and normalization:
- Standardization: This involves aligning all your data with a common standard. For example, standardizing formats for dates, addresses, or phone numbers ensures that all data entries follow the same format. This is crucial when combining data sets from different sources to avoid mismatches and errors.
- Normalization: This refers to scaling numerical data to fall within a smaller, specified range, like 0 to 1, or to have a standard distribution. Normalization is essential in machine learning models, as it ensures that features contribute equally to the model's performance and prevents features with larger scales from dominating the model's decision.
In addition to these, dealing with duplicate data is another critical aspect:
- Identifying duplicates: Techniques like sorting data, using data profiling tools, or implementing algorithms can help in identifying duplicates. It's essential to distinguish between true duplicates and similar entries that are legitimately distinct.
- Handling duplicates: Once identified, duplicates can be handled in several ways. The simplest is deletion, where duplicate entries are removed. Another approach is consolidation, where multiple duplicate entries are combined into a single, comprehensive record. The choice depends on the context and nature of the data.
Ensuring data consistency through these methods not only improves the accuracy of the analysis but also streamlines the process, allowing for more efficient and effective data handling. It’s a crucial step in preparing data for any kind of analytical work, ensuring that the data is as reliable and useful as possible.
Data transformation techniques
Effective data transformation techniques are vital in refining raw data into a format that is more suitable for analysis, particularly in the context of machine learning and statistical modeling. Key aspects of data transformation include feature engineering, scaling, and encoding:
Feature engineering
This is the process of transforming raw data into features that better represent the underlying problem to the predictive models, thereby enhancing model performance. It involves creating new features from existing data, selecting the most relevant features, and even transforming features to expose new relationships.
This could mean, for example, converting timestamps into categorical features like "morning" or "evening," or creating interaction features that combine two or more variables.
Scaling
Scaling is crucial in situations where different features have vastly different scales.
- Min-max scaling: This method transforms features by scaling each feature to a given range, typically 0 to 1. It's useful when you need to normalize the range of features without distorting differences in the ranges of values.
- Standardization (Z-score normalization): This involves rescaling the features so that they’ll have the properties of a standard normal distribution with a mean of 0 and a standard deviation of 1.
Encoding Categorical Data
Many machine learning models require input to be numerical. Encoding categorical data is the process of converting categorical data into a numerical format.
- One-hot encoding: This creates new columns indicating the presence of each possible value from the original data. For instance, a feature with three categories ('red', 'blue', 'green') can be converted into three features, each representing one color.
- Ordinal encoding: This is used when the categorical variable has a known order. In ordinal encoding, each unique category value is assigned an integer value based on its order.
These techniques are fundamental in data preparation, ensuring that the data fed into models is in a form that is most conducive to analysis. By appropriately transforming data, models can learn more effectively, leading to better predictions and insights.
Advanced cleaning techniques
As data volumes and complexity grow, advanced cleaning techniques, particularly automation and machine learning, are becoming increasingly important for efficient and effective data management. These advanced techniques can significantly enhance the data cleaning process:
-
Automating data cleaning:
Automation in data cleaning involves the use of tools and software to streamline the cleaning process. These tools can automatically detect and correct errors, handle missing values, and even standardize and normalize data. For instance, data cleaning software often comes with features like pattern recognition for identifying inconsistencies or anomalies, rules-based systems for correcting common errors, and batch processing for handling large volumes of data efficiently.
Automation not only speeds up the process but also reduces the likelihood of human error, making the cleaning process more reliable and consistent.
-
Machine learning for data cleaning:
Machine learning can be leveraged to further refine the data cleaning process. Techniques include:
- Anomaly detection: Machine learning models can be trained to identify outliers or anomalies in data, which can be indicative of errors or exceptional but important cases. These models analyze the data’s patterns and flag deviations, which can then be reviewed and handled appropriately.
- Predictive modeling for missing data: Machine learning can also be used for imputing missing values. Predictive models can analyze complete parts of the data set to predict missing values with a high degree of accuracy, based on the patterns observed in the rest of the data.
These advanced techniques represent a significant step forward in data cleaning, offering more sophisticated, efficient, and effective methods for ensuring data quality.
By incorporating automation and machine learning into the data cleaning process, organizations can handle larger data sets more efficiently while maintaining, or even improving, the quality of their data analysis.
Conclusion
To summarize, data cleaning is a fundamental aspect of data analysis, crucial for accuracy and reliability in decision-making. This article covered key components like ensuring data quality, addressing missing data and outliers, and the importance of data consistency through standardization and handling duplicates. We also explored transformative techniques like feature engineering and advanced methods of automating data cleaning and employing machine learning.
Looking ahead, the field of data cleaning is evolving with trends like AI-driven tools and real-time data processing in big data and IoT contexts. These advancements are set to enhance efficiency and precision in data cleaning, further underscoring its critical role in extracting meaningful insights from data.
In essence, data cleaning is an indispensable part of the data analysis process, ensuring that the insights derived are based on solid, reliable data. All of the above tasks can be performed with ETL/ELT pipelines – if you want to learn more about these solutions, you can read our article about ETL vs. ELT.


