


When we talk about data warehousing, we think of databases, which is only half of the solution. Data must be stored - this is why we need a database. But data must also be delivered into the database from a source. This is where ETL/ELT comes into the equation.
What is a data warehouse?
Let's briefly explain what a data warehouse is and why we need one. It is a system used for storing and reporting data. Due to their design, data warehouses can process huge amounts of data, making lots of information available for business analytics. This information can be sliced and diced to show all possible angles. This processing of data is a crucial part of a bigger process called business intelligence, which is a part of an even bigger idea called ‘data-driven business’. You can read more about big data in or previous article.
But let's get back to our subject ETL vs. ELT.
ETL - what is it?
To understand what ETL is, let’s take a look at a simple example.
You are the owner of a supermarket and you want to sell potatoes to your customers. You need to find a supplier for these potatoes, so you call a local farmer. The farmer is happy to sell you his produce, but he doesn't have a lorry to transport them or the resources to pack them into nice paper bags with your logo. So you need to find a company that will collect the potatoes from the farmer, pack them, and deliver them to your store.
This, in essence, is the ETL process: extract, transform, load.
In an ETL pipeline, loading and transformation are done outside the main warehouse.
It could be a simple Python script executed once per day to pick up new CSV files, extract raw data, change the date to ISO format, clean white spaces and subtract the cost from revenue to create a new value for the income column. It could also be a much more complex transformation. The point is, ETL is done outside the database, and it is done by a separate computing unit.
So, what is ELT?
Let's go back to our example to explain the ELT.
Customers love your way of selling potatoes, and they want more: carrots, parsnips, onions, and much more. But you face a few problems: your delivery company is too small for the additional load. So either you find a bigger company or hire additional, smaller companies to take care of the new vegetables. Also, your store is too small, so you will have to rent a much bigger space.
Now you realize that you can manage the washing and packaging as well. You can also do it much more efficiently because your new store has been designed to handle large amounts of vegetables - which represent data in this example.
So now someone is delivering you vegetables in big batches, and you are transforming them and presenting them to the client. So ELT - extract, load, transform.
In the ELT pipeline, extracted data from your CSV file is loaded to the table, and then an SQL query transforms it. The SQL query can also join data with other data and then deliver it to further stages of your warehouse.
ETL vs ELT - pros and cons
To summarize so far, we have two pipelines: ETL, where loading and transformation are done outside the data warehouse, and ELT, where you use your own resources to extract, load and transform the data.
I guess you might be confused now, and have questions like, which solution is better: ETL or ELT? or Which one should I use? The answer, as always, is “It depends”.
Pros and cons of ETL
Pros
- Database’s computational power is not used for transformations
- Data stored in its transformed state - less storage spacestru used, all nice structured tables with PKs
- All types of transformations can be done (number of languages, libraries, etc.)
Cons
- Slower load time
- Data orchestration can be a challenge
- Difficult to build one-language pipelines
- Require additional resources to compute transformation code
Pros and cons of ELT
Pros
- Faster load time as no extraction is required
- Simpler solutions - the whole warehouse can be built with only one language (SQL)
- Can utilize massive computing power (BigQuery, Snowflake, Redshift) and SQL is much more efficient with JOINs
- Easier data orchestration
Cons
- Uses warehouse computing capacity
- Not all transformations can be done using SQL
- Storing raw data is very often messy and requires more space (no PK, both structured data or unstructured data, etc.)
In the big picture, you need to deliver computing power to extract and transform your data in both solutions. You also need storage capacity, but this should be solved easily with the database.
But should we transform our data outside or inside the warehouse? Pipelines should be tailored to the circumstances.
To understand which pipeline works better for which situation, let’s take a look at three examples.
ETL - Extract, Transform, Load example
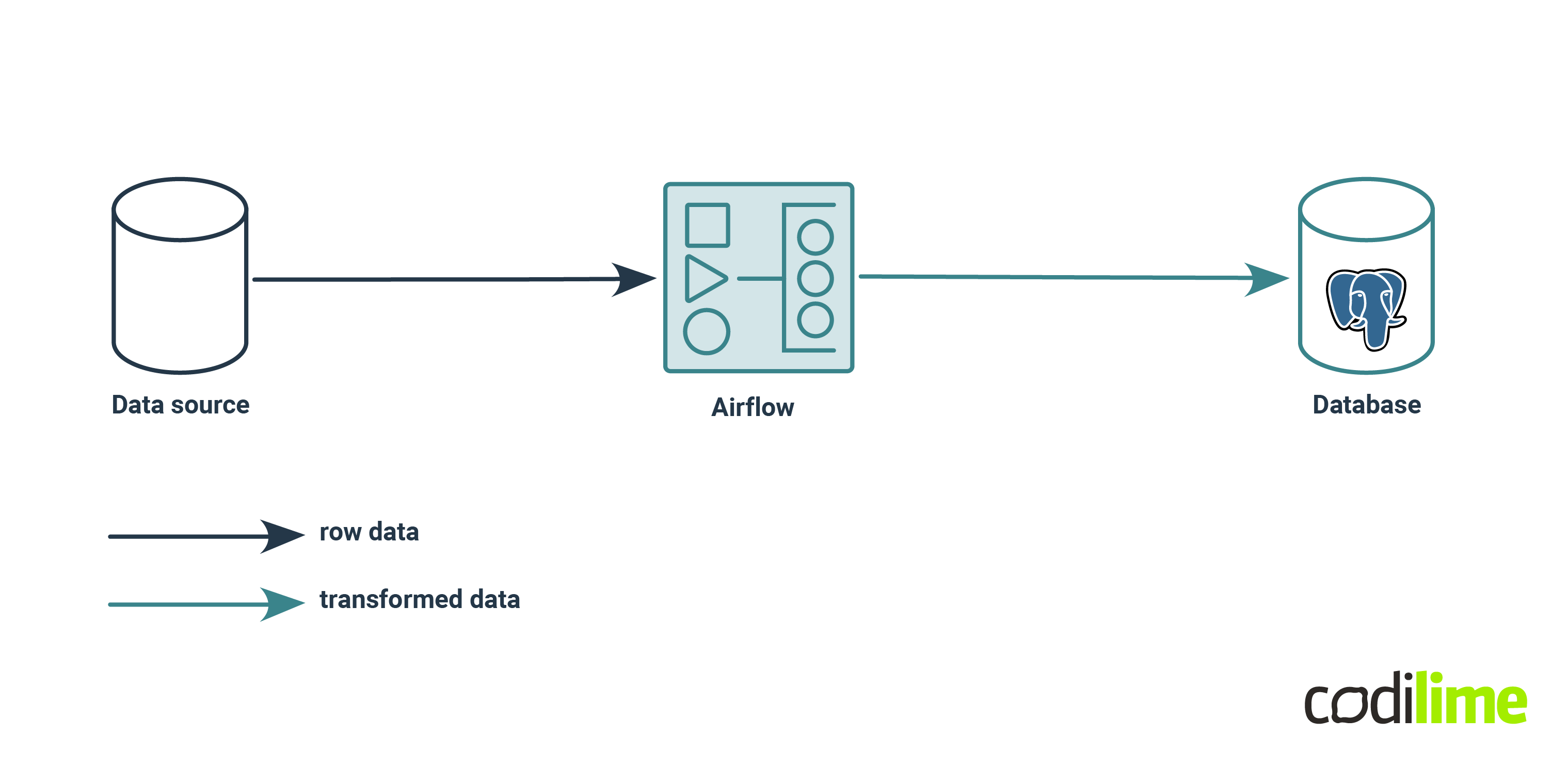
In the first scenario, Postgres is running on a cheap EC2 machine with limited computing power. The amount of data is low and needs to be extracted once per day, so it makes lots of sense to use another EC2 to run Airflow which will handle extraction, transformation and loading data to Postgres. Obviously this solution requires two EC2 machines and two languages - Python and SQL. That’s lots of code and maintenance but it can be very cost effective.
ELT - Extract, Load, Transform example
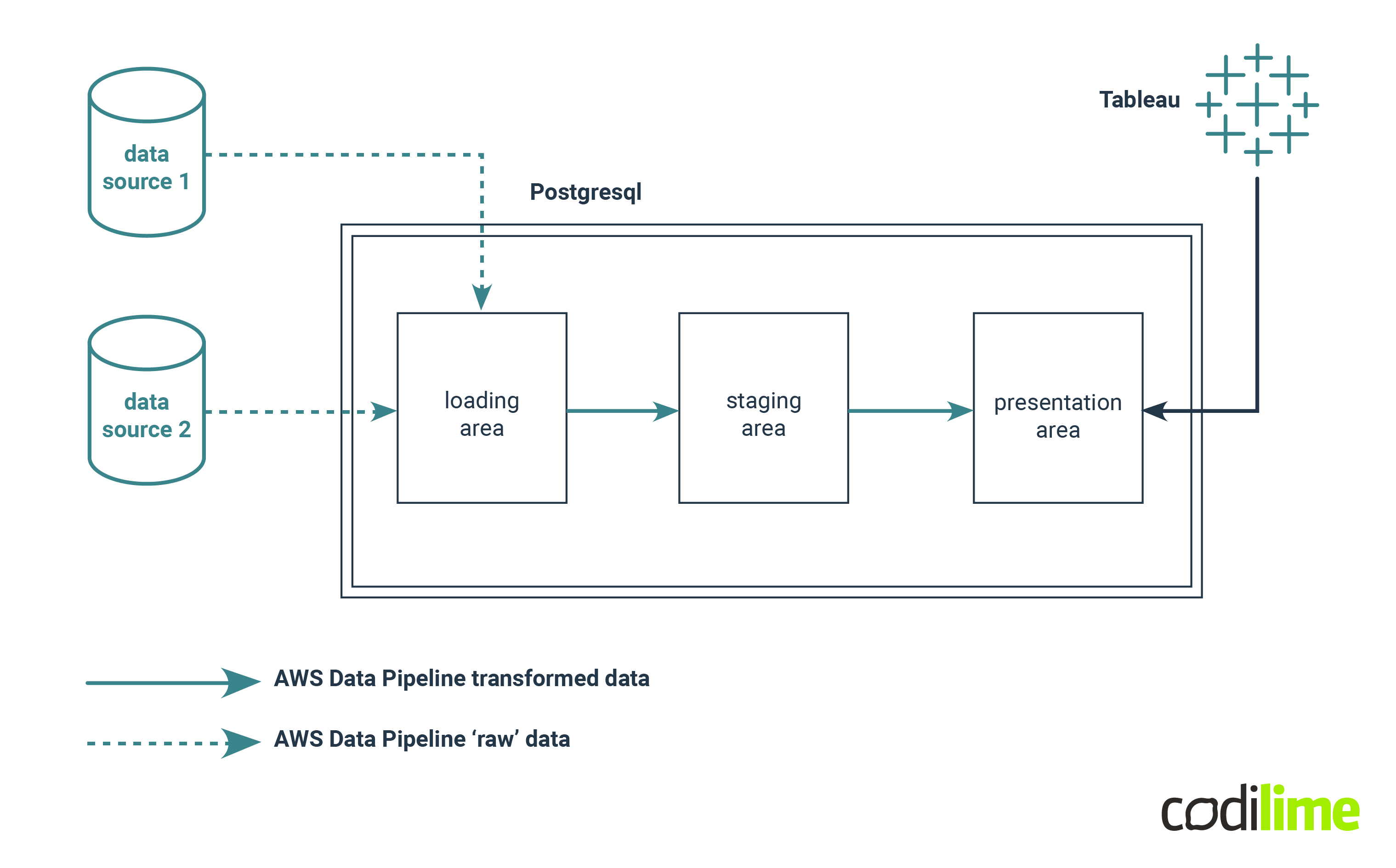
Let’s look at an example of the ELT process. In this case, we have a data warehouse built in Postgres, data orchestration is handled by AWS Data Pipeline, and the final user is using Tableau to build analytical reports.
The loading area is a table without a complex schema, probably just varchars to avoid issues with raw data. An SQL script executed by a data pipeline is responsible for cleaning and loading clean and transformed data to tables in the staging area - where the schema is very precise (data type, PKs, etc.), then another SQL script joins inserts it into tables in the presentation area.
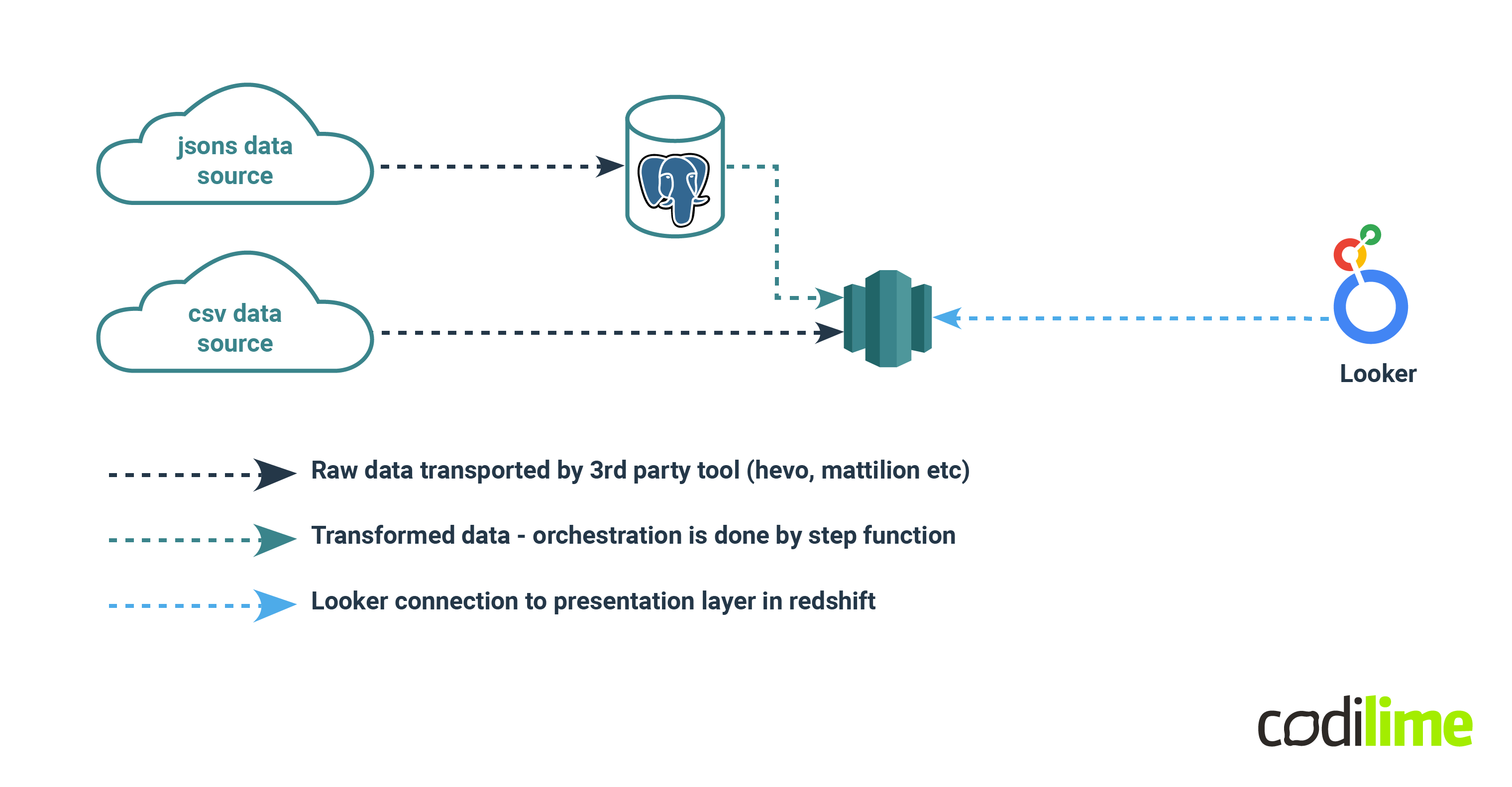
Real life scenario
In real life, we use both approaches - ETL and ELT - as we see fit. Data should be delivered on time, in the simplest possible way to minimize the risk of error.
Let’s have a look at a real life scenario. We have two data sources: one with complex JSONs and another with simple CSV. The data warehouse is Redshift, and the business intelligence tool is Looker.
We are trying to avoid JSON extraction in Redshift as this database is not the best for extracting JSONs. Instead we will use a small Postgres instance (Postgres has excellent JSONsupport - JSONB format, indexing and very smooth syntax). After extracting data from JSON, we can join this data with other JSON data and then insert it into the table in Redshift, where CSV data users can then build their reports in Looker.
In this situation both ETL and ELT are applied. When the data is processed by JSON and then transferred to Redshift, it’s ETL. In the case of raw data coming straight into the warehouse, it’s ELT.
Technology
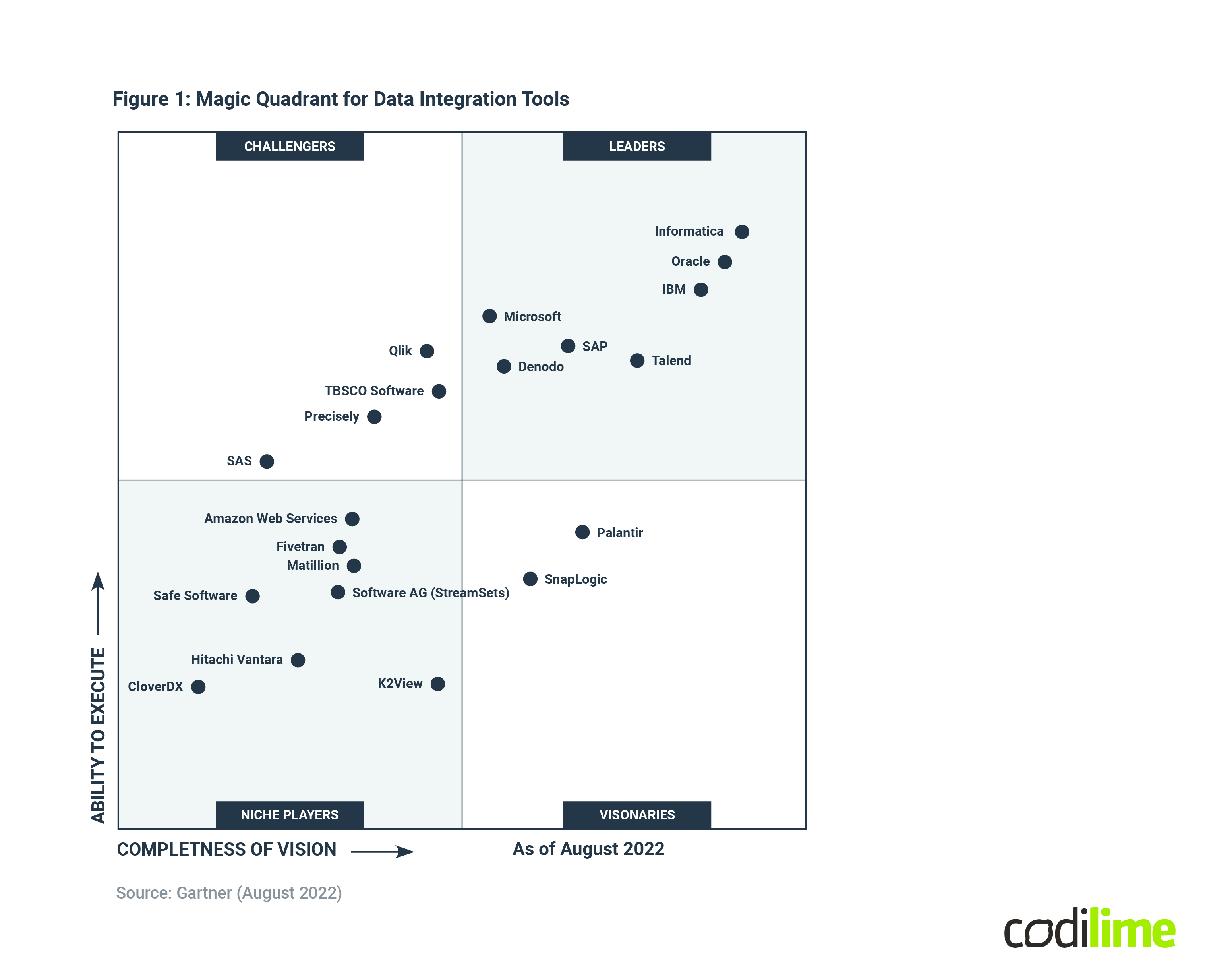
The market leaders are well known - Informatica, Microsoft, IBM - but more interesting are the visionaries and niche players. AWS, Fivetran or Hitachi Vantara are much more cloud-based than their bigger and more popular competitors. We can say that the future of ETL/ELT obviously lies in the cloud, which leads us to questions about complicated legal matters such as GDPR, data ownership, etc. which we will not address in this article.
If you want to learn more about data engineering tools, check out our previous article.
Conclusion
As you can see, if you have asked yourself the question which one is better - ETL or ELT - then there is no single answer. You have to design your pipelines to utilize the strong points of your architecture - either it is an excellent database engine or you use tools like Spark or Airflow. Also, it is extremely important to understand the data you are working with and - most importantly - understand and meet user needs.


