

We've previously explained how VPP processes packets in vectors as opposed to processing each packet end to end. But how is this processing spread across CPU cores? How exactly is a vector of packets structured? We'll try to answer these questions in this blogpost.
We'll also explain where the memory for packets comes from, how it's managed, and what optimizations VPP employs to achieve its performance – VPP has more tricks up its sleeve, not only the processing packets in vectors. We’ll also discuss some related topics like commands and stats architecture.
While this article is more on the technical side (rather than practical) and would mostly benefit VPP contributors or plugin authors, it's always good to know how the software works under the hood. We also try to present some more practical conclusions at the end.
Threads
Threading model
VPP supports two modes of operation – single-threaded and multi-threaded. In the former, a single thread is tasked with processing events, commands, and the datapath. While this is, sadly, the default, we’ll focus on the multithreaded scenario. In such a scenario, VPP runs a single main thread and multiple worker threads. The main thread's responsibility is processing commands and other miscellaneous events, while the worker threads’ sole responsibility is polling the input queues of network devices.
Each of the threads is pinned to a particular CPU core at startup. E.g., the following configuration:
cpu {
main-core 0
workers 2
}
This configuration uses core 0 for the main thread and cores 1 and 2 for the worker threads. You can use vppctl show threads to show the current thread configuration. To tweak the thread-core assignment, use the corelist-workersoption. We won't explain the details here, as it's already pretty well documented in /etc/vpp/startup.conf.
VPP generally attempts to minimize inter-thread communication – e.g. all the necessary processing steps for a packet usually occur within a single worker thread.
Workers threads and interfaces
On startup, VPP assigns interfaces to worker threads. Or, more precisely, RX queues to worker threads – an interface may support polling from multiple queues.
By default, VPP assigns RX queues to worker threads in a round-robin fashion. This is usually appropriate for a single NUMA-node setup. If you're running a system with multiple NUMA nodes, it's important to check the interface placement (vppctl show interface rx-placement) and provide manual configuration if the interfaces are assigned to threads on the wrong NUMA nodes to avoid performance degradation.
Since most of the drivers you'll encounter are poll-mode-drivers (such as when using the DPDK input plugin or e.g., memif interface), any worker thread that has any interfaces assigned will have 100% CPU utilization. The main thread usually has a few % of CPU utilization.
As with multiple RX queues, multiple TX queues for a physical interface are also possible. But we'll return to this topic after a short break on memory management. We'll also try to answer the question, "When does a packet cross a thread boundary?"
Memory
We'll focus on memory allocated for packets, as that's the most important part of allocated memory. We'll skip discussing other types of memory allocation in this article.
The memory for packets is allocated as one contiguous block of virtual memory. VPP tries to make this block as contiguous as possible in physical memory by leveraging hugepages. You can use commands such as vppctl show memory map (or various other show memory subcommands) to inspect the memory mappings.
The block of memory is accessible via a buffer pool (vlib_buffer_pool_t) (more precisely, one pool per NUMA node). The memory is split into buffers, laid out contiguously. A packet consists of either a single buffer or multiple buffers If a packet doesn’t fit in one, multiple buffers can be chained to represent a single packet. Each buffer consists of a header part followed by the data part. The default size of buffer data is 2kB. That, combined with headers (we’ll explain why “headers” are in plural later) and some “pre-data” (space for prepending headers), makes it into about 2.5kB per allocation. The default configuration of 16k buffers per NUMA node results in about 40MB allocated for buffers on each node. You can inspect these sizes and numbers of buffers via vppctl show buffers. It’s possible to bump these defaults, but it should be necessary only when having a large number of interfaces or threads.
The memory pools are, in principle, threadsafe (they're protected by a spinlock), but as an optimization, each thread has its own cache within a pool with up to 512 entries per thread, so in the usual case, no thread synchronization is needed. It’s worth noting that grabbing buffers from this cache is a really fast operation. There are no linked lists involved here. Free buffers are stored as indices (more on indices themselves later) in an array. Therefore, grabbing even a whole vector of buffers is usually just a matter of a check, a subtraction, and a memcpy.
Note: Buffers that would cross page boundaries are not used, for such a buffer, we cannot use DMA as we don’t have a guarantee its backing physical memory would be contiguous. Thanks to the usage of hugepages, the number of such wasted buffers is minimized (with 4k pages, and default 2k data size, more than half the buffers would be wasted!). That’s not the only benefit from hugepages – they greatly reduce the TLB pressure.
Optimizations
Obviously, the biggest optimization that gives VPP its performance is processing packets in bunches (called vectors), which greatly improves the performance of the instruction cache. We won’t cover it in this article as we already have in our previous blog post, but there are various other noteworthy micro- (or not-so-micro) optimizations that VPP does for packet buffers.
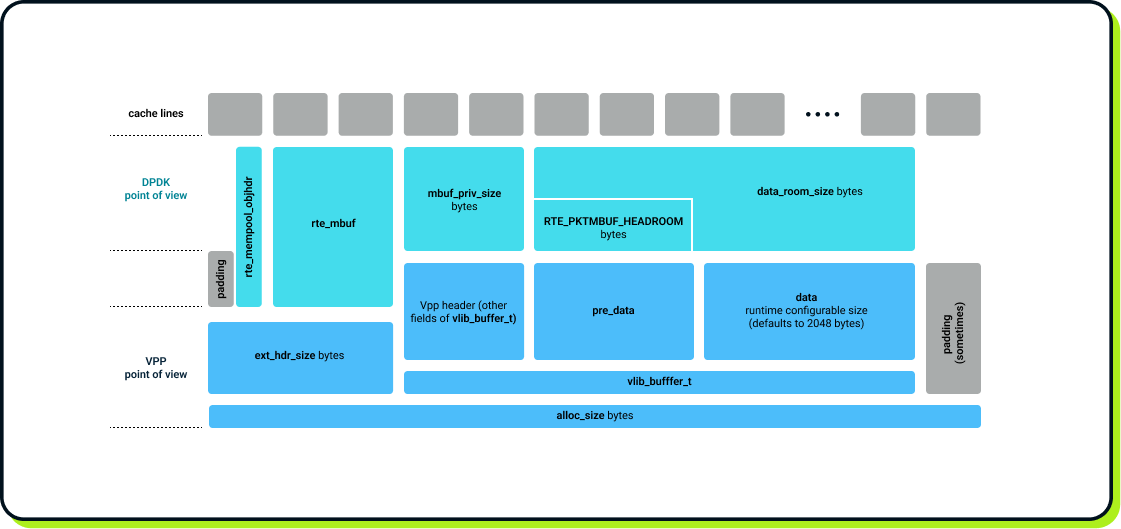
Buffers throughout VPP are referred to by a 4-byte u32 index rather than a pointer. This halves the memory usage of some crucial data structures, e.g., a single vector of 256 packets represented by pointers would usually occupy 32 cache lines, but using 4-byte indexes, it spans only 16 cache lines. This halving doesn’t result in a significant memory usage reduction but reduces cache pressure. The cost of this optimization is that memory used for buffers is limited to 256GiB (which is more than enough, given the 40MB per NUMA node default). Why is it only 256GiB? – you might ask – after all, 2.5kB × 232 is a few TB. The answer is yet another compromise. To avoid the usage of multiplications and divisions on pointer-to-index (and vice versa) conversions, the index is not really one-per-buffer but one-per-cache-line. A lot of possible indices end up being unused in this scheme, but in return, we can use simple bitshifts for conversions.
VPP aligns the packet buffer to a cache line, as does most packet processing software, but it also pads the buffer allocation to an odd number of cache lines! So if the size of the headers + data ends up being 28 cache lines, VPP will insert one empty cache line so that the offset between consecutive buffers is 29 cache lines. If you haven't guessed yet, the reason is interaction with CPU caches. What would happen if we had even (in cache lines) offsets between buffers? Some parts of the buffer could end up on only even (or only odd) cache lines. Due to how CPU caches are implemented, such data could be stored in only half of their slots, increasing cache pressure (sidenote: an exception would be a fully associative cache, but such cases don’t occur in the wild). Thankfully, using odd offsets makes the addresses pleasantly unordered and makes CPU caches happy.
The other optimization seen across the code is a pattern of prefetching data for 4 packets forwards – after multiple roundtrips through the mempool, the vector of packets doesn't necessarily point to contiguous packets. That means that the CPU won't be able to automatically prefetch the memory for the next packet. To prevent the CPU from waiting on fetching memory, the addresses for the next 4 packets are usually prefetched beforehand.
DPDK?
We've explained how VPP pre-allocates its buffers in one chunk. You might also know that DPDK also uses mempools for its RX queues. But does this mean the packet data must be copied on DPDK-to-VPP ingress or VPP-to-DPDK egress? Fortunately, the answer is no! Does this mean VPP relies on DPDK-owned memory to avoid copying? Again, no! The DPDK plugin is written in such a way that DPDK's mempools point at the same buffers as VPP's buffer pools. This might sound mind-blowing at first, but there are several pieces of the puzzle that make this possible:
- DPDK's rte_mempools allow custom callbacks for dequeue (getting from the mempool) and enqueue (putting to the mempool).
- While DPDK mempools usually allocate their own memory, this behavior can also be disabled.
- DPDK allows mbuf_priv_size "private area" bytes after the rte_mbuf header (before the payload).
- VPP allows ext_hdr_size bytes before VPP's vlib_buffer_t.
Together, the custom callbacks and the non-allocating mode make it possible to run the rte_mempool on “borrowed" memory. In this case, the memory is owned by VPP. With these callbacks, RX queues can pull buffers from VPP’s buffer pools, and TX queues can put buffers back into VPP’s buffer pools.
Now, notice how DPDK allows extra data after its header, and VPP allows it before. This allows every packet to have two headers – VPP’s and DPDK’s – each hiding in the other's “private area”. A happy coincidence? Not really. In fact, the DPDK plugin is the only user of VLIB_BUFFER_SET_EXT_HDR_SIZE. The truth is that VPP was designed for zero-copy interoperability with DPDK from the start. While some specifics have changed a few times during VPP’s development, zero-copy operation with the double header has always been there.
To summarize and visualize this “double-header” design, here’s a VPP buffer in full glory. This diagram visualizes both DPDK’s and VPP’s interpretation of the buffer’s memory. We’ve tried to draw the memory layout in scale (well, except the data field) to convey the idea of sizes of various headers (assuming 64-byte cache lines). Also, note the padding at the beginning and at the end – the first’s purpose is to pad the ext_hdr_size to full cache lines, and the second one pads the whole allocation to an odd number of cache lines, as we’ve explained before.
What are the DPDK plugin’s responsibilities then? Aside from registering the aforementioned enqueue and dequeue callbacks in the rte_mempool) it needs to:
- register every page of all the buffer pools as DMA eligible for all devices on initialization,
- fill out DPDK headers (rte_mempool_objhdr and rte_mbuf) during buffer pool initialization,
- translate packet lengths and offsets (and metadata for segmented packets) from rte_mbuf to vlib_buffer_t headers on ingress,
- translate the rte_mbuf addresses to buffer addresses (or, to be precise, indices), and
- perform the opposite translations on egress.
We have therefore shown that it is possible for VPP to tightly integrate with DPDK, but without VPP’s core data structures explicitly depending on DPDK! But that wasn’t always the case – initial versions of VPP had more dependence on DPDK, as performance was always the first priority, and building VPP around the rte_mbufs was an obvious choice. The cleaner solution had a chance to appear only because it didn’t compromise performance.
Thread-locality
So... returning to the question, "When does a packet cross a thread boundary?". The answer is "usually never". A packet starts its life in the input node on some worker thread (or actually even before – when the device fills the packet buffer in the RX queue through the DMA). The packet and its buffers thus become a part of a vector of multiple packets – this vector being the output of the input node.
When a worker thread finishes getting input from all its input nodes (usually, all its assigned RX queues), it basically processes all these packets to completion. When a node processes (or produces) a vector of packets, each packet from the vector is assigned as an input to the next node. The worker thread then finds a node with a non-empty input vector and now runs that node. This step repeats until there are no nodes to run, effectively traversing the node graph. Therefore, the packets finally reach the output node(s).
Keep in mind that all of this happens in a single thread. While every worker thread indeed operates on the same set of nodes, conceptually, each of the worker threads contains its own copy of the node graph.
In the interface output node, the vector of packets is enqueued to a TX queue or queues (which is also represented as yet another node). If a worker thread has multiple TX queues to choose from, the destination queue will be chosen for each packet based on its hash (usually, the 5-tuple). The exact behavior of the output node depends on the output plugin, but since the TX queue node is “yet another node”, its output function will also run on the same thread.
It is possible that a TX queue will be shared across multiple worker threads (if the device doesn’t support as many TX queues as there are worker threads) or even to be shared across all the worker threads. In such a case, the output function will usually employ a spinlock, as is the case with the DPDK output plugin. However, keep in mind that locking is usually needed only for sending buffer descriptors to the network device – the lock is not held while actually putting bits on the wire, and copying buffers is done outside the lock too.
So is there any case where a packet actually crosses a thread boundary? The answer is yes, but it is done only when it’s necessary. One example of such is the NAT node. This node needs to store some per-session information. To avoid locks or other thread-safe data structures, this data is stored in a thread-local manner. Hence, all the packets belonging to the same session need to be processed by the same worker thread. Here VPP offers a solution called handoff queue (or frame queue). Sticking with the NAT example – this feature actually consists of two nodes in the graph. The first one classifies a packet for a specific worker thread (by hashing some part of packet metadata, like destination IP or port) and enqueues on the second one’s handoff queue for an appropriate thread. Thanks to this step, the second node can rely on the packets in its input vector being already classified.
Interacting with VPP
There are two main ways to communicate with a running instance of VPP: Through the socket and through the shared memory.
Commands architecture (vppctl)
Communicating through the socket is the most common mode of communication – this is e.g. how vppctl works. You might also use the socket via API, there are bindings for a few languages available. Let's assume we're using vppctl here for simplicity.
For each command we run, vppctl:
- parses the command (VPP has a nice unparse function that helps in writing commands),
- serializes the command into binary format (using generated structures),
- pushes serialized data through the socket.
Then, the main thread of vpp itself receives data from the socket and calls an appropriate handler function. The handler then serializes the response. The serialized response is then received by vppctl and is usually pretty-printed in human-readable format (there's one exception for this rule – some debug commands for which the performance isn't crucial can directly prepare the formatted output in the command handler).
This is designed so that vpp itself performs the minimal necessary work, pushing parsing and formatting to vppctl side, but still, if running a lot of commands (especially if having huge numbers of interfaces), the main thread might experience increased CPU usage (or with the single-threaded scenario, datapath will simply have fewer CPU cycles to do its work).
Stats architecture
VPP keeps performance statistics as a set of various counters, like RX counters, packet drops, or counters and gauges related to memory and CPU utilization.
How the stats can be accessed from outside VPP differs significantly from the usual command processing, as stats use shared memory instead of sockets. All the performance counters themselves (along with their "directory") are kept inside a block of shared memory, which is available read-only for other processes. These shared-memory stats can be accessed e.g. via the vpp_get_stats command.
The counters themselves are simple atomic variables, so they can be concurrently read or written without an issue. However, the overall structure ("directory") of the counters may change while reading. How is consistency on the reader-side achieved then? Remember, the shared memory is read-only, and any lock would require write access. The answer is a very simple epoch-based system combined with "optimistic concurrency". At the very beginning and at the very end, a command such as vpp_get_stats reads the current epoch number. If these epoch numbers differ, this means that what was read is potentially garbage and needs to be discarded, and the whole process needs to be repeated.
This architecture has the major benefit of having zero overhead on the VPP side. The only logic for accessing stats runs in the reader's (e.g. vpp_get_stats) process. The only theoretical slowdown on VPP caused by reading stats would be cache effects on the CPU, although this is such a small effect, and we cannotobserve it. Interestingly, despite nice performance characteristics, this stats architecture is deprecated. You can read more about the stats architecture here ![]() .
.
Configuring VPP
We've dived into some technical aspects of VPP, but you may ask – are there some practical conclusions?
The main thing to remember is that the default configuration of VPP is a single-core one. This might be obvious in hindsight, but it certainly wouldn’t hurt to restate that fact. The default configuration is not only single-core; the single thread acts as both the worker thread and the main thread. This means that processing commands will block the datapath!
So basically: don't use the single-threaded mode (unless you have only a single core available). Usually, you want to have a number of worker threads equal to the number of free CPU cores minus two (leaving one core for the main VPP thread and the other for the “system”). And even if your workload doesn't benefit from multiple workers, it's beneficial to run in multi-threaded mode, even if only to separate the worker thread from the main thread. Also, we've observed that separating the worker thread might give a few percent performance boosts by itself.
It might also be worth configuring the scheduler to avoid running any processes on the cores that the worker threads are pinned to. One way to do it is leveraging systemd slices ![]() – a new slice needs to be created for VPP, and the user and system slices need to have their AllowedCPUs property set accordingly.
– a new slice needs to be created for VPP, and the user and system slices need to have their AllowedCPUs property set accordingly.
Regarding running VPP and collecting statistics. It might be tempting to use vppctl show int – because, in addition to listing interfaces, it also displays some statistics. However, if our only goal is to collect stats, vpp_get_stats should be used instead. As we've explained before, running this command doesn't require any processing on the VPP side, thus, even hammering vpp_get_stats in a loop shouldn't cause any slowdown.
Summary
We hope that you’ve enjoyed this under-the-hood tour of VPP and that the architectural aspects of high-performance networking software – how it manages CPU and memory – are now less mysterious.
We’ve also seen that VPP is indeed designed with performance in mind. In fact, VPP’s core idea is to lessen the instruction cache pressure by processing packets in vectors. But VPP doesn’t stop there – all the design decisions, big and small, are made with mechanical sympathy in mind. From high-level choices such as NUMA-awareness, threading principles, and stats architecture to smaller optimizations, it’s hard to even find a place on the datapath that doesn’t embrace the limitations and capabilities of modern CPUs. We’ve also shown how VPP’s authors implemented an elegant solution for DPDK integration, but only after it was possible to do so without compromising performance.
There are still a lot of interesting parts of VPP design that are worth exploring. In the future we’d like to dig into some topics even further. Also, it’s worth checking how all the design choices, which should give VPP best-in-class performance, compare with other solutions on real-world benchmarks.
Yet another interesting aspect to explore is VPP’s HTTP stack, which crosses the traditional boundaries of networking software by extending to the L7 rather than the usual L3 or L4.


