


Have you ever wondered about alternatives to iptables for dropping packets in Linux OS? Well, there are a few methods to do this. In this blog post, we want to share them with you. These methods are not restricted to just firewall rules and can be divided into the following categories:
- ebtables - the same as above, but mostly focused on layer 2 (the comparison between ISO/OSI and TCP/IP models is presented in our infographic)
- nftables - successor of iptables+ebtables
- ip rule - a tool designed to build advanced routing policies
- IP routing - transferring packets according to the routing table
- BGP Flow Spec (how to deploy iptables’ rules using BGP protocol)
- QOS - using the tc filter command design for QOS filtering
- DPDK - using OVS working outside of kernel with the help of DPDK
- HW filter - dropping packets at the hardware level before they reach the CPU
- eBPF with a little help from XDP
- filtration on OSI layer 7 using a user space application
Before we begin, just a quick reminder about packet flow in the Linux kernel:

If you are experiencing network issues in your Linux environment, remember that our guide on Linux network troubleshooting can help you diagnose and resolve the problems with your network configuration.
Dropping packets with iptables in Linux
iptables is the most popular method when it comes to processing packets in Linux. Filtering rules can be divided into 2 types, which differ considerably: stateful and stateless. Using stateful filtration allows the packet to be analyzed in the context of the session status, e.g., whether the connection has already been established or not (the packet initiates a new connection).
However, easy state-tracking has its price-performance. This feature is considerably slower than the stateless solution, but it allows more actions to be performed. The rule below is an example of how to drop packets using iptables based on their state (here: a new connection):
# iptables -A INPUT -m state --state NEW -j DROP
By default, every packet in iptables is processed as stateful. To make an exception, it is necessary to perform a dedicated action in a special table “raw”:
# iptables -t raw -I PREROUTING -j NOTRACK
It is always good to remember that the iptables method allows you to perform classifications on multiple layers of the OSI model, starting from layer 3 (source and target IP address) and finishing on layer 7 (project l7-filters, that is, sadly, not developed anymore).
When handling stateful packets, it is also vital to remember that the conntrack module for iptables uses only a 5-tuple, which consists of:
- source and target IP address
- source and target port (for TCP/UDP/SCTP and ICMP, where other fields take over the role of the ports)
- protocol
This module does not analyze an input/output interface. So, if a packet that has already been processed goes (in another VRF) to the IP stack once again, a new state will not be created. There is, however, a solution for this issue, which involves using zones link-icon ![]() in the conntrack module that allow packets interface $X to be assigned to the zone $Y.
in the conntrack module that allow packets interface $X to be assigned to the zone $Y.
# iptables -t raw -A PREROUTING -i $X -j CT --zone $Y
# iptables -t raw -A OUTPUT -o $X -j CT --zone $Y
To sum up: due to its many features, the iptables packet drop method is slow. It is possible to speed it up by switching off the tracking of session states, but the performance increase (in terms of PPS) will be small. In terms of new connections/seconds, the gain will be bigger. More on this subject can be found here link-icon ![]() .
.
In the long run, it is planned to migrate the iptables method to Berkeley Packet Filter (BPF), then a major speed/performance increase can be expected.
Using ebtables to drop packets at layer 2
In case we want to go lower than layer 3, we have to switch the tool to ebtables as an alternative to iptables, allowing us to work from layer 2 up to layer 4. For example, if we want to drop packets where the MAC address for IP 172.16.1.4 is different than 00:11:22:33:44:55, we can use the rule below:
# ebtables -A FORWARD -p IPv4 --ip-src 172.16.1.4 -s ! 00:11:22:33:44:55 -j DROP
It is important to remember that the packets passing through a Linux bridge are analyzed by FW rules. This is managed by the following sysctl parameters:
- net.bridge.bridge-nf-call-arptables
- net.bridge.bridge-nf-call-ip6tables
- net.bridge.bridge-nf-call-iptables
More info can be found in this article link-icon ![]() . If we want to gain performance, it is advised to disable those calls.
. If we want to gain performance, it is advised to disable those calls.
Using nftables to drop packets in Linux
The aim of nftables (introduced by 3.13 kernel) is to replace certain parts of netfilter (ip(6)tables/arptables/ebtables), while keeping and reusing most of it. The expected advantages of nftables are:
- less code duplication
- better performance
- one tool to work on all layers
The performance increase test link-icon ![]() was done by RedHat. The following diagram shows the performance drop in correlation with the number of blocked IP addresses:
was done by RedHat. The following diagram shows the performance drop in correlation with the number of blocked IP addresses:
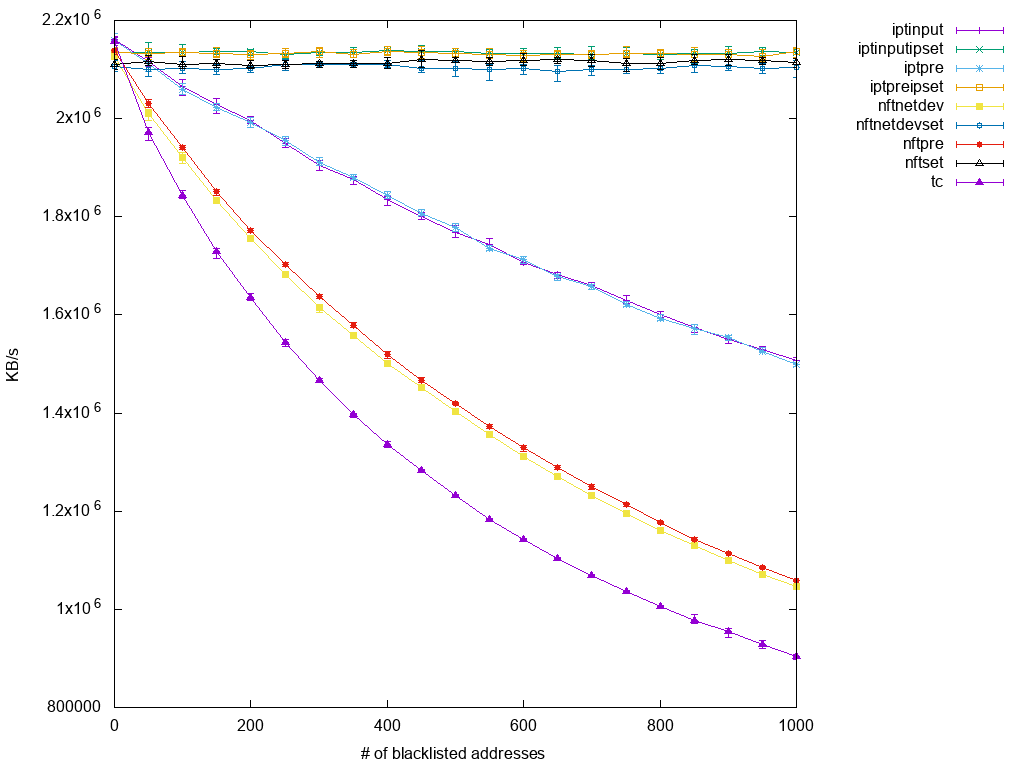
nftables are configured via the nft utility placed in the user space. To drop a TCP packet, it is necessary to run the following commands (the first two are required, as the nftables do not come with default tables/chains):
# nft add table ip filter
# nft add chain ip filter in-chain { type filter hook input priority 0\; }
# nft add rule ip filter in-chain tcp dport 1234 drop
Note: Whenever both nftables and iptables are used on the same system, the following rules apply:
| nft | Empty | Accept | Accept | Block | Blank |
|---|---|---|---|---|---|
| iptables | Empty | Empty | Block | Accept | Accept |
| Results | Pass | Pass | Unreachable | Unreachable | Pass |
Sometimes nft can become slow, especially when dealing with larger amounts of rules, complicated chains, or when running on low-performance hardware such as ARM devices. For such scenarios, one can accelerate performance by caching actions assigned for specific flows (ACCEPT, DROP, NAT, etc.) and bypass further checking of ntf rules if a packet can be assigned to an already existing flow. The following diagram shows this idea in detail:
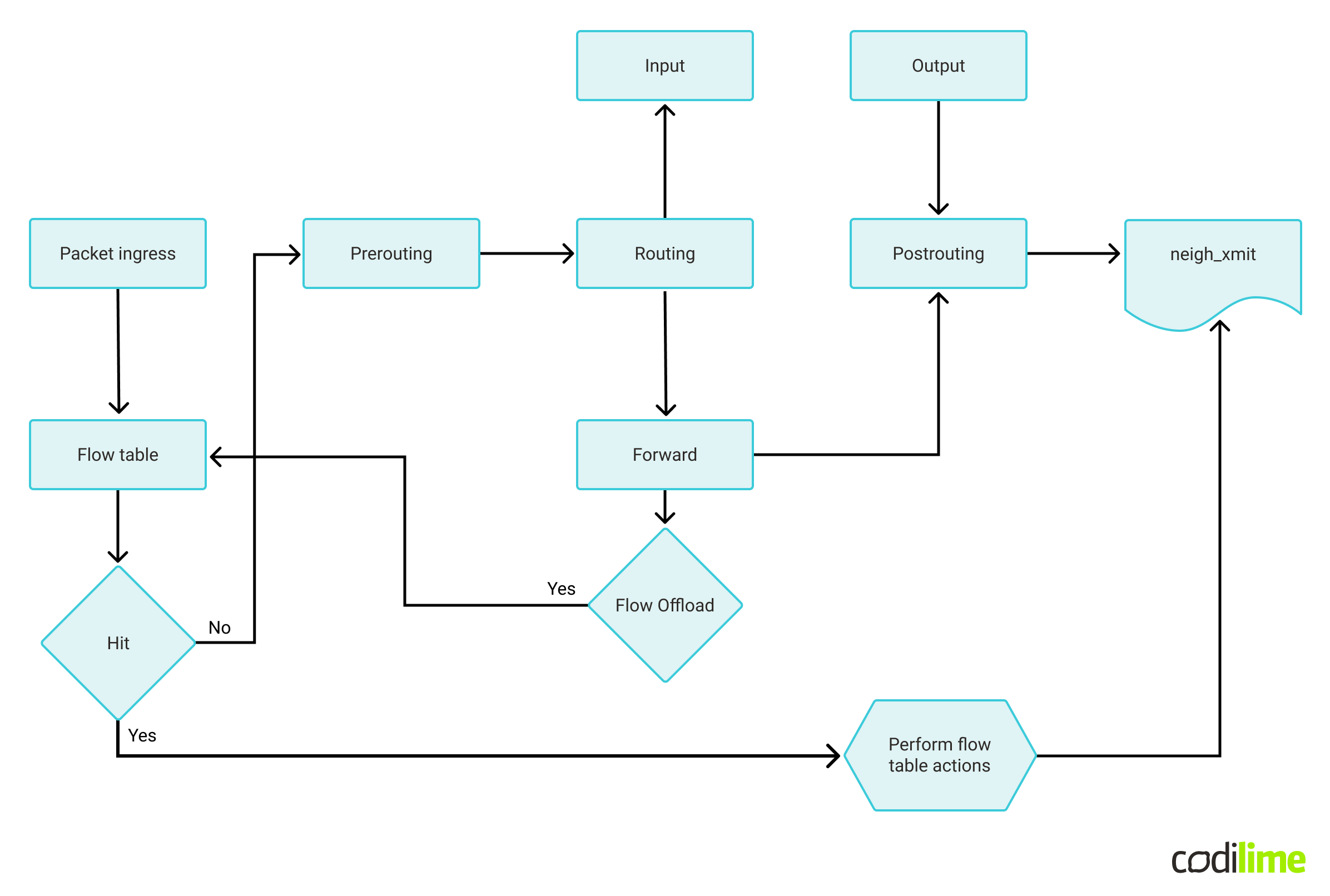
Performance gain strongly depends on existing complexity, but in the case of weak processors (such as ARM64) and complicated nft rules (such as in VyOS), one can expect a 2-3x throughput increase.
Enabling such features is relatively easy - one has only to add an extra rule:
table inet x {
flowtable f {
hook ingress priority 0; devices = { eth0, eth1 };
}
chain y {
type filter hook forward priority 0; policy accept;
ip protocol tcp flow offload @f
counter packets 0 bytes 0
}
}
Each packet hitting ingress will be checked against flow table “f”. Each TCP packet traversing chain “y” will be offloaded. For more information one can check the kernel nft documentation at the following link ![]() .
.
Using ss (netstat replacement) to drop packets in Linux
Sometimes there is no need to block all packets between two hosts. In less frequent cases, it is enough to kill a single TCP connection that originates from a host. Using iptables / nftables here to reset such connections is not the most efficient here, as idle TCP sessions are just sending keepalives (and not very often), and FW can only send TCP RST in response to such packets. So one would have to wait a bit till a connection is closed.
This was a case in our AutoCon 4 workshop where we had to emulate BGP flapping inside one of the containers (and to make things more complicated, that container had no iptables included). So, in order to drop/kill a connection originating from the host, we can use the ss command. In the AC4 workshop, we ran this command periodically:
# ss -K dst 100.65.0.1 and dport 179
As a result, any connection towards 100.65.0.1 and port 179 (that was one of the BGP RR in our containerlab topology) was killed, and the BGP server on the host (where the above command was issued) reported BGP connection failure.
Using ip rule to drop packets in Linux
The ip rule tool is a lesser-known iptables alternative method. In general, it can be used to create advanced routing policies. As soon as the packet passes through the firewall rules, it is up to the routing logic to decide if the packet should be forwarded (and where), dropped, or do something else entirely. There are multiple possible actions; the stateless NAT is one of them (not a commonly known fact); however, the “blackhole” is the one used to drop packets:
# ip rule add blackhole iif eth0 from 10.0.0.0/25 dport 400-500
ip rule is a fast, stateless filter used frequently to reject DDOS traffic. Unfortunately, it has a drawback: it allows us to work only on IP SRC/DST (layer 3), TCP/UDP ports (layer 4), and is based on the input interface.
Keep in mind that the interface loopback (lo) plays an important role in the ip rulesets. Whenever it is used as an input interface parameter (iif lo), it decides whether the rule is applied to the transit traffic or to the outgoing traffic coming from the host on which this rule is being configured. For example, if we want to drop transit packets destined to the address 8.8.8.8, the following rule can be used:
# ip rule add prohibit iif not lo to 8.8.8.8/32
Using IP routing to drop packets in Linux
Another alternative method of filtration is to use routing policies. While it is true that this method works only for layer 3, and in the case of target addresses, this filtration method can be used simultaneously on many machines, thanks to routing protocols like BGP. The simplest example of dropping the traffic directed to the 8.8.8.8 address is the below rule:
# ip route add blackhole 8.8.8.8
When talking about routing policies, it is worth mentioning the following kernel configuration parameter (which is often forgotten):
# sysctl net.ipv4.conf.all.rp_filter
If by default it is set to “1”, it checks the reverse path of every packet before moving it further to the routing stack.
So, if a packet from A.B.C.D address appears in the eth0 interface while the routing table says that a path to A.B.C.D address leads via eth1 interface (we have a case of asymmetric routing here), such a packet will be dropped, if the rp_filter parameter* (global or for that interface) is not equal to 0.
Dropping packets with BGP Flow Spec
When describing the BGP routing protocol, it is compulsory to say a few words about BGP Flow Spec. This extension is described in RFC 5575 and is used for packet filtering. Linux (with a little help from FRR daemon) supports the above feature by translating the received NLRI to the rules saved in ipset/iptables. Currently, the following filtering features are supported:
- Network source/destination (can be one or the other, or both)
- Layer 4 information for UDP/TCP: source port, destination port, or any port
- Layer 4 information for ICMP type and ICMP code
- Layer 4 information for TCP Flags
- Layer 3 information: DSCP value, Protocol type, packet length, fragmentation
- Misc layer 4 TCP flags
Thanks to this approach, it is possible to dynamically configure FW rules on many servers at the same time. More info can be found in the FRR documentation here ![]() .
.
Dropping packets with QOS
It is not commonly known that it is also possible to perform packet filtration at the level of QOS filters. The tc filter command, responsible for classifying the traffic, is used in this case. It allows us to filter traffic on L3 and L4 statelessly. For example, to drop the GRE traffic (protocol 47) coming to the eth0 interface, the following commands can be used:
# tc qdisc add dev eth0 ingress
# tc filter add dev eth0 parent ffff: protocol ip prio 1 u32 match ip protocol 47 0x47 action drop
Simulating packet loss with Netem
When talking about packet-dropping and QOS, one must mention a queuing discipline, Netem, that is a separate category of QOS. In Netem, it is possible to simulate problems with network topology by defining actions like:
- loss
- jitter
- reorder
For example, if we want to emulate 3% losses on the output interface eth0, we can use the following command:
# tc qdisc add dev eth0 root netem loss 3%
By default, netem works for outgoing traffic. However, You can apply it also for incoming traffic as well with a little help of IFB (Intermediate Functional Block pseudo-device). Please check this web page for detailed example: How can I use netem on incoming traffic ![]()
Dropping packets with eBPF and XDP
In short, eBPF is a specific virtual machine that runs user-created programs attached to specific hooks in the kernel. Such programs are created/compiled at the userspace and injected into the kernel. They can classify and perform actions upon network packets, including dropping packets directly in the kernel.
Currently, there are four popular ways in which the user can attach eBPF bytecode into the running system in order to parse network traffic:
- Using QOS action attach to: tc filter add dev eth0 ingress bpf object-file compiled_ebpf.o section simple direct-action
- Using firewall module: iptables w/ -m bpf --bytecode (which is not of any interest to us, as the BPF would be used only for packet classification)
- Using eXpress Data Path (xdp) - with a little help of the ip route command
- Using the CLI tool named bpfilter (in early stage of development)
The second approach based on tc filter, is explained well in Jans Erik’s blog ![]() . We will concentrate on the XDP approach, as it has the best performance. To drop a UDP packet destined for 1234 port, we first need to compile the following BPF code:
. We will concentrate on the XDP approach, as it has the best performance. To drop a UDP packet destined for 1234 port, we first need to compile the following BPF code:
#include <linux/bpf.h>
#include <linux/in.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/udp.h>
#define SEC(NAME) __attribute__((section(NAME), used))
#define htons(x) ((__be16)___constant_swab16((x)))
SEC("udp drop")
int udp_drop(struct xdp_md *ctx) {
int eth_off = 0;
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
eth_off = sizeof(*eth);
struct iphdr *ip = data + eth_off;
struct udphdr *udph = data + eth_off + sizeof(struct iphdr);
eth_off += sizeof(struct iphdr);
if (data + eth_off > data_end) {
return XDP_PASS;
}
if (ip->protocol == IPPROTO_UDP && udph->dest == htons(1234)) {
return XDP_DROP;
}
return XDP_PASS;
}
char _license[] SEC("license") = "GPL";
With the following command:
$ clang -I/usr/include/x86_64-linux-gnu -O2 -target bpf -c udp_drop.c -o udp_drop.o
Then we can attach the bytecode to kernel using this CLI:
# ip link set dev eth0 xdp obj udp_drop.o sec .text
At the end, we can stop the XDP program just by unloading it:
# ip link set dev eth0 xdp off
Note: Code in this section was based on the Lorenzo Fontana udp-bpf example located here ![]() .
.
Using DPDK and OVS to drop packets in Userspace
DPDK is an alternative to eBPF - the idea is to process the packet by bypassing the kernel network stack entirely or partially. In DPDK packets are processed fully in userspace. While this might sound slower than processing in the kernel, it isn’t. Processing a packet in the kernel means passing all the chains and hooks described earlier. We don't always need that.
If we just need to do the routing or routing and filtering, we skip QOS, RPF, l2 filter, stateful FW, etc. For example, we can use OVS in DPDK mode and configure only the things that we need - nothing else. In OVS (as soon as we set everything up) we can drop a packet with the following rule:
# ovs-ofctl add-flow br0 "table=0, in_port=eth0,tcp,nw_src=10.100.0.1,tp_dst=80, actions=drop"
From now on, for any packet incoming on port eth0 matching source IP 10.100.0.1, the TCP protocol and HTTP port will be dropped. Setting up OVS might be tricky but the performance increase is huge making this process worthwhile. To gain even more speed some NICs (especially smartNICs) can offload many OVS tasks and as a result drop packets before they reach the CPU.
An alternative to OVS is VPP - this is even faster in some scenarios so it might be worth taking a look – link here ![]() .
.
Using hardware filters to drop packets
Dropping packets consumes resources. First, the packet must be received and memory allocated, then the packet must be matched to one or more rules, and after all that, a decision can be made to drop the frame. If we have spare CPU cycles, then that is fine. However, when dealing with 100 Gbit/s network cards, even a powerful CPU can be overwhelmed by malicious traffic such as DDoS attacks (if such traffic isn’t adequately filtered before reaching our endpoint).
And even if this is not the case, we can always use those CPU cores for more productive tasks such as service hosting. In such cases we can use hardware for the task.
Intel hardware filtering with flow director
For Intel NIC/SmartNICs, we can use a feature called "Intel Flow Director". The list of compatible Intel NIC/SmartNIC cards is shown below:
- 500 series - Niantic
- 700 series - Fortville
- 800 series - Columbiaville
To check if a card is supported, issue the following commands:
# ethtool -K eth0 ntuple on
# ethtool -k eth0 | grep ntuple
ntuple-filters: on
If those commands were successful then you can start creating filters with action drop:
# ethtool -U eth0 flow-type udp4 src-ip 10.0.0.0 m 0.0.0.255 dst-port 123 action -1 loc 42
Here we are creating a filter that will:
- apply the rule on the eth0 interface
- match only UDPv4 traffic
- match traffic from 10.0.0.0/24 (note that an inverted mask is used here)
- match traffic towards the NTP (123) port
- apply action DROP (-1 means drop)
- place the rule as the 42nd entry in the NIC card (entries are processed in numerical order just like in FW ACLs)
We can confirm whether the above action was successful by using:
# ethtool -u eth0
16 RX rings available
Total 1 rules
Filter: 42
Rule Type: UDP over IPv4
Src IP addr: 10.0.0.0 mask: 0.0.0.255
Dest IP addr: 0.0.0.0 mask: 255.255.255.255
TOS: 0x0 mask: 0xff
Src port: 0 mask: 0xffff
Dest port: 123 mask: 0x0
Action: Drop
If it’s no longer needed, the rule can be removed with:
# ethtool -U eth0 delete 42
Nvidia hardware filtering with TC Flower
For Nvidia cards, such as ConnectX-5/6/7 (Intel 800 series cards with the latest FW should be supported as well), we can use a different method called TC Flower, which can be offloaded to NIC hardware. The procedure here is similar to the QOS chapter:
# tc qdisc add dev eth0 ingress
# tc filter add dev eth0 ingress protocol ip prio 42 flower ip_proto udp src_ip 10.0.0.0/24 dst_port 123 action drop
If everything went fine, the following command should show us the status along with some statistics:
# tc -s filter show dev eth0 ingress
filter protocol ip pref 1 u32 chain 0
filter protocol ip pref 1 u32 chain 0 fh 800: ht divisor 1
filter protocol ip pref 1 u32 chain 0 fh 800::800 order 2048 key ht 800 bkt 0 terminal flowid ??? not_in_hw
match 00070000/00470000 at 8
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 281 sec used 281 sec
Action statistics:
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
filter protocol ip pref 42 flower chain 0
filter protocol ip pref 42 flower chain 0 handle 0x1
eth_type ipv4
ip_proto udp
src_ip 10.0.0.0/24
dst_port 123
not_in_hw
action order 1: gact action drop
random type none pass val 0
index 2 ref 1 bind 1 installed 153 sec used 153 sec
Action statistics:
Sent 0 bytes 0 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
Note: In our case, the rule was not offloaded due to the lack of proper hardware. On supported NICs, one should expect to see the following in the above output:
[...]
skip_sw
in_hw
[...]
Since we are dealing with hardware here the number of rules is limited. However, this approach ensures no performance degradation and zero CPU usage related to network traffic filtering.
Layer 7 (L7) Filtering: Dropping packets in User Space
Kernel modules support packets (with a few exceptions like BFP, dedicated kernel modules, NFQUEUE action in iptables) in layers 2-4. In the case of layer 7, it is necessary to use dedicated user space applications. The most popular are SNORT and SQUID. SNORT IPS can work to analyze traffic, searching for known exploits in two modes: TAP and INLINE.
TAP mode:

In the TAP mode (Snort is only listening to the traffic), a packet can be dropped only by sending a “TCP RST” packet (for TCP session) or “ICMP Admin Prohibited” for the UDP one. However, this approach will not prevent the forbidden packet from being sent, but it should prevent further transmission.
INLINE Mode:

For INLINE mode (Snort is transmitting the traffic in question) we have more flexibility, and the following actions are possible:
- drop - block and log the packet
- reject - block the packet, log it, and then send a TCP reset if the protocol is TCP or an ICMP port unreachable message if the protocol is UDP
- sdrop - block the packet but do not log it
You can find more about filtering rules in SNORT in its technical documentation here ![]() .
.
SQUID (designed to forward/cache HTTP traffic only), on the other hand, allows web pages to be filtered, e.g. based on the host contained in HTTP headers or using SNI in the case of HTTPS protocol. For example, if an ACL containing domain names like *.yahoo.com *.google.com is defined:
acl access_to_search_engines dstdomain .yahoo.com .google.com
acl access_to_search_engines_ssl ssl::server_name .yahoo.com .google.com
and action DENY is assigned to them:
http_access deny access_to_search_engines
ssl_bump terminate access_to_search_engines_ssl
...then every client which is using that HTTP proxy service, while trying to open the google.com or yahoo.com webpage will encounter an error.
Of course, the list of apps to filter the traffic based on layer 7 is much longer
and contains such positions as:
- mod_rewrite in apache configuration files
- query_string in NGINX vhost config
- ACLS in haproxy

Using GPU acceleration to drop packets at scale
Sometimes you might want to filter packets by using a very long ACL (e.g., an ACL built from 10k rules) while dealing with traffic containing a huge number of flows (>100k simultaneous sessions) at the same time. In such cases, OVS or NFT flowtables might not be enough as neither of them is suited for such a scale. In the case of OVS/NFT, you will overflow the hashing table, and when you disable the hashing table/stateful FW, the length of the ACL will kill performance. You might consider offloading this task to a smartNIC or DPU, but such devices are rare or expensive.
At Codilime, we tried to take a bit of a different approach to such problems, and we decided to use a common Nvidia GPU. While this was a purely R&D project (not yet ready for a production environment), you still might find it helpful. More details, along with the presentation, can be found here link-icon ![]() .
.
Summary: How to drop packets
As you can see, there are quite a few alternatives to iptables, allowing you to intentionally drop packets in Linux. All of them are built for specific purposes, and I hope that you can use them in practice. What is missing here is the performance of these methods, but this is a topic for another blog post.
If you’re looking to drop packets on Linux, your choice depends on your goals:
-
For simplicity and flexibility, use iptables or nftables.
-
For speed and efficiency, consider eBPF/XDP or DPDK.
-
For zero-CPU overhead, move to hardware filters or SmartNICs.
-
For application-layer control, rely on Snort, Squid, or other L7 tools.
Each approach comes with trade-offs in complexity, performance, and control, but mastering several of them ensures you can handle packet dropping in Linux at any scale.


