


The rapid rise and fall of some IT technologies, contrasted with the enduring presence of others, is an interesting phenomenon. Some technologies gain popularity because of hype but lack real value. Once the hype dies down, such technologies are likely to fade away. On the other hand, technologies that solve real problems or improve efficiency have a better chance of surviving, but many factors must come into play for this to happen.
For open-source technologies, factors may include easy integration with existing solutions, adoption of current technical paradigms, low barriers to entry, and, of course, a strong ecosystem of developers, users, and vendors.
However, when a technology finally becomes successful and stays with us for a long time, another phenomenon can occur: it can become a solid foundation for other solutions. This is exactly the case with Kubernetes, a very popular container orchestration platform today.
In this article, we'll look at some solutions that leverage Kubernetes' capabilities to address specific use cases beyond container orchestration.
Kubernetes’ success story
As has already been said, Kubernetes ![]() is a popular and powerful platform for running containers. Whether you plan to deploy your applications or other workloads on-prem, in the cloud, or in a hybrid manner, in all cases, they can be containerized and adapted to run in a Kubernetes cluster. Kubernetes can act as a kind of native layer for workloads regardless of where a cluster is running, therefore, no direct adaptation to bare-metal servers, virtual machines, or cloud providers’ environments is needed. This facilitates portability and simplifies deployment in the long run.
is a popular and powerful platform for running containers. Whether you plan to deploy your applications or other workloads on-prem, in the cloud, or in a hybrid manner, in all cases, they can be containerized and adapted to run in a Kubernetes cluster. Kubernetes can act as a kind of native layer for workloads regardless of where a cluster is running, therefore, no direct adaptation to bare-metal servers, virtual machines, or cloud providers’ environments is needed. This facilitates portability and simplifies deployment in the long run.
However, Kubernetes' greatest value lies in its powerful orchestration capabilities. This applies to many aspects, such as supervising workloads' overall states, their performance, resource consumption, health, and lifecycle, as well as scaling them individually when needed according to their current load. These features are provided by Kubernetes out of the box through its comprehensive core components and also thanks to a variety of Kubernetes objects that can be used for different workloads. Their rich parameterization can be realized through the convenient, declarative configuration that has been proven over the years. For example, since many applications today are designed as modular systems (e.g., following the microservices architecture paradigm), Kubernetes is well suited for them as a preferred execution environment and is able to manage their individual components independently.
So far, a large number of deployments based on Kubernetes have been made worldwide. The platform is very mature and stable and has strong community support (held by the CNCF ![]() ). There is a vast ecosystem of cloud-native solutions built around Kubernetes. Also, there are available proven methods for extending the standard Kubernetes feature set, such as custom resource definitions (CRDs), operators, custom schedulers, and plugins, to name a few.
). There is a vast ecosystem of cloud-native solutions built around Kubernetes. Also, there are available proven methods for extending the standard Kubernetes feature set, such as custom resource definitions (CRDs), operators, custom schedulers, and plugins, to name a few.
All these facts encourage the search for ways in which its orchestration capabilities can be reused for use cases that go beyond Kubernetes’ original role (orchestration of containers as such). The next sections of this article discuss several examples where Kubernetes has been successfully used as an orchestration platform, in a non-obvious way, for more specific use cases. They concern:
- CI/CD pipelines
- AI/ML workloads
- VMs (virtual machines)
- IoT devices and edge computing
- Network devices
The vast majority of the solutions discussed in the following sections are based on the same design scheme. Standard Kubernetes mechanisms for managing resources and their lifecycle are used as a foundation, while new domain-specific logic is added. This is typically implemented using CRDs and dedicated controllers. This approach is an alternative to building orchestration and management platforms from scratch, which is, by the way, a well-known and common practice.
The solutions presented here are not intended to prove that the Kubernetes-based approach is better. That would be a somewhat simplified assumption, considering that each individual use case is different and has its own specific conditions on which the selection of the optimal solution depends. Rather, it's to show that Kubernetes is now such a mature and battle-tested platform that there are still many completely new ideas for how to use it.
Kubernetes-driven CI/CD pipelines
Typically, CI/CD pipelines are created using dedicated tools and platforms. Today, there is a truly rich set of solutions that can be used for this purpose, and new ones are appearing all the time. Some of them (e.g., GitLab CI) offer the optional use of Kubernetes as the execution environment for individual tasks defined within CI pipelines. In practice, this is usually done in such a way that the so-called Kubernetes executor calls the Kubernetes cluster API and creates a Pod for each job.
However, it is worth knowing that the use of Kubernetes in CI/CD processes can go much deeper. Let's imagine an approach in which Kubernetes not only serves as an executor for given tasks but also allows defining entire pipelines in a Kubernetes manner and acts as their orchestrator, i.e., it supervises the entire process of execution of their individual stages.
For example, imagine a scenario where you want to build a new version of an application from source, then place the built image in a local registry, run that image in a test namespace, run a bunch of different tests on it, and then deploy the application to the target production namespace.
All of these steps can be modeled as separate tasks within your pipeline. Kubernetes enriched with appropriate logic can provide a unified environment for managing the entire software delivery lifecycle as a kind of “Kubernetes-native” CI/CD system.
This approach facilitates integration between the code repository, build system, and deployment target by utilizing Kubernetes’ native scheduling and resource management capabilities (see Figure 1). The CI/CD pipeline is modeled as a set of declarative objects representing tasks, dependencies, and sequential stages such as build, test, deployment, and so on. This allows pipelines to benefit from the same scalability, resilience, and self-healing properties that have made Kubernetes so popular for containerized workloads.
Each pipeline step can be managed as an independent Kubernetes Job or Pod, enabling parallelism and dynamic scaling based on demand. The rationale for using Kubernetes in this context is in its ability to manage distributed systems with high levels of automation and consistency.
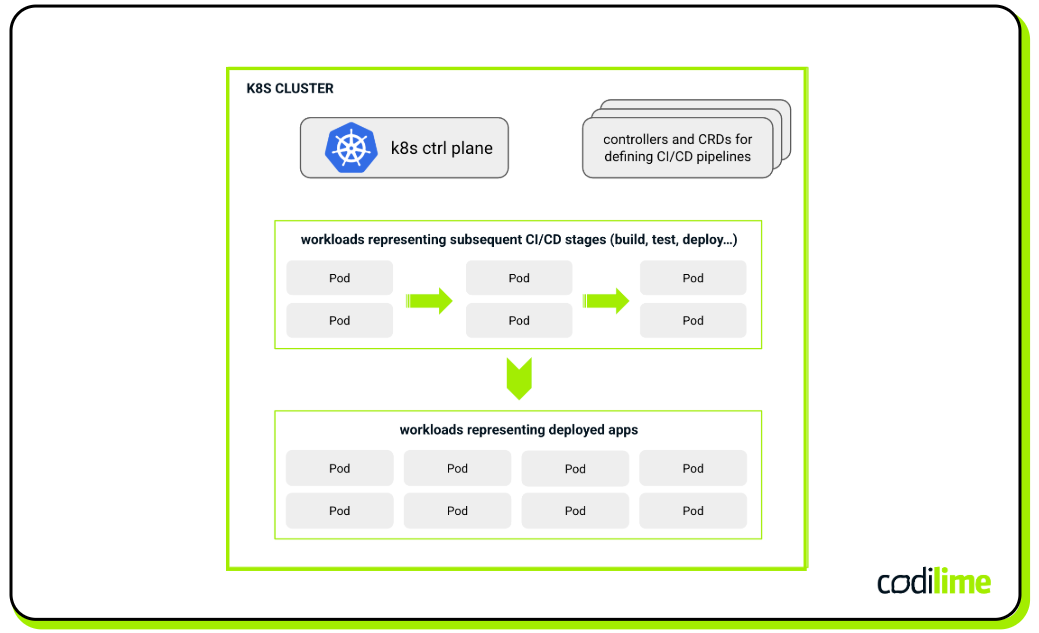
Solutions such as Tekton ![]() and Argo Workflows
and Argo Workflows ![]() exemplify this approach by providing the required logic in the form of CRDs and controllers that operate natively within the Kubernetes ecosystem to properly manage and execute CI/CD pipelines.
exemplify this approach by providing the required logic in the form of CRDs and controllers that operate natively within the Kubernetes ecosystem to properly manage and execute CI/CD pipelines.
Tekton abstracts pipeline components into reusable tasks and pipelines that can be triggered automatically on code commits or by external events. Users can create complex workflows with features such as conditional steps and artifact management.
Argo Workflows, in turn, defines workflows as directed acyclic graphs (DAGs) of containerized tasks, providing a declarative way to manage dependencies and execution order. It supports advanced features like looping, conditional execution, and retry mechanisms, making it suitable for very demanding CI/CD scenarios.
AI/ML workloads managed in Kubernetes
The growth and popularity of AI and machine learning (ML) have created a need for robust platforms to manage the entire lifecycle of ML models, from data preprocessing to model development, hyperparameters tuning, model training, deployment, serving, and monitoring. This continuous process is often referred to as MLOps and can be considered as a set of practices and steps that enable AI/ML solutions to be ready for production deployment.
Kubeflow ![]() is a comprehensive toolkit that you can integrate into Kubernetes clusters to handle the complexities of the process (see Figure 2). Kubeflow contains many components, e.g., Kubeflow Pipelines, Kubeflow Trainer, Katib, and KServe, each dedicated to a different aspect of MLOps. They also bring their CRDs representing the logic related to MLOps. The suite also provides many additional tools useful to data scientists, such as IDEs and dashboards, creating a complete development and runtime environment for ML models.
is a comprehensive toolkit that you can integrate into Kubernetes clusters to handle the complexities of the process (see Figure 2). Kubeflow contains many components, e.g., Kubeflow Pipelines, Kubeflow Trainer, Katib, and KServe, each dedicated to a different aspect of MLOps. They also bring their CRDs representing the logic related to MLOps. The suite also provides many additional tools useful to data scientists, such as IDEs and dashboards, creating a complete development and runtime environment for ML models.
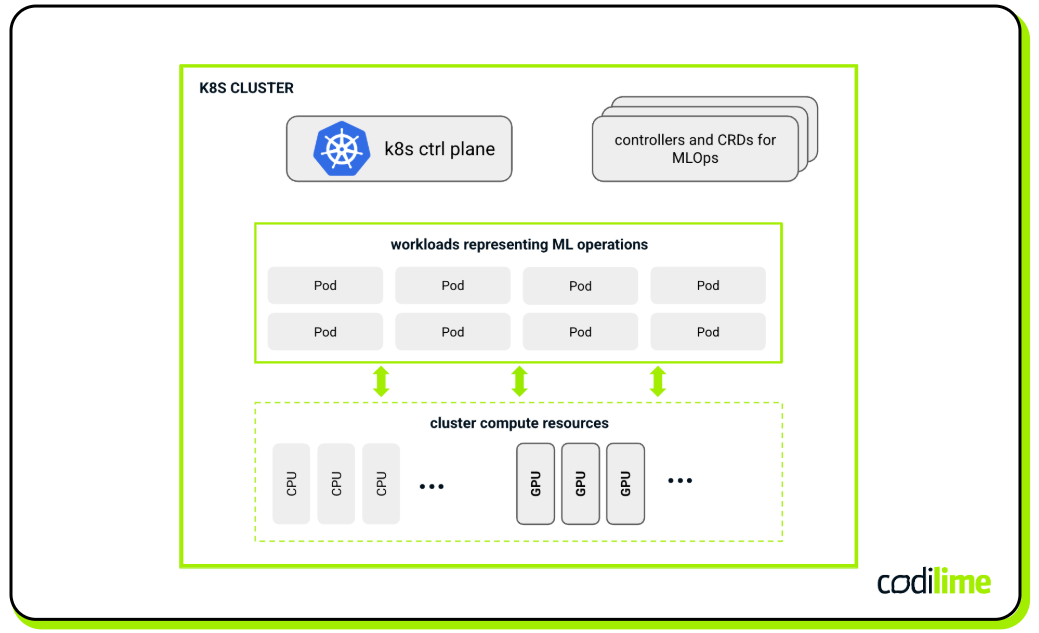
Another very important aspect in this context is Kubernetes support for GPUs. As you may know, GPUs are crucial for achieving the required performance for a large number of AI/ML solutions, both in terms of training and inference.
In Kubernetes, cluster administrators can attach GPUs to nodes, which can then be allocated to Pods running ML jobs. There are several mechanisms and solutions for managing GPU allocation, including k8s GPU device plugins ![]() and custom Operators from vendors, such as the NVIDIA GPU Operator
and custom Operators from vendors, such as the NVIDIA GPU Operator ![]() .
.
Device plugins allow Kubernetes to discover and manage GPUs on nodes, while Operators simplify the deployment and management of required software for GPUs like drivers and libraries. Also, custom Kubernetes schedulers can be applied in these scenarios to optimize GPU resource allocation strategies across the cluster, e.g., to increase the probability that for computationally intensive ML tasks, there will be available nodes with the required hardware capabilities.
Kubernetes orchestrating VMs
Before containers became popular, virtual machines were the most common model applied for sharing computing resources within an existing infrastructure. Frankly speaking, containers are not always the best choice. For some applications, the level of isolation offered by containers is not sufficient or there may also be other important reasons for using VMs rather than containers.
KubeVirt ![]() is a solution that enables the running and managing of virtual machines in the Kubernetes cluster (this concept is shown in Figure 3). It integrates virtualization technology directly into Kubernetes, enabling administrators to define and manage VMs using the same declarative syntax and API conventions that are familiar to container orchestrators. This integration is accomplished by extending Kubernetes with CRDs that represent virtual machines, allowing VMs to be scheduled, scaled, and monitored in the same manner as containerized workloads (see Figure 3). Additionally, operations typically present for VMs, like importing custom VM images and making VM snapshots, are also supported.
is a solution that enables the running and managing of virtual machines in the Kubernetes cluster (this concept is shown in Figure 3). It integrates virtualization technology directly into Kubernetes, enabling administrators to define and manage VMs using the same declarative syntax and API conventions that are familiar to container orchestrators. This integration is accomplished by extending Kubernetes with CRDs that represent virtual machines, allowing VMs to be scheduled, scaled, and monitored in the same manner as containerized workloads (see Figure 3). Additionally, operations typically present for VMs, like importing custom VM images and making VM snapshots, are also supported.
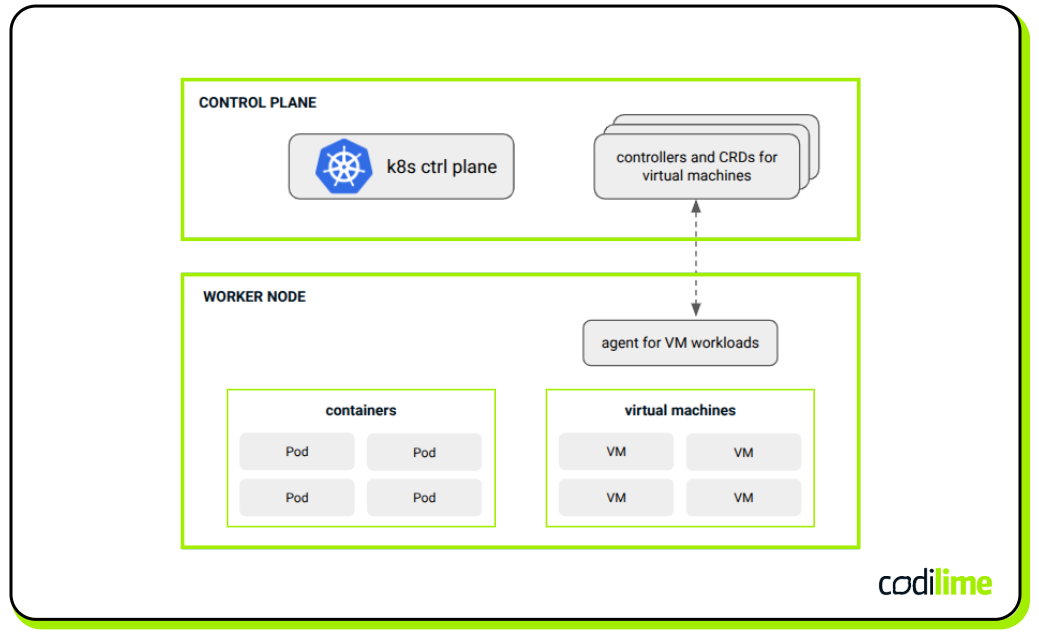
Another scenario is when you want to orchestrate VMs using Kubernetes but not necessarily make them run in the Kubernetes cluster at the same time (see Figure 4). In such a case, Crossplane ![]() is a solution. Crossplane enables building custom Kubernetes APIs to orchestrate non-Kubernetes resources. With CRDs, it is possible to manage any kind of external resource, in particular, cloud resources like VMs. This is done thanks to ‘Providers’ objects that enable connections to external environments to manage the resources that are available there. For instance, through employing AWS, Azure, or GCP Providers, it is possible to create or delete VMs running in those public clouds in a Kubernetes manner.
is a solution. Crossplane enables building custom Kubernetes APIs to orchestrate non-Kubernetes resources. With CRDs, it is possible to manage any kind of external resource, in particular, cloud resources like VMs. This is done thanks to ‘Providers’ objects that enable connections to external environments to manage the resources that are available there. For instance, through employing AWS, Azure, or GCP Providers, it is possible to create or delete VMs running in those public clouds in a Kubernetes manner.
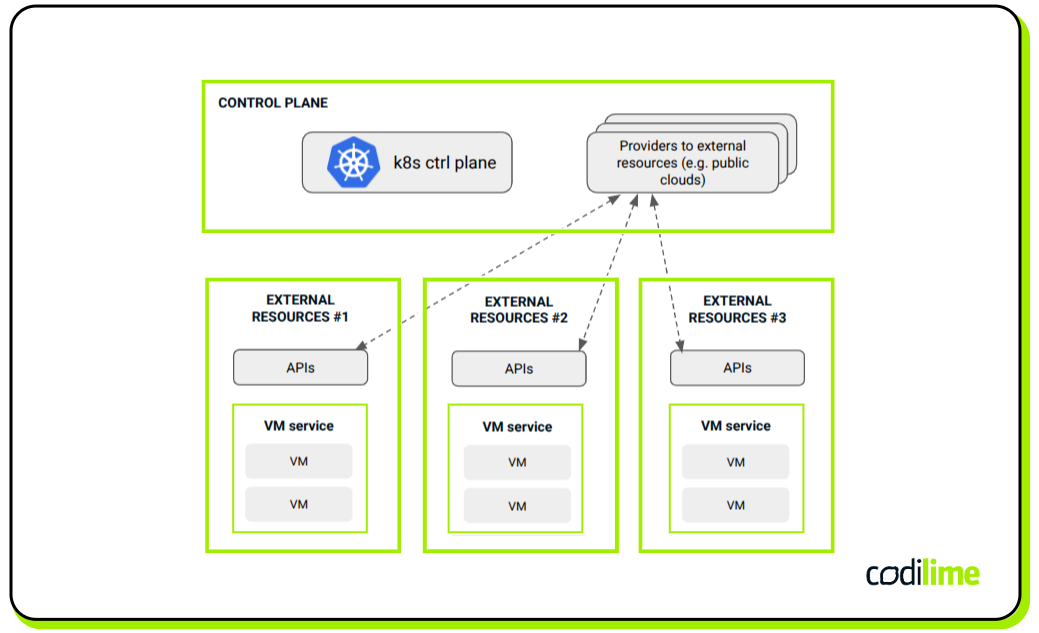
The possible convergence of container and VM management within the Kubernetes control plane can be a valuable option for some organizations. Having a single, coherent orchestration can be beneficial and simplify operations.
Kubernetes for IoT management and edge computing
The growing popularity of edge computing and the Internet of Things (IoT) has created a need for platforms that can manage distributed workloads across a wide range of devices.
One of the solutions that addresses this challenge is KubeEdge ![]() . From a control plane perspective, it extends Kubernetes with a set of dedicated controllers and other components designed to orchestrate edge computing workloads and manage IoT devices.
. From a control plane perspective, it extends Kubernetes with a set of dedicated controllers and other components designed to orchestrate edge computing workloads and manage IoT devices.
Apart from typical worker nodes, KubeEdge introduces a special class of nodes called edge nodes. They can represent both normal and resource-constrained entities deployed in different types of edge locations. Edge nodes are dedicated to running different kinds of edge workloads and they require much less compute resources to operate compared to standard Kubernetes worker nodes. They communicate with a remote Kubernetes master node, which can be deployed in a central location, e.g., in the cloud. If low latency is required for this purpose, a QUIC protocol can be used instead of WebSocket, which is a default option in KubeEdge. To manage IoT devices, KubeEdge uses logic implemented by several components and mechanisms (including Device Twin or Device Management Interface). One of these is Mappers, which handle communication between edge nodes and physical IoT devices using various protocols, such as Modbus, UPC UA, or Bluetooth.
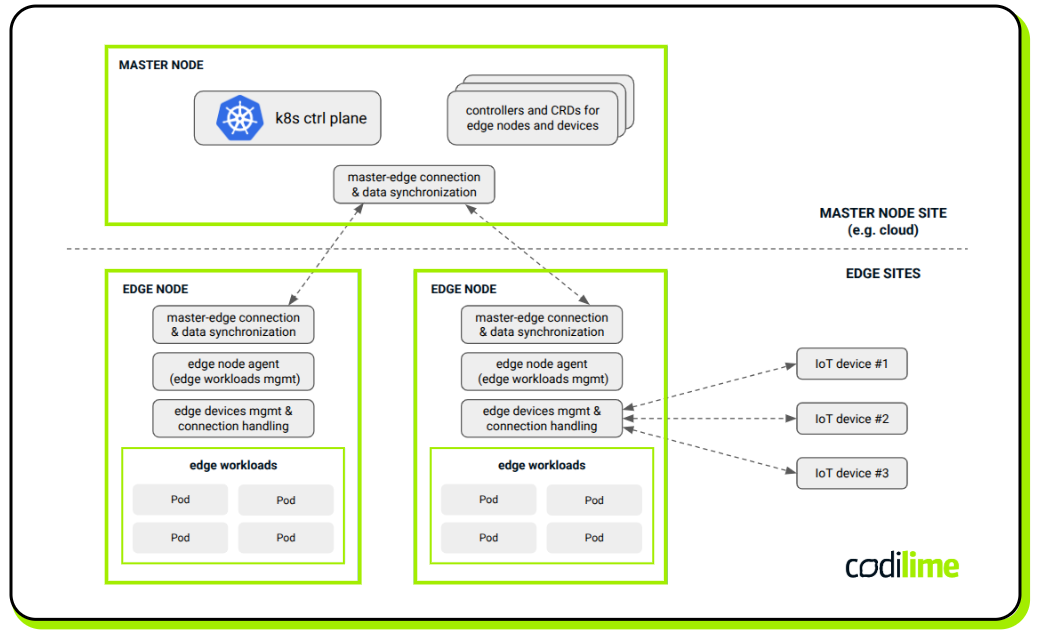
There are also other Kubernetes-based projects that extend its functionality to support edge workloads and manage IoT devices. For example, OpenYurt ![]() is a solution similar to KubeEdge in many aspects. It manages multiple edge nodes located at edge sites, using a centralized Kubernetes control plane located at the cloud site. Akri
is a solution similar to KubeEdge in many aspects. It manages multiple edge nodes located at edge sites, using a centralized Kubernetes control plane located at the cloud site. Akri ![]() , on the other hand, focuses on IoT. It extends the Kubernetes device plugin
, on the other hand, focuses on IoT. It extends the Kubernetes device plugin ![]() framework and provides new functions to easily discover IoT devices with which workloads deployed in the cluster can then communicate and use.
framework and provides new functions to easily discover IoT devices with which workloads deployed in the cluster can then communicate and use.
Network automation and orchestration via Kubernetes
Kubernetes, by its very nature, has a lot to do with networking, as clusters consist of many nodes, and proper communication between workloads, as well as with the outside world, must be ensured. Therefore, Kubernetes provides many mechanisms to cover these aspects, such as attaching Pods to a network (CNI ![]() standard plus network plugins), effective communication within a cluster (Kubernetes Services
standard plus network plugins), effective communication within a cluster (Kubernetes Services ![]() ), or traffic handling at higher layers (Ingress, Gateway API
), or traffic handling at higher layers (Ingress, Gateway API ![]() , service meshes) as some applications deployed there may require.
, service meshes) as some applications deployed there may require.
However, as already mentioned, all this is carried out for connectivity and proper traffic forwarding inside a cluster. But what if you could use Kubernetes for a completely different purpose, i.e., as a network orchestration/automation engine to manage a wide range of network entities, like physical or virtual/containerized network devices, that are not necessarily deployed in the cluster (see Figure 6)?
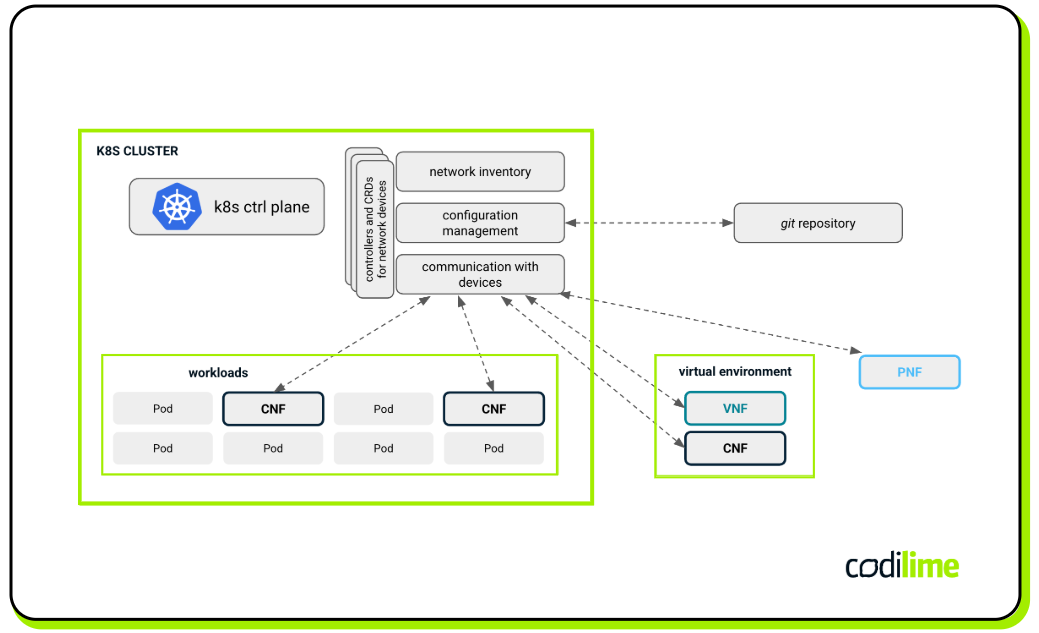
The Kubenet ![]() project takes up this challenge. The idea is to provide support for typical network operations such as discovery, provisioning, config management, etc., performed from a single unified platform based on Kubernetes and leveraging its native orchestration mechanisms. These operations can be executed for network devices of various types and coming from different vendors.
project takes up this challenge. The idea is to provide support for typical network operations such as discovery, provisioning, config management, etc., performed from a single unified platform based on Kubernetes and leveraging its native orchestration mechanisms. These operations can be executed for network devices of various types and coming from different vendors.
To accomplish this, Kubenet introduces several components that together provide the required functionality, each responsible for different aspects of the process. The first is a comprehensive inventory subsystem called Kubernetes Identities (Kuid). It defines a wide range of objects representing different networking resources (e.g. Region, Site, Rack, ModuleBay, Module, Cluster, Node, NodeSet, Link, Endpoint) adequate for on-premise or cloud-native environments (or for both) as well as the so-called “identifiers” (e.g. IPAM, VLAN, VXLAN, ASN, ESI) that facilitate the precise identification of resources within networking environments. As you may notice, the ‘identifiers’ objects reflect the notions present in real networking, like IP addresses, VLANs, and Autonomous Systems, as they are typically used to facilitate network segmentation or routing. The objects defined within Kuid have their specific parameters and offer flexibility in defining user-specific attributes.
Another important question is how to pass configuration to devices managed by Kubenet in an effective way. Particularly, the configuration can be defined as a YAML-based manifest, following the Kubernetes convention. This is appropriate to maintain consistency. However, the problem is that network devices will not normally consume such config format as their NBI protocols do not support it. This issue is addressed by the Schema Driven Configuration (SDC) component. It allows mapping a config manifest to a YANG-based configuration. YANG is a data modelling language that can be used to model network data, both config and state information. After serialization to the proper data format like XML or Protobuf, the config can be sent to a given network device using NETCONF or gNMI, respectively.
Finally, it is worth mentioning that Kubenet also supports a GitOps approach. This is possible thanks to the Package Server (pkgserver) component which enables interaction with version control systems such as git that can maintain network configurations to be applied to the network.
Based on the above-mentioned mechanisms, Kubenet aims to support various use cases, including data center networking, WAN networking, access/campus networking, and others.
Summary
The solutions discussed above demonstrate the versatility of Kubernetes in the context of its orchestration mechanisms. By using appropriate extensions, you can successfully leverage the Kubernetes platform for specific use cases. Importantly, they are not limited to workloads hosted in the cluster. External entities, such as network devices or IoT devices, can also be managed in this way.
The idea of using Kubernetes as a foundation for these types of solutions should not be very surprising. While creating solutions from scratch can be very inspiring and lead to breakthrough innovations, sometimes it is worth considering reusing well-known, mature software that has proven its value over the years.
From a programming perspective, it is much easier because you get a set of ready-to-use mechanisms right out of the box, such as ways to define APIs, store data, or get information about changes in the system state. You do not need to perform a detailed analysis of how to design a well-functioning system. Your job is simply to add new business logic (following the rules and patterns defined within a Kubernetes framework) that is missing for your use case. This saves time and can be a much more straightforward way to achieve your goals.


