


Almost every day, we hear about the launch of a new large language model (LLM), many of which are so large and complex that testing them on our local computers is simply not feasible. The computational power and memory requirements of these advanced models often exceed the capabilities of typical personal computers, making it challenging for researchers, developers, and enthusiasts to experiment with them without access to high-end hardware. In such cases, using cloud resources can be a solution for you.
In this article, I will guide you step-by-step through the process of preparing the resources needed to successfully run LLMs on AWS.
Understanding SaaS and open-source models
Large language models can be divided into two categories: SaaS models, also known as closed-source LLMs, and open-source models. Each category has its unique characteristics, benefits, and drawbacks which can influence the choice depending on the specific needs and constraints of the users.
Closed-source LLMs
SaaS models are often commercial products requiring licenses or subscriptions for use. Notable examples of closed-source LLMs include OpenAI’s GPT-4 and GPT-3.5, as well as Anthropic’s Claude, Sonnet, and Haiku. The details of their training data, algorithms and overall architecture are usually not publicly available. One of the main benefits of SaaS models is their ease of use. These models are hosted and maintained by the providers, so users do not need to handle deployment, which simplifies the process significantly.
Additionally, companies benefit from clear legal agreements and high-level support, which includes detailed API documentation, making integration and troubleshooting much easier. However, there are some drawbacks. One major issue is the dependence on the vendor for maintenance and updates.
Furthermore, the closed-source nature of these models can pose significant challenges in understanding their decision-making processes. That makes it difficult to audit the models, potentially leading to problems of trust and accountability.
Pros of closed-source LLMs:
• ease of use,
• high-level support,
• clear legal agreements,
• comprehensive documentation.
Cons:• vendor dependency,
• lack of transparency regarding their architecture,
• potential difficulty of understanding decision-making processes.
Open-source models
Open-source models represent an alternative approach in the realm of LLMs. These are language models whose source code is publicly available, allowing anyone to access, use, modify, and distribute them. This allows for modifications to suit specific needs, providing a high degree of flexibility and customization.
However, open-source LLMs also come with their own set of challenges. Security issues can be a concern, as open-source models may be vulnerable to exploitation. Integrating open-source LLMs into existing systems can pose significant challenges, potentially leading to compatibility issues that require additional effort and expertise to resolve.
Lastly, there are intellectual property concerns; some companies may hesitate to use open-source LLMs due to worries about IP, particularly if the model was trained on proprietary or sensitive data. These concerns can complicate the decision to adopt open-source solutions, despite their many advantages.
Pros of open-source models:
• free to use (though some models may have restrictions or require licensing for commercial use),
• modifiable to suit specific needs,
• robust community support,
• transparency in architecture and development.
Cons:
• potential security vulnerabilities,
• integration challenges,
• infrastructure for deployment required,
• intellectual property concerns.
When employing open-source LLMs in your AI solutions, you need to consider how to prepare the required infrastructure to host them. Our local machines are often not strong enough to test or run these models. Therefore, I will soon show you how to set up and host these models on AWS efficiently.
Model parameters
When discussing large language models, it’s crucial to understand several fundamental concepts to grasp how these models function and what makes them effective. One key term is model size, typically measured by the number of parameters it contains. In the context of LLMs, a parameter refers to an internal variable within the model that is adjusted during training to help the model make accurate predictions or generate relevant text.
Parameters are primarily made up of weights and biases in the neural network. These elements are the building blocks that determine how input data, such as words or sentences, is transformed into output, such as a prediction or a generated text. To learn more about parameters, check our previous article. The size of a language model can significantly impact its performance and accuracy.
Generally, larger models excel at complex tasks and datasets because they have a greater capacity to learn intricate patterns and relationships in the data. For example, models with millions or billions of parameters can understand and generate human-like text more accurately than smaller models due to their extensive learning capabilities.
Another essential term is training data, which refers to the dataset used to train the LLM. The quality and quantity of this data greatly influence the model’s performance. As the saying goes, “garbage in, garbage out” – if the training data is of poor quality, the output from the model will also be poor. High-quality, diverse training data enables the model to learn a wide range of linguistic patterns and contexts, making it more versatile and reliable in generating accurate text. On the other hand, insufficient or biased training data can lead to models that perform poorly or exhibit undesirable biases.
Hyperparameters are settings that control the training process of the LLM. These settings, such as learning rate and batch size, can be fine-tuned to enhance the model’s performance on specific tasks. Adjusting hyperparameters is a critical part of training as it can significantly affect how well the model learns from the data. For instance, the learning rate determines how quickly the model adjusts its parameters based on the training data. A rate that is too high can lead to unstable training, while a rate that is too low can result in slow learning.
To illustrate model size, consider the example of “Mistral 7B”. This name indicates that the Mistral model has 7 billion adjustable parameters. These parameters are used to learn the relationships between words and phrases in the training data. The more parameters a model has, the more complex it can be, allowing it to process and understand more extensive and nuanced data.
Understanding model size is also important for practical reasons, such as memory requirements. For instance, a model like Mistral 7B, with its 7 billion parameters, requires significant memory. Assuming each parameter occupies 4 bytes, the memory required for Mistral 7B is approximately 28 GB (7 billion times 4 bytes). This highlights the need for substantial computational resources to run large models effectively. The considerable memory requirement means that running such models on standard personal computers is often impractical, necessitating the use of powerful hardware or cloud-based solutions to manage and utilize these advanced models efficiently.


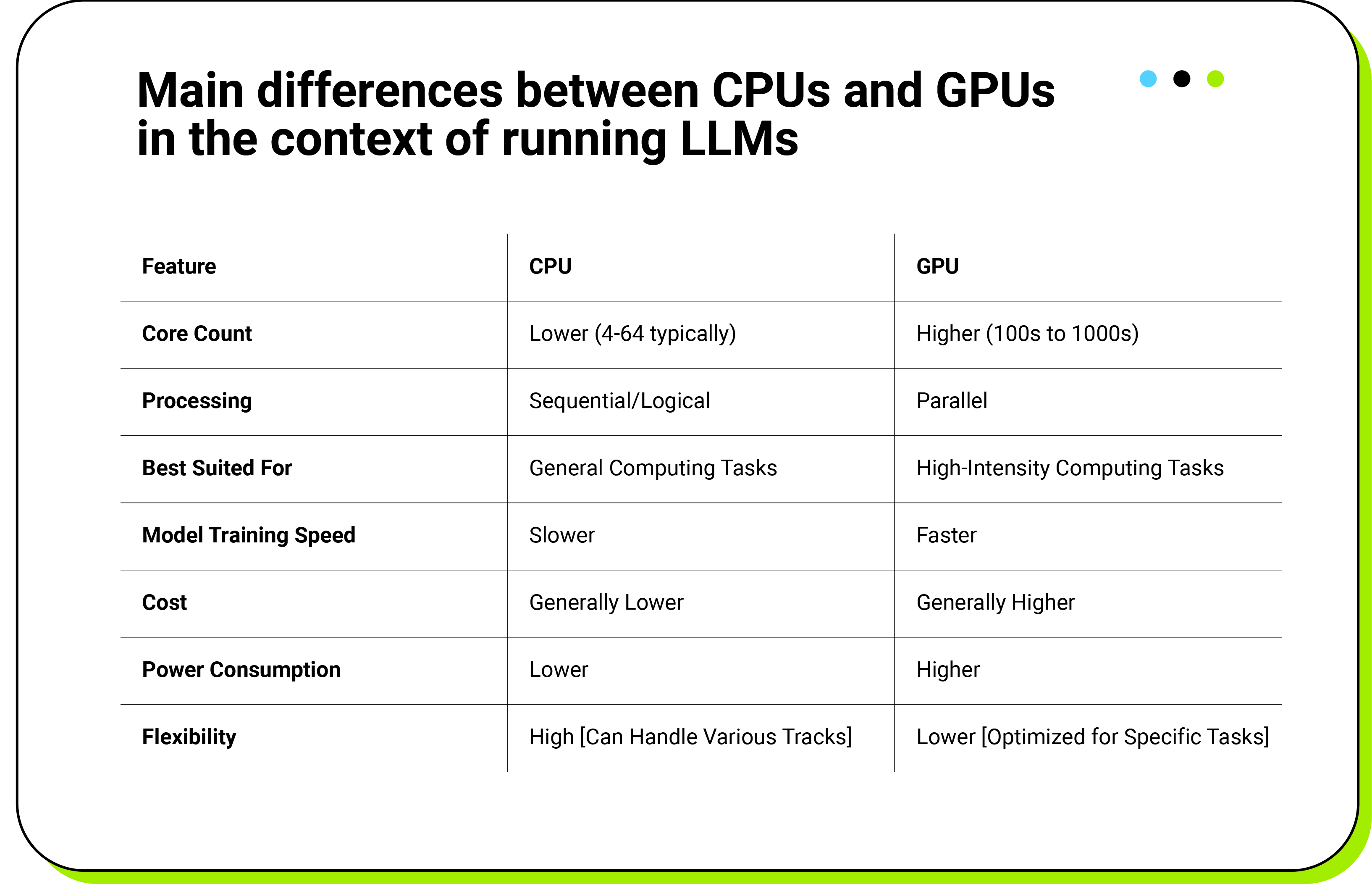
CPU vs. GPU
CPU vs. GPU - we’re discussing this aspect as well because we’ll soon be configuring appropriate AWS resources to run some models. Before making these adjustments, it’s important to understand the differences between CPUs and GPUs.
Central processing units (CPUs) are the processors found in almost all computing devices. They handle a wide range of tasks, from running operating systems to applications and some AI models. While CPUs are versatile and can manage various tasks efficiently, they have limitations when it comes to running large language models (LLMs). This is primarily due to their limited number of cores, which makes them slower for tasks that require a lot of parallel processing. CPUs are typically suited for sequential and logical processing tasks, making them ideal for general computing but less efficient for high-intensity computing tasks like training complex AI models.
Graphics processing units (GPUs), originally designed for graphics, have become crucial for AI and ML tasks. GPUs have hundreds or thousands of smaller cores, allowing them to perform many operations simultaneously. This parallel processing capability makes GPUs much faster than CPUs for training and running LLMs, as they can handle large amounts of data and execute multiple operations per second. GPUs excel at high-intensity computing tasks and significantly speed up the training and inference processes for complex models.
The complexity of the model you are working with plays a significant role in determining whether to use a CPU or GPU. Smaller models or simpler tasks might run efficiently on a CPU without any issues. However, as the model’s complexity increases, the need for parallel processing grows, making GPUs the more suitable option. This is because GPUs can manage the increased computational load more effectively, providing faster and more efficient processing.
Budget is also an important factor to consider when choosing between CPUs and GPUs. Generally, GPUs are more expensive than CPUs, reflecting their enhanced capabilities and performance. The environment where you plan to deploy your models also matters. Some setups might offer better support and optimization for either CPUs or GPUs, influencing your choice based on the specific requirements and constraints of your infrastructure.
Setting up the environment on AWS
Amazon EC2 G5 instances
To effectively run large language models on AWS, we will set up an EC2 instance. Specifically, we will be using a G5 ![]() , an NVIDIA GPU-based instance, designed to handle graphics-intensive and machine learning tasks efficiently.
, an NVIDIA GPU-based instance, designed to handle graphics-intensive and machine learning tasks efficiently.
Our example task is to deploy the Mistral 7B ![]() model, which requires substantial memory and GPU resources. The Mistral 7B model, released by Mistral AI under the Apache license, is designed for high-performance inference, necessitating a robust hardware setup.
model, which requires substantial memory and GPU resources. The Mistral 7B model, released by Mistral AI under the Apache license, is designed for high-performance inference, necessitating a robust hardware setup.
Preparing the environment for Mistral 7B instruct
-
Selecting the AWS Machine:
• Visit the AWS EC2 Instance Types page
 and navigate to accelerated computing. One GPU is enough for us. However, we need to be careful with memory because while running model inference, we need to load the model first. The NVIDIA A10 GPU with 24 GB of virtual memory is well-suited for this purpose (with an assumption that we’ll shrink a model a bit when using it as it normally requires ~28 GB of memory), which is why we have chosen the G5 instance type for our deployment. Let’s safely select g5.4xlarge.
and navigate to accelerated computing. One GPU is enough for us. However, we need to be careful with memory because while running model inference, we need to load the model first. The NVIDIA A10 GPU with 24 GB of virtual memory is well-suited for this purpose (with an assumption that we’ll shrink a model a bit when using it as it normally requires ~28 GB of memory), which is why we have chosen the G5 instance type for our deployment. Let’s safely select g5.4xlarge. -
Launching the instance:
• Log into AWS Management Console. Start by logging into AWS Management Console. If you don’t have an account, you’ll need to create one.
• Navigate to EC2 dashboard: from the AWS Management Console, navigate to the EC2 Dashboard by selecting “EC2” under the “Services” menu.
• Launch instance: click on the “Launch Instance” button to start setting up your new EC2 instance and name your instance (e.g. mistral-test).
• Choose an Amazon Machine Image (AMI). Select an Amazon Machine Image (AMI) that suits your needs. For machine learning tasks, you might want to select an AMI that comes pre-configured with NVIDIA drivers, CUDA, and PyTorch already installed.

• Select Instance Type: On the “Choose an Instance Type” page, select a G5 instance. G5 instances come with NVIDIA A10G Tensor Core GPUs, which are optimized for AI and machine learning tasks. We are choosing here the g5.4xlarge instance type.
• Create or select a key pair for SSH access.
• Configure storage: Our model requires about 20 GB of memory, but let’s increase it to 100 GB for testing and safety purposes, as well as to accommodate additional libraries and data.
• Launch the instance: Note that g5.4xlarge requires 16 vCPUs, which you might need to request from AWS support if not already available in your account.
-
Connecting to the Instance:
• Check the public IP assigned to your instance.
• You can connect to the instance in various ways, such as using regular SSH or through different IDEs, depending on your preference. For example, you can use Visual Studio Code: open Visual Studio Code, go to the bottom left, and click “Connect current window to host.” Configure your host with the IP address and SSH key—remember to provide the full file path to your key.

• Once connected, verify GPU availability by running nvidia-smi in the terminal. You should see almost 24 GB of vRAM available.

-
Setting up the model:
• Refer to the Hugging Face Mistral 7B model card
• Create a new file and paste the code from Hugging Face or write your own piece of code.
Note: Remember to install all the necessary packages that your script requires!
Remember, when you are not using the instance, stop it to avoid incurring charges for unused resources.
By following these steps, you will have a setup on AWS capable of efficiently running the Mistral 7B model, allowing you to leverage the advanced capabilities of this large language model for your projects.
For more information watch our video added below where we show the entire process as a hands-on demonstration.
Conclusion
We explored the differences between SaaS and open-source LLMs and highlighted the importance of choosing the right computational resources when deploying open-source LLMs on your own. The tutorial covered setting up AWS EC2 instances, particularly G5 instances with NVIDIA GPUs, ideal for demanding machine learning tasks. Using cloud resources (from AWS or other providers) obviously costs money, so you should take into account what purpose you use them for (quick evaluation of a given model or a target deployment in a production environment) and what your budget is.
In some cases, a cheaper solution may be to purchase dedicated hardware. This is determined by your specific use case and business needs. If you want to find the best solution for your needs, explore our data science services.


