


AI is no longer a futuristic buzzword; as a QA Engineer, it’s becoming part of my daily toolbox. I’m not just seeing AI in research papers or conference slides; I’m using it to write better tests, debug issues faster, and make smarter choices about what to automate and why.
The great thing is that I really didn't need to alter my workflow to gain these benefits. Instead, I pragmatically integrated AI into the tools and workflows I was already using. Whether that means writing test code with GitHub Copilot, brainstorming test ideas with ChatGPT, or using the built-in AI prompts from Playwright to view failures.
These are real-life examples of solving actual testing challenges with AI, not hypothetical use cases. These are the kinds of things we work on every day: writing automation, debugging flaky tests, planning test coverage, and staying on top of complex systems.
Along the way, I’ll highlight not only the benefits but also the gotchas, like when AI suggests the wrong logic, or subtly reinforces flawed assumptions if we’re not paying attention.
If you’re curious about how to make AI truly useful in your testing work, without getting caught up in hype or losing control over quality, this guide is for you.
Smarter Coding with GitHub Copilot
When I am writing automated tests, GitHub Copilot ![]() speeds it up by handling repetitive patterns and letting me focus on the test logic. Whether I'm using Playwright
speeds it up by handling repetitive patterns and letting me focus on the test logic. Whether I'm using Playwright ![]() or PyTest
or PyTest ![]() , or any other testing framework, Copilot is running in the background and predicting what the following line of code will be based on what I'm writing. Instead of just completing superficial syntax, it often anticipates full test flows, covering setup, execution, and assertions, based on the broader context of the project.
, or any other testing framework, Copilot is running in the background and predicting what the following line of code will be based on what I'm writing. Instead of just completing superficial syntax, it often anticipates full test flows, covering setup, execution, and assertions, based on the broader context of the project.
For example, when I type out a new test function in a PyTest file with the function signature ‘def test_’, Copilot instantly suggests ‘test_user_login_successful’. I type that in, and it fills out the test details for me: user creation, a call to the login endpoint, and asserting the expected status code. It gets me to a working baseline in seconds.
In a Playwright test, I can start by typing ‘test(‘ and Copilot finishes it with something appropriate like 'top bar sanity'. As I continue typing, it adds more steps like entering the email input, clicking on the reset button, and waiting for the success message. It detects patterns from nearby tests and uses them intelligently.
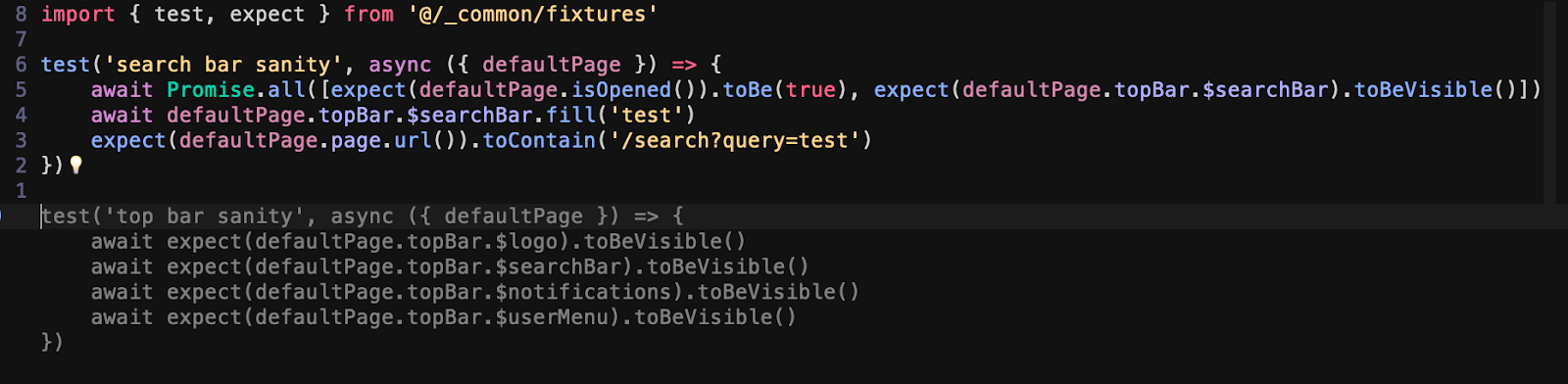
For parameter-driven test data with multiple parameters, it can assist in generating huge test data structures in JSON, XML, or other formats. It accelerates writing such data, particularly when its format is repetitive.
Copilot is useful when switching between projects or languages. I don’t have to pause to look up setup syntax, assertions, or mock methods. It often gives me the correct form instantly, keeping me in the flow longer and reducing context switching.
But Copilot isn’t flawless. I’ve caught it suggesting logic that’s entirely off the mark. In one PyTest suite, it generated a test that passed None as a payload simply because it resembled other test structures. In UI tests, Copilot sometimes autocompletes selectors that don't exist or attempts interactions with elements before the page has fully loaded. These mistakes aren’t always obvious, which makes blindly trusting the tool a risky move.
Copilot often writes solid code, definitely good enough to get the job started, though not always polished. It’s like a first draft from a junior engineer: functional, but worth reviewing. Skipping that step by being overly trusting risks merging buggy or misleading tests into your codebase.
By defining reusable library functions or following the Page Object Model (POM) in your UI tests, you give Copilot a clearer and more consistent codebase to work with. Then it works better and offers smarter, context-aware completions that go beyond basic code snippets. It makes creating new tests feel as intuitive as building with LEGO.
Used well, Copilot speeds me up. I spend less time on boilerplate and more time exploring edge cases, honing assertions, and driving test coverage. It doesn't replace my judgment; instead, it frees it.
Brainstorming Test Cases with ChatGPT
When I'm running out of fresh test ideas or wish to verify my assumptions, I resort to LLM chat. My go-to is typically ChatGPT ![]() , being the most versatile and convenient to use. It's like having a second QA brain—one that thinks quickly, impartially, and does not suffer from tunnel vision following hours of looking at the same feature.
, being the most versatile and convenient to use. It's like having a second QA brain—one that thinks quickly, impartially, and does not suffer from tunnel vision following hours of looking at the same feature.
Suppose I'm testing a user registration form. I start by copying a section of the HTML or a short description like, "A form with fields for email, password, and confirm password. Password should be a minimum of 8 characters." I say to ChatGPT, "What would be the test cases you would automate for this? Within seconds, I have a list that captures the basics - happy paths, missing fields, invalid email addresses - but also less-obvious problems like password mismatches, SQL injection attempts, or whether the password field has autocomplete disabled.
In another example, I pasted part of an API schema into the chat and posed the question, "What are some edge cases I might have missed if I'm testing this endpoint?" It highlighted such things as null values on optional fields, pagination boundary conditions, and unexpected content types—things I hadn't yet considered.
If you are dealing with live websites, a chat can help in formulating a test plan or suggesting test case ideas using a web search. Simply request, "Give some ideas for test cases of http://…" to find out about coverage, relevant test cases, and add to your test plan.".
The most valuable aspect for me is the ability to use it to scrutinize my own test plan. Having created some test cases myself, I can query it, "What test cases am I lacking for this case?" It has a tendency to push negative or security-focused tests to mind that would not otherwise be at the forefront of my thinking. This type of collaboration keeps me from blind spots and adds coverage.
I've also used it to reverse-engineer ideas from other code. When reading through a React component or Python function, I chop it and paste it into the chat and say, "What tests should encompass this logic?" It breaks down conditional branches and gives me a list of what to test.
Naturally, it's not perfect. ChatGPT sometimes suggests impossible inputs or way too generic tests, but these are simple to weed out, though. What does make a difference is that it allows me to experiment with more directions without delay and makes me think about what I'm overlooking.
When I use ChatGPT while doing exploratory testing or creating early-stage plans, I build stronger, fuller test cases, and I do it in half the time.
Debugging with Playwright’s Built-In AI Prompt
When a test fails, my first instinct is to open the logs, scroll through the trace, and look for the usual suspects—timing issues, missing selectors, or unexpected page transitions. But since Playwright version 1.51 ![]() , I’ve started using the new report feature “Copy as prompt” to speed up this process, and it’s made a noticeable difference. The AI prompt is displayed directly in the Playwright HTML report, trace viewer, or in UI mode. In case a test fails, I press "Copy as Prompt" with the full error description that I can easily copy-paste into any LLM chat. If I copied something, it includes instructions for LLM chat, test information, error information, an aria page snapshot, and a snippet of test source. The above should be enough for LLM to figure out what was going on and what the reasonable fixes are.
, I’ve started using the new report feature “Copy as prompt” to speed up this process, and it’s made a noticeable difference. The AI prompt is displayed directly in the Playwright HTML report, trace viewer, or in UI mode. In case a test fails, I press "Copy as Prompt" with the full error description that I can easily copy-paste into any LLM chat. If I copied something, it includes instructions for LLM chat, test information, error information, an aria page snapshot, and a snippet of test source. The above should be enough for LLM to figure out what was going on and what the reasonable fixes are.
Recently, I encountered a flaky test that would occasionally fail when clicking from a dashboard to a settings page. The page appeared normal in the screenshot, and Playwright’s selector was correct, but the click step kept timing out. I reran the test case, and when it failed, I copied the provided Playwright code and pasted it into ChatGPT. The AI analyzed the trace and suggested that the button might have been covered by a loading spinner. It asked if waiting wouldn't be a better option, since the spinner would likely disappear after a wait, allowing the click. It guided me to the exact state and timing issue without me having to figure it out manually.
Another time, I employed it to correct an input field that was not receiving a value. The AI told me that the element likely wasn't interactable at that moment and advised me to use await page.waitForSelector() with the visible: true option. I hadn't realized that because the page had quirky layout shifts on animations—something that's hard to realize when scrolling through trace logs. So that advice was a game‑changer.
This intrinsic prompt doesn't always win, but it gives me a good starting point. Instead of blindly adjusting delays or inserting stick waits in here randomly, I have a targeted hypothesis. It's like pair debugging with somebody who understands the test engine's view of the page, and never reads traces with tired eyes!
My favorite aspect is how it reduces trial-and-error cycles. With traditional debugging, I'd likely re-run a flaky test five or six times, adjusting timeouts or inserting logs. Now I typically fix the root cause in one or two cycles. The Playwright AI prompt doesn’t replace extensive debugging but makes the process more efficient, particularly at the initial stages of debugging, or provides a solution for minor issues. It relies on data that can be extracted from developer tools, Playwright DOM snapshots, and full test source code, which calls for further inquiry in the case of complex problems. However, for small bugs, it offers an easier way to find the issue. The only feature I’d still like to see is the ability to bypass the copy-and-paste by having the response from LLM chat printed directly into the test report.
Overall, it helps me address flaky tests quicker, keeps false failures in check, and enables me to work on creating sound, dependable automation.
Using LLMs as Oracles to Predict Expected Output
When I test complex systems—specifically those involving business logic or data mapping—I struggle at times to know the "expected output" without spending time reading documentation or reverse-engineering code. That is where LLMs come in handy. Now, I utilize them as de facto oracles: to make informed hypotheses about what a good output should look like, based on inputs and business context.
I had just spent time working on an app that had about a dozen types of accounts and a pretty complex authorization system. The authorization was not well documented, and manually testing the app was time-consuming. So, I pasted the source code in ChatGPT and instructed, ‘Create a spreadsheet of account rights’. The model ran through every account's rights and generated the spreadsheet for me. I took that and plugged it in to complete an assertion in the automated test.
In another case, I used this approach to test a function that parsed user-uploaded CSVs. I described the input structure and included an example row. ChatGPT generated the expected parsed object and even specified how edge cases like missing columns or incorrectly formatted dates were supposed to be handled. That gave me a definite point of reference against which to verify my test results.
This style comes in handy in early test writing, when I must verify my understanding of the logic or quickly scaffold tests without building full data setups. I use it to sanity-check my own assumptions as well: ‘Am I reading this rule right?’ or ‘Would the system actually return this value?’
Of course, I don't have unshakeable faith in the model. LLMs can hallucinate or apply logic inappropriately, especially when the rules are poorly defined. But even when it's wrong, the process forces me to state what I had assumed myself, and that alone increases the quality of the test.
The use of LLMs as oracles will not replace official specs or claims, but it's convenient when I have a quick reference output requirement. It's like getting someone to sanity-check my thoughts—except this person is on call 24/7.
Generating Test Plans with NotebookLM
NotebookLM ![]() is a research and summarization tool created by Google for artificial intelligence. You can upload GSuite documents, webpage URLs, YouTube video URLs, and text notes into a "notebook," and then ask natural-language questions to extract insights, generate summaries (also in podcasting form), or uncover relationships between files. It's having a clever assistant work on everything you give it, and who gets it.
is a research and summarization tool created by Google for artificial intelligence. You can upload GSuite documents, webpage URLs, YouTube video URLs, and text notes into a "notebook," and then ask natural-language questions to extract insights, generate summaries (also in podcasting form), or uncover relationships between files. It's having a clever assistant work on everything you give it, and who gets it.
When boarding a new project or beginning to try out a feature with sparse documentation, I usually waste hours gathering context—user stories, wikis, and source code. NotebookLM can help reduce that time to a fraction. It is similar to having a research assistant read all the project documents and help me create coherent test plans in a timely manner.
To use it, just upload some relevant files: product specs, API specs, acceptance criteria, even planning meeting notes. I also like to refer to critical sections of the codebase, such as controllers, routes, or UI components. Then I ask it straightforward questions such as, "What are the most critical areas to test for the payments module?" or "What edge cases do I want to test when testing account creation?"
NotebookLM responds with testable abstractions. You might make them point to noted constraints (e.g., "only one promo code can be applied per checkout"), key flows ("guest checkout must bounce to login on return visits"), or high-risk locations ("data validation logic is duplicated between multiple endpoints"). You might immediately transform them into formalized test charters or checklist entries.
NotebookLM doesn't just create slabs of text. It combines it with reference to sources. When I feed it both documentation and implementation code, it cross-connects them and tells me how the system actually works in the world, rather than simply how it was supposed to work on paper.
I can imagine that this tool can be a lifesaver when joining new teams. I no longer need to schedule infinite context meetings just so I can ask, "What should I be testing here?" I get the initial pass by NotebookLM, then follow up with more targeted questions.
Used effectively, NotebookLM rewrites the test planning process from a time-wasting, manual drudge through disparate documents into a fast-paced, focused discovery. It turns patchy project wisdom into a usable test plan.
Other than that, NotebookLM is actually a great research assistant for your collected materials. You can easily add all sources and queries. It gives you a good summary regarding the topic, and the podcast feature is great if you simply want to listen to a conversation in the background.
Of course, it should be used according to your company’s privacy policy, and sharing personal data, confidential information, and other secrets is not recommended. I also hope NotebookLM will support more source types like GitHub repositories, video/audio materials from YouTube, spreadsheets, etc. The current choice seems too restrictive. It would also be nice to have a feature that warns us about sharing sensitive information, with an option to discard it.
Accelerating Automation with Cursor and MCP Servers
When you have to switch to full AI, especially when building or rebuilding automation, you can use technologies like Cursor ![]() and MCP
and MCP ![]() (Model Context Protocol) servers to eliminate friction and collapse feedback loops. Cursor, an AI-powered IDE based on VS Code, has become a favorite within many developers' toolchains in recent times. It all folds code navigation, inline editing, and AI assistance into one environment. I often use it to create scaffolding for tests, rewrite flaky test code, and clarify foreign code. What differentiates Cursor is that it has a strong understanding of the codebase. Cursor's user interface supports and signals the context of the questioned questions (file, code snippet, etc.).
(Model Context Protocol) servers to eliminate friction and collapse feedback loops. Cursor, an AI-powered IDE based on VS Code, has become a favorite within many developers' toolchains in recent times. It all folds code navigation, inline editing, and AI assistance into one environment. I often use it to create scaffolding for tests, rewrite flaky test code, and clarify foreign code. What differentiates Cursor is that it has a strong understanding of the codebase. Cursor's user interface supports and signals the context of the questioned questions (file, code snippet, etc.).
I am able to highlight a test case and ask, "What's this checking for? " or "What setup is missing here? " and it responds with appropriate insights—typically citing corresponding fixtures or missing mocks.t can trace the logic, detect missing waits or flaky selectors, and suggest resilient alternatives. What is worth doing is combining tools like Cursor, which utilizes an LLM, and an MCP server.
MCP is an open-source concept that standardizes a way AI models access, update, and store contextual information through external MCP servers. These servers manage user-specific data (such as tool usage, past interactions, preferences, or task progress). An AI model can query this data to provide more coherent, rich, and personalized responses in a given context. Different MCP servers may serve various roles: some focus on memory storage, others can handle user profiles or collaborative contexts. By connecting AI models ![]() with multiple MCP servers
with multiple MCP servers ![]() , it can provide rich and dynamic responses in contexts across diverse domains and/or applications.
, it can provide rich and dynamic responses in contexts across diverse domains and/or applications.
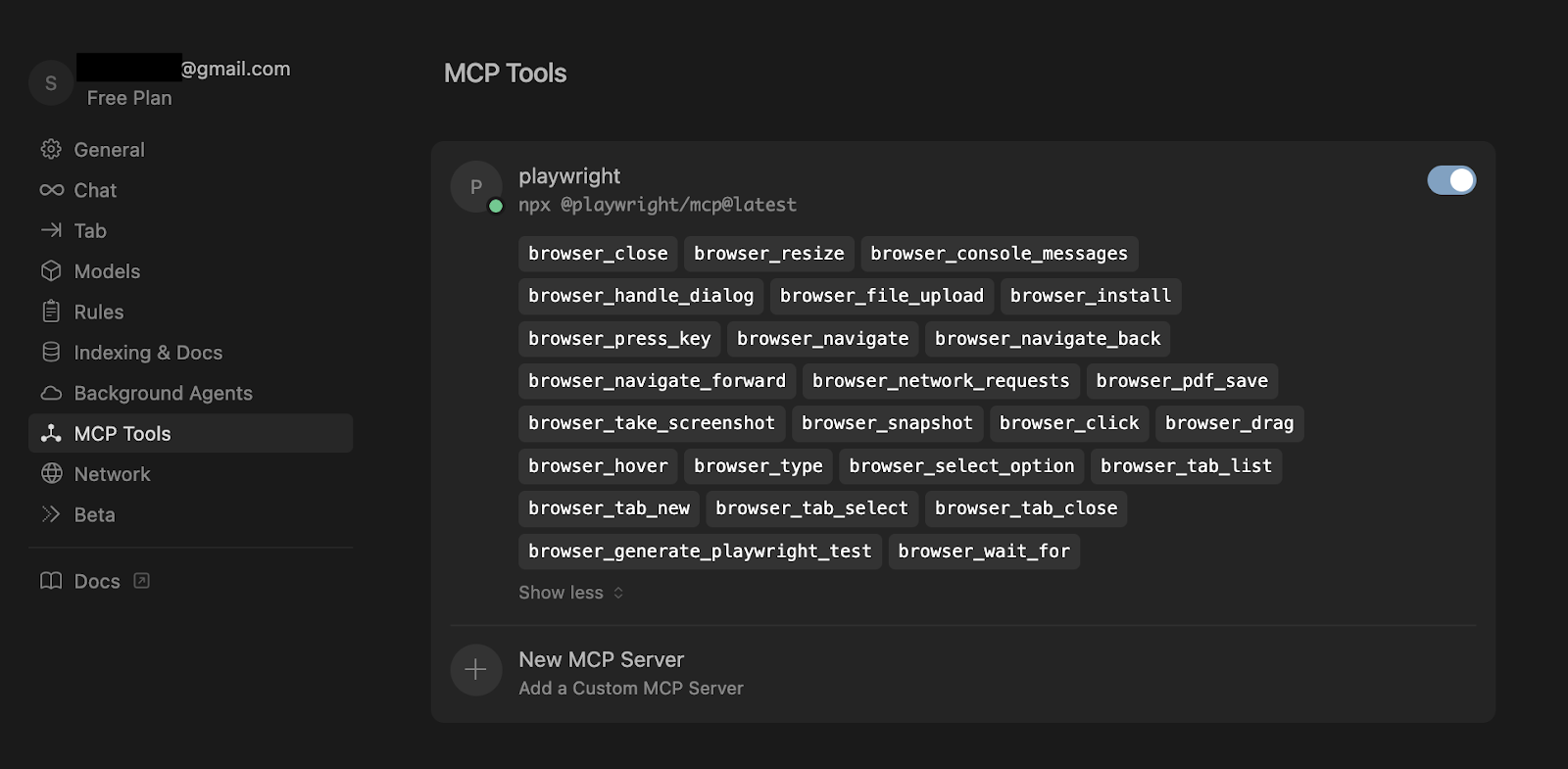
As an Example, Playwright MCP ![]() (see Screenshot 1) gives context about running Playwright tests, selector types, and browser navigation to LLM. It is quite convenient because we do not have to teach the LLM to read a Playwright library and learn it in a manner that it will have the context of that framework to work out of the box. This gives a chat the ability to check test results and provide corrections on the fly, generate playwright commands to run tests, etc. Recently, I used Cursor to convert some Playwright tests from TypeScript to Python. Instead of rewriting each one manually, I told it, "Convert TypeScript Playwright Test project to Python. Put all the converted files into a new Python directory.". Then, after refactoring all the test cases, run and try to fix errors". The experience was not as good as I expected; I had to determine dependencies and libraries to employ and answer a lot of further questions. For example, the test was rewritten in Python (which is actually small, considering that JS and Python versions are very similar), but AI didn't rewrite all the required POM and test setup functions. However, after a few iterations, I managed to convert some of the code just by using AI.
(see Screenshot 1) gives context about running Playwright tests, selector types, and browser navigation to LLM. It is quite convenient because we do not have to teach the LLM to read a Playwright library and learn it in a manner that it will have the context of that framework to work out of the box. This gives a chat the ability to check test results and provide corrections on the fly, generate playwright commands to run tests, etc. Recently, I used Cursor to convert some Playwright tests from TypeScript to Python. Instead of rewriting each one manually, I told it, "Convert TypeScript Playwright Test project to Python. Put all the converted files into a new Python directory.". Then, after refactoring all the test cases, run and try to fix errors". The experience was not as good as I expected; I had to determine dependencies and libraries to employ and answer a lot of further questions. For example, the test was rewritten in Python (which is actually small, considering that JS and Python versions are very similar), but AI didn't rewrite all the required POM and test setup functions. However, after a few iterations, I managed to convert some of the code just by using AI.
My experience with it is just like teaching a junior programmer and explaining what to do. It's slow, and the response loop is very slow. In a nutshell, I would not use it as a tool for refactoring a project at large because it is not the strongest feature of this AI IDE currently.
What is strong is debugging, documenting, and refactoring the code in small batches and under direct human developer control.
Also, we have to bear in mind that sometimes talking to an LLM will take a lot longer than just jumping into the code and doing it manually, but at least it is nice to have a rubber duck with you who can explain the project to you and give some ideas and patches when needed in the shape of a friendly and familiar UI.
The Challenges of Using AI in Testing
AI tools have become powerful accelerators in my testing workflow—but they’re not magic. I’ve learned to use them with care, especially when it comes to data privacy, reliability, and the temptation to rely too heavily on automation.
Data privacy is at the forefront of my mind, especially when working with sensitive or proprietary code. A majority of AI tools—especially cloud ones—require code, logs, or documentation to be uploaded onto third-party servers. Before uploading them, I always review what data the tool stores, how it uses it, and whether a local or self-hosted solution can work. For example, while working with regulated industries like fintech or healthcare, I would avoid using tools that log prompts externally or store data by default.
Data quality is crucial too. You can only be as good as you're taught. If the documentation is outdated, or the code is nonsense, you'll get bad recommendations—wrong but assertive-sounding answers that superficially sound plausible. I've seen Copilot or ChatGPT get it wrong and suggest the wrong assertion, or read a config file incorrectly and spit out false positives. That's why I treat AI suggestions as pull requests: useful, but never trusted blindly.
My biggest challenge is relying too much on AI. It's simple to allow the model to take charge—create tests, forecast outcomes, and extract bugs. The more I do that, however, the more likely I am to lose the depth of understanding I need to make testing decisions wisely. I've found myself skipping exploratory testing or ignoring edge cases because the AI didn't bring them to my attention. That’s not a flaw in the tool—it’s a reminder that I’m still the critical thinker in the loop.
What's worth noting is that AI tools are evolving rapidly, but they still lack some basic functionality that requires more human input. However, MCP is addressing this issue with promising results, in my opinion.
I've had the best outcomes when I've treated AI like a junior engineer or a clever assistant: fast, helpful, and creative—but not yet accountable. I use it to drive faster, to uncover blind spots, and improve coverage, but I'm still in charge of the quality.
As more of our dev tools are integrated with AI, we'll have to continue to shift the way we interact with it. That includes reviewing what it's doing, knowing its boundaries, and always keeping human judgment in the mix.
Conclusion: AI Is Here, Get Used to It
Summary of used tools:
| Tool | Use case | Benefit |
|---|---|---|
| Github Copilot | Write a test framework and test automation code | Fewer distractions during coding test automation Faster code delivery Streamline the process of writing code |
| ChatGPT (or other LLMs chats) | Develop test documentation (test strategy, test plans, test cases) Audit/review test documentation | Offers a different kind of perspective Provide checklists Can generate ideas Good starting point |
| Playwright prompt generation | Debug a failing automation check | Quicker entry into the debugging process Narrows the search area Can speed up the debugging process in specific conditions |
| NotebookLM | Develop test documentation for already advanced projects | Organize information about the project requirements and implementation Can generate an idea for a test plan and a test strategy Can quickly answer questions in the context of the project’s documentation Onboard new people quicker |
| Cursor (IDE with AI in mind) | Write a test framework and test automation code | Streamline the code-writing process even further than tools like GitHub Copilot. Access to LLM chat without switching the tool AI is aware of the project context, which can be easily adjusted if needed |
| MCPs | Integrating LLMs with testing tools, the project’s code, and documentation | More precise LLM responses Better code hinting Testing tools (e.g., Plyawright), code generation, and debugging Test execution supervision |
AI is no longer hype. It's already transforming how we write, run, and maintain tests. From writing test scaffolding with Copilot, debugging using Playwright's built-in prompt, to generating context-aware test plans with NotebookLM or MCP-equipped systems, I've seen how these tools can eliminate drudgework and liberate more strategic, creative thinking in QA.
The biggest shift? I write less boilerplate and spend more time questioning, "Are we testing the right things?" and "What risks haven't we considered yet?" AI not only accelerates testing, it also gives me space to think more critically about quality.
That being said, AI isn't going anywhere. I believe the most effective testers will be those who understand both the capabilities and limitations of AI. While tools are getting smarter, it's our judgment that makes the work outstanding. So don't put it off. Start incorporating AI into your daily testing routine, one use case at a time. Test, ask questions, learn, and when the tools catch you off guard (which they will), use that momentum to elevate your quality thinking. There's also a pressing question that quality assurance engineers like me can't ignore: how do we test AI? It's not a trivial task, and many projects are still searching for answers. I hope we find a solution soon, as we need reliable, tested AI to drive the AI revolution forward.


