


Ever since the debut of ChatGPT, large language models have taken the limelight. Their breadth of knowledge is nothing short of remarkable. From drafting emails on our behalf to assisting in code development, these models showcase extensive general knowledge. Yet, a notable limitation is their unfamiliarity with specific details related to our companies, such as sensitive documents, company policies, and the like. The idea of interacting with our personal documents through such models is undoubtedly intriguing.
In this piece, we will delve into a method that achieves this very objective. Leveraging the LangChain framework, we've pioneered a way for our chatbot to access and comprehend the confidential data housed in our Confluence pages.
Our Private Slack ChatBot stands as a testament to innovation. Inherently private, it's designed with data sensitivity as the utmost priority. Through this bot, we harness data not only from our Confluence – a comprehensive repository of company benefits, regulations, and employee details – but also from our extensive employee database. These are sensitive datasets that, in line with our information security policy and ISO regulations, must remain confidential. By integrating multi-source information, we offer a seamless and efficient user experience without compromising data security.
Furthermore, by integrating the chatbot with Slack, a staple communication tool for many businesses, we ensure that users can quickly retrieve vital information without ever leaving the Slack platform.

The Evolution of Language Models
Language models started gaining traction in the tech community around 2018. The landscape, however, underwent a major shift with the launch of ChatGPT by OpenAI in late 2022. While transformer architecture-based models like BERT had already showcased their proficiency in understanding language, ChatGPT stood out because of its unparalleled public accessibility. This accessibility ignited a surge in new tools and applications, from chatbots to AI assistants. Even though earlier models were effective, they often adhered to strict patterns. But with the progress driven by ChatGPT, we're now experiencing more dynamic and natural dialogues with AI, marking a significant evolution for the IT world.

Following this evolution, the concept of large language models (LLMs) has further refined and broadened the capabilities of these tools. LLMs, like GPT-4, which is the heart of ChatGPT and its descendants, are not just bigger in terms of data but smarter in terms of functionality. They encapsulate vast amounts of information, pulling from expansive datasets to deliver more detailed and contextually accurate responses.
Another noteworthy development in the LLM landscape is the explosive growth and diversification of models. The market has been dynamically expanding, with new open-source models emerging regularly, catering to various niches and requirements. Simultaneously, there's been a rise in private models tailored to specific business needs, ensuring data privacy and specialized functionalities. Amidst such vast availability, it becomes imperative to discern and choose a model that aligns with one's specific needs. In our experience, the largest and most acclaimed models weren't necessarily the best fit for our use case. Bigger models often come with higher running costs, which aren't always justified by their performance or specific functionalities. The choice and variety available now are staggering, a testament to the rapid advancements and the increasing reliance on LLMs in various sectors.
The sheer scale and adaptability of LLMs have played a pivotal role in transforming the way businesses operate, educators teach, and developers create. By democratizing access to vast knowledge bases and promoting smoother user interactions, LLMs have solidified their place as invaluable assets in the contemporary IT ecosystem.
At the heart of how LLMs operate is the principle of token prediction within a given context. Think of tokens as pieces or chunks of information, often corresponding to words or characters. When given a question (technically, a prompt or a sequence of tokens) an LLM attempts to predict the next most likely token based on the patterns it has learned from its training data. This is much like trying to guess the next word in a sentence after hearing the beginning. However, for LLMs, this "guessing" is done on a grand scale, referencing billions of examples it has previously seen. It's this mechanism that allows them to generate coherent and contextually relevant sentences.
Essentially, by repeatedly predicting the next token in a sequence, LLMs craft responses or complete tasks, making them remarkably versatile in handling diverse queries and prompts.
Here, you can check our data science services.
LangChain Framework
LangChain is a pivotal component in our endeavor to bridge the gap between the capabilities of large language models (LLMs) and the demands of real-world applications. At its core, LangChain is a dynamic library, designed specifically to streamline the implementation and utilization of LLMs for developers. One of its primary functions is to facilitate the effortless incorporation of LLMs with external data sources, be it the vast expanse of the internet or more localized personal files.

A closer look at LangChain reveals its multifaceted features:
Prompts: This ensures flexibility, allowing developers to provide varying contexts to the LLMs.
Models: With its ability to integrate with approximately 40 LLM APIs, it offers a unified platform for both chat and embedding interactions.
Memory: Essential for maintaining the continuity of interactions, it retains the history of the conversation, ensuring context isn't lost.
Indices: Beyond just managing documents, LangChain provides a system that seamlessly merges with vector databases, making information retrieval more efficient.
Agents: Ingeniously, based on the user's input, LangChain can dynamically select the most appropriate tools, optimizing the user experience.
Chains: A standardized interface is provided, making the integration of various LLMs smoother.
It is worth noting that LangChain is an open-source tool that welcomes developers from all horizons to contribute, adapt, and implement. As we delve deeper into this article, our focal point will revolve around the distinctive application of LangChain, particularly its prowess in enabling conversations with personal data. We'll be navigating through key areas like document loading, the nuances of document splitting, and the intricate world of vector storage and embeddings, followed by the methodologies of retrieval and the art of question-answering.
Project Architecture
The architecture of our chatbot is anchored by two fundamental pillars: data extraction and user interaction.
Data Extraction
We extract data from Confluence and scrape it into .txt files, a format that offers simplicity and faster processing, reducing computational overhead. However, the very nature of these files can bring forth challenges, such as embedded links, unstructured layouts, tables, and other elements requiring intricate data wrangling. Given the often lengthy nature of some documents, we break them down into more manageable sections. Within this step, we also generate embeddings, and numerical representations of words, enabling us to understand word similarities. All of this refined data finds its home in Chroma DB, our chosen storage solution.
User Interaction
Once our foundational knowledge base is established, users can present queries in natural, everyday language. The system embarks on a semantic search to pinpoint potential answers nestled within the knowledge base, and then the LLM crafts the final response. Central to this operation is the flan-t5-base model, revered for its proficiency in grasping English and generating appropriate responses.
It's noteworthy to mention that while our chatbot is rooted in LangChain and LLMs, it's seamlessly woven into Slack. This integration ensures users receive timely and precise answers directly within their familiar Slack environment, enhancing the user experience.
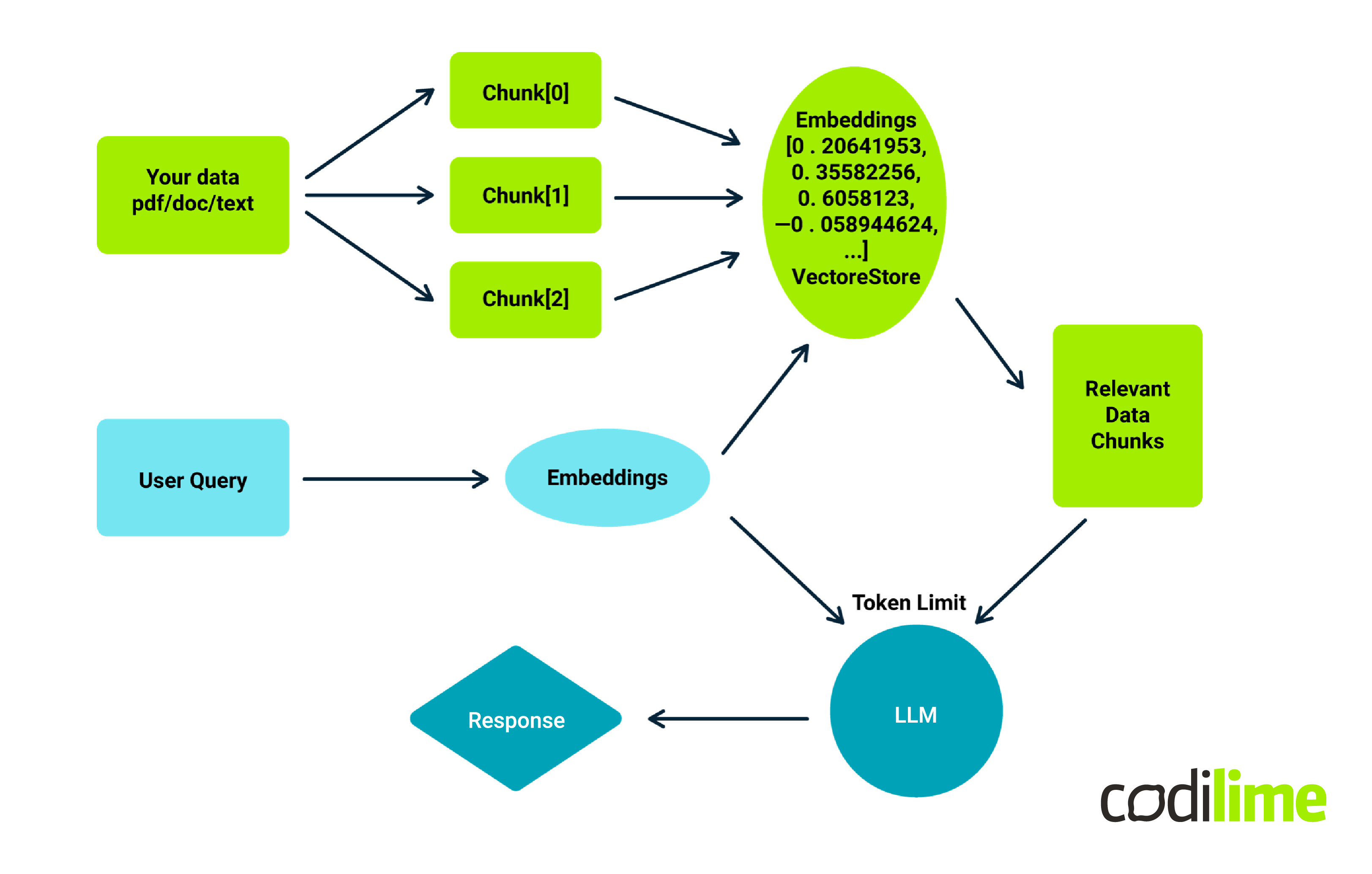
To create an interactive chatbot using the LangChain platform, it's crucial to first load the data in a format the system comprehends. While LangChain provides tools to accommodate diverse sources like PDFs, YouTube, and more, our focus here is on text files scraped from a Confluence webpage. These loaders simplify the task, transforming data into standardized document objects furnished with content and metadata.
However, developing this solution was not without its hurdles. Within Confluence, we discovered that the language of the content varied — some articles were in Polish while others were in English. Furthermore, some of these articles were stored as PNG images (i.e. screenshots of training decks) adding an extra layer of complexity. In order to retrieve the information from these images, we implemented OCR (optical character recognition) techniques as one of the steps in the data processing pipeline. Given that open-source LLMs generally exhibit superior performance in English, our approach was to prioritize English articles.
For the content available only in Polish, we undertook the task of translating them, ensuring accuracy and consistency. This strategy not only helped us maintain the efficiency and reliability of our chatbot but also showcased the importance of content standardization and accessibility in the development process. By addressing these challenges, we were able to harness the full potential of LangChain, prepping our data effectively for interactive queries.
from langchain.document_loaders import TextLoader
loader = TextLoader("content_test.txt")
pages = loader.load() #list of docs
type(pages[0])
langchain.schema.document.Document
len(pages)
1
page = pages[0]
page.page_content[:500]
'Page Title: Recognition Program - CodiStars Content: The CodiStars awards program are awards from you for you - for people who stand out in the company in a special way. Thanks to it, you can appreciate people who actively represent the activities and thus deserve an award. Your voice has power, so we encourage you to get involved. Remember that the CodiStars program is for employees and associates only, therefore you cannot award titles to people who are no longer working at CodiLime. The award'
page.metadata
{'source': 'content_test.txt'}
The next step is the splitting process. It seems simple but has nuances that impact later stages. For instance, poor splitting may separate related content, making information retrieval challenging. Document splitting occurs after data loading and before it enters the vector store. The core mechanism involves defining chunk size and overlap. Chunk size refers to the amount of text in each divided section, while chunk overlap ensures segments share common data to maintain continuity and context. Text splitters in LangChain allow splitting based on characters or tokens while ensuring semantic relevance.


Vector Store & Embeddings
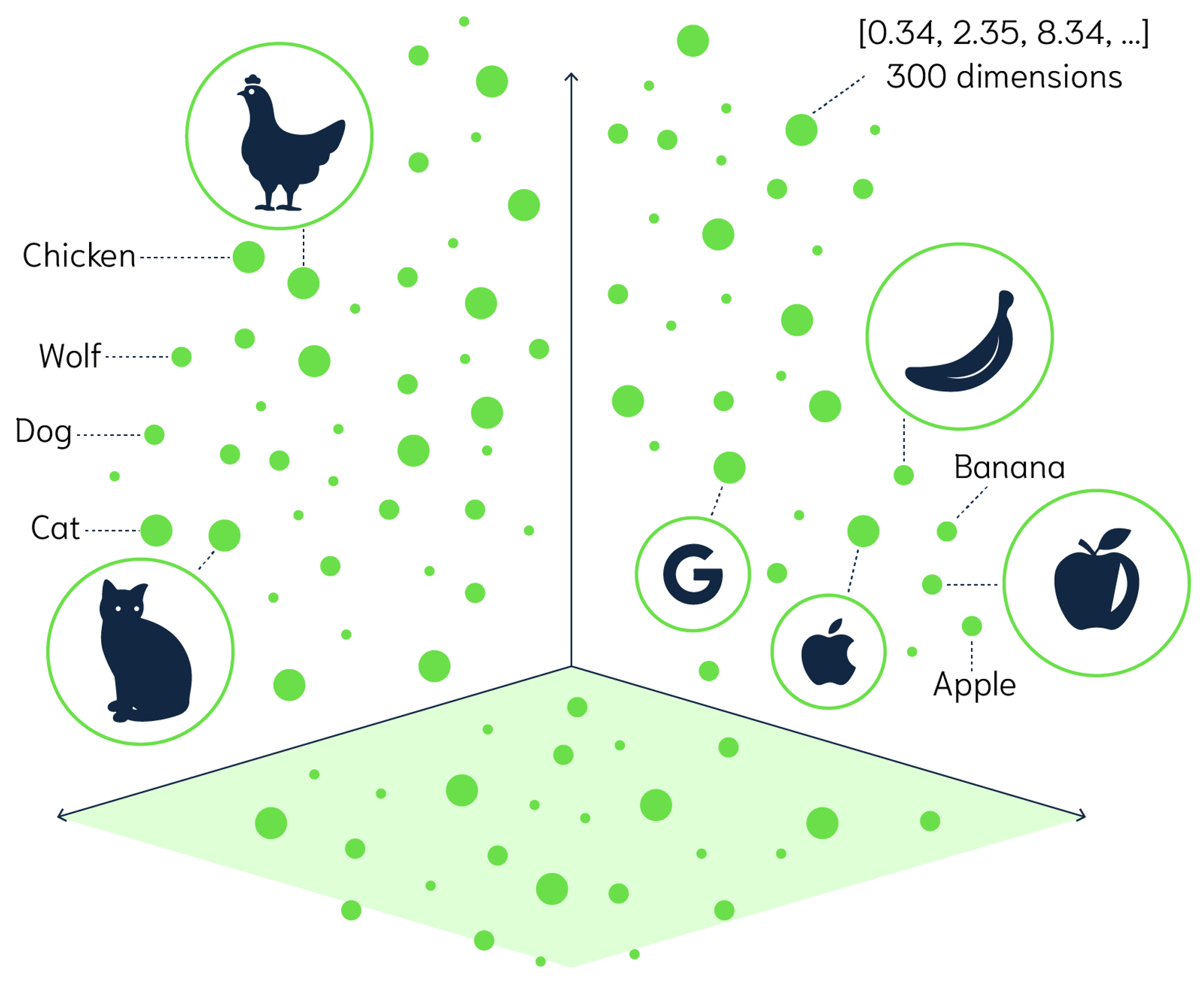
In the realm of private chatbot solutions, the foundation of efficient information retrieval lies in how data is processed and stored. Once a document is broken down into semantically meaningful chunks, it's vital to index these chunks so they can be promptly accessed when needed. This is where vector stores and embeddings come into play. Embeddings transform pieces of text into numerical representations, creating vectors. When texts share similar content, their vectors are closely aligned in this numerical space, allowing for comparisons.
For instance, text about pets would have vectors that are more closely related than text comparing pets and cars. After transforming text chunks into these vectors, they're stored in a vector store—a specialized database designed to quickly fetch similar vectors when queried. One such vector store is Chroma, known for its lightweight, in-memory capabilities, making it an attractive choice for swift information retrieval. Think of it like this: when a question arises, the chatbot transforms it into a vector, compares it with those in the vector store, retrieves the most relevant chunks, and then uses them to generate a coherent answer.
Notably, while embeddings offer promising results, they're not without challenges, such as potential duplications or imprecision in very specific queries. However, understanding these intricacies is crucial in refining and perfecting private chatbot mechanisms.
Question Answering

We are now ready to load our model. For this solution, we have selected the flan-t5-base model from Google. One of its significant strengths is its adeptness at understanding and processing English. Its relatively compact size is advantageous, especially when operating without GPU support. However, choosing the right infrastructure wasn't a straightforward task. Balancing CPU and GPU utilization posed challenges; while GPUs are incredibly powerful and offer accelerated performance, they can also be cost-prohibitive.
Relying solely on CPUs, on the other hand, could affect real-time response times, especially during peak usage. After a series of trials and evaluations, we landed on an optimal configuration that caters to our needs without compromising on performance or cost. It is worth noting that while setting up the solution infrastructure, especially in the cloud environment, it might be fruitful to use dynamic resources that would scale down when the system is idle (i.e. during the night hours, in our case).
The model's parameters, as depicted in the image below, have the temperature set to 0, ensuring consistent answers, while the "max_length" determines the maximum number of tokens in a response. LangChain offers support for the "PromptTemplate", allowing us to instruct our model to rely solely on the provided context for answers, rather than its internal knowledge.
On a side note, we recognize the challenges many face when hosting LLMs locally, given our own experiences. To help others navigate this complex terrain, we are preparing comprehensive material about hosting LLMs locally. This guide will soon be available on our YouTube channel, so stay tuned for insights, best practices, and hands-on demonstrations.
After configuring all the parameters, we can begin constructing the chain, where we incorporate our LLM and knowledge base. We also use the "chain_type" parameter, which is set to "stuff". The "stuff documents" chain is the most direct among the document chains. It compiles a list of documents, integrates them into a prompt, and then submits that prompt to an LLM. With our chatbot's mechanism in place, we are ready to pose questions.
from langchain import HuggingFacePipeline
llm = HuggingFacePipeline.from_model_id(
model_id="google/flan-t5-base",
task="text2text-generation\",
model_kwargs={"temperature": 0, "max_length": 600},
callbacks=[CustomStdOutCallbackHandler()],
)
from langchain import PromptTemplate
template = """
Use provided context, otherwise do not make the answer up.
{context}
Question: {question}
Answer:"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
chain_type_kwargs = {"prompt": prompt}
qa = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=vectordb.as_retriever(),
return_source_documents=True, chain_type_kwargs, callbacks=[CustomStdOutCallbackHandler()])
query = input("\nEnter a query: ")
print(llm.generate(prompts=[query]))
res = qa(query)
answer, docs = res['result'], res['source_documents']
print("\n\n> Question:")
print(query)
print("\n> Answer:")
print(answer)
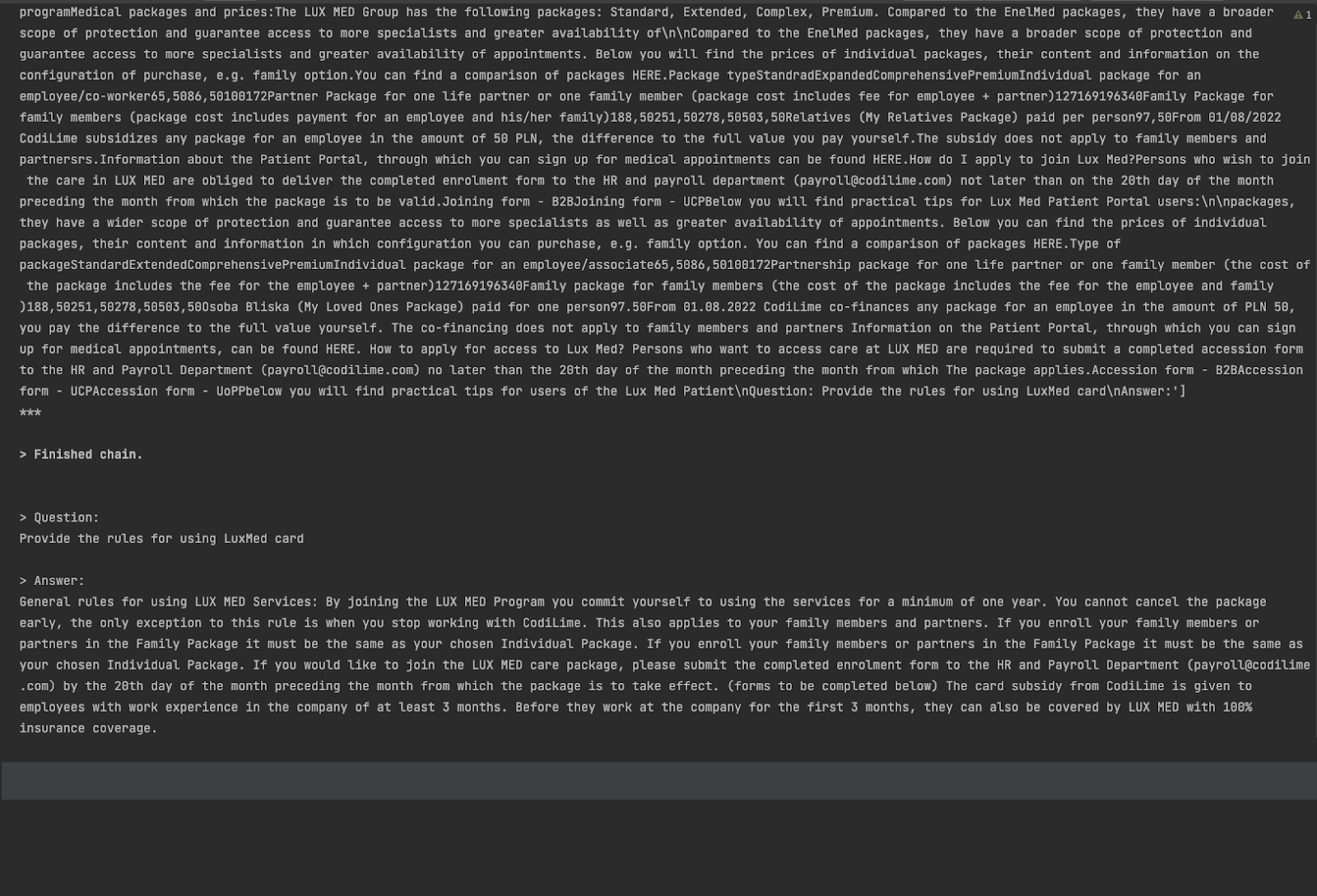
In the example below, we see a question posed: “What is the CodiStars recognition program?”. Let's delve into the process step-by-step. We provide our LLM context by sending a prompt, combining our prompt template and information retrieved from our vector store. Based on this information, we can obtain a basic understanding of the CodiStars program.
The entire solution has been integrated with Slack, allowing us to pose questions. A few examples are presented below:
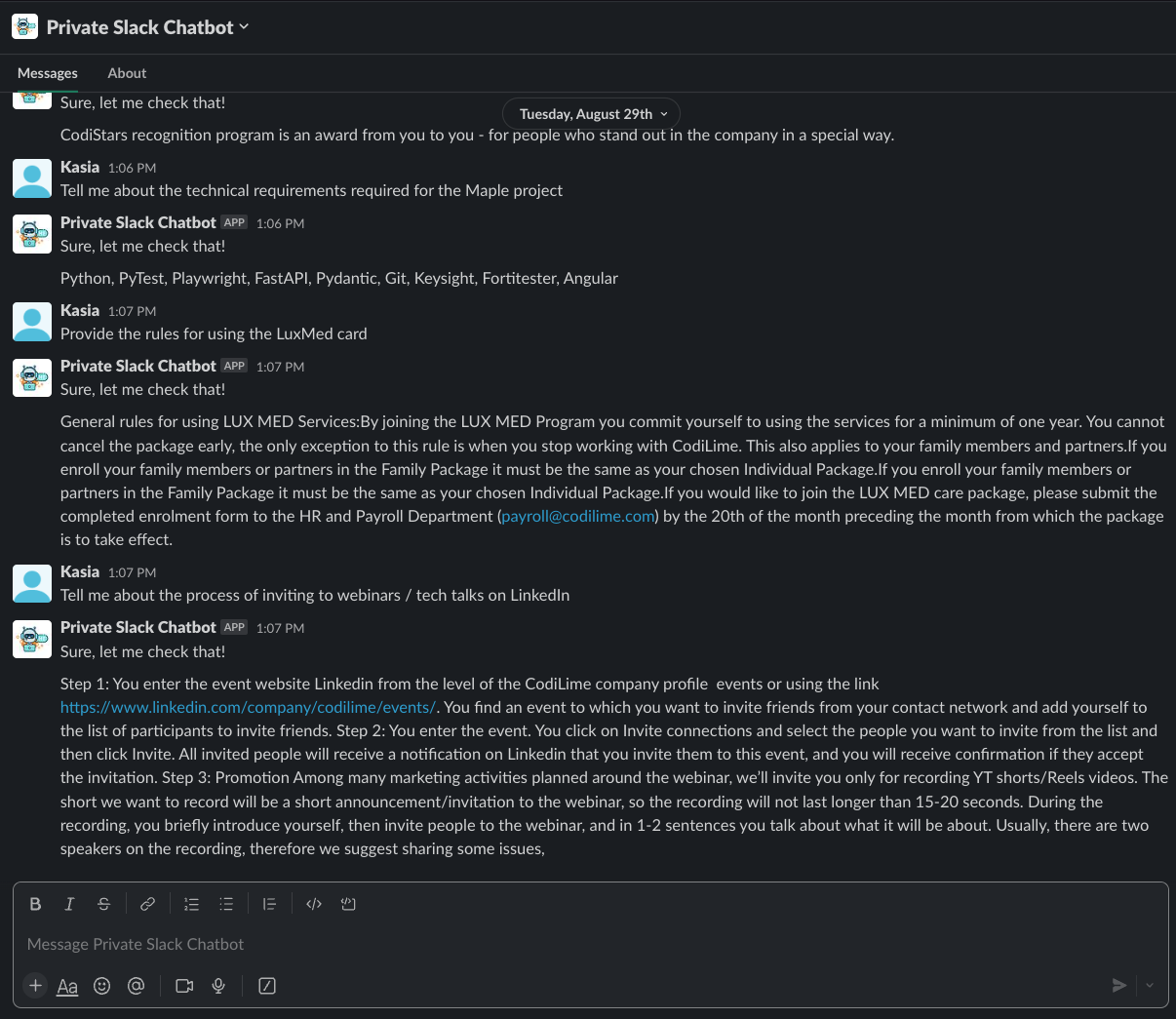


Conclusion
Merging company tools with advanced language tech opens up a plethora of exciting possibilities. Our Private Slack ChatBot is just one manifestation of what can be achieved. Beyond this, we have also embarked on commercial implementations, facilitating the creation of chatbots rooted in various corporate systems—from CRM and sales platforms to monitoring the real-time status of network devices within a corporation. As we gaze into the future, there's much more on the horizon, promising even better tools for businesses everywhere. However, as we increasingly embed this tech into our operations, the emphasis on data security remains paramount.
That's why we gravitate towards private models. Our aim is clear: harness the peak potentials of AI while ensuring our data remains uncompromised. Balancing innovation with responsibility is our guiding principle.


