


Databases are tools used daily by companies of all kinds. They make storing and transforming large amounts of data possible, and they are necessary for any data-driven business. But they had to come a long way before they became the databases we know today. Let’s take a look at the history of databases and learn how and why SQL and NoSQL have come to life.
History of relational and non-relational databases
The origins of relational databases
Since we, as humans, started collecting data, we also needed a way to store it. So naturally, the concept of a database came before computers. In the computer world, databases came into existence in the early 60s, when in 1962, the Oxford Dictionary first recognized the term “database” as a software system that stores and retrieves data. But early databases were completely different from the solutions we know today.
Modern databases emerged in the 1970s at IBM when computer scientist Edgar F. Codd presented the relational model theory in his paper titled, “A Relational Model of Data for Large Shared Banks”. In that paper, Edgar presented a new way to store data. Codd’s idea was to organize data in tables, each table storing information about different entities.
Each table would consist of a fixed number of columns describing the entity's attributes, including one or more unique attributes used to clearly identify a record named as primary key. Each table could be crosslinked to define the relationships between them. Relationships were described by using a set of instructions based on the mathematical system of relational calculus.
The origins of Structured Query Language
Querying databases based on Codd’s model was a simple task. The value of identifying attributes shows us all the information about that entity. Knowing which tables it is related to, we also know all the information about the entities related to our known entity.
The language used to work with relational databases was invented in the early 70s, when fellow IBM scientists Donald D. Chamberlin and Raymond F. Boyce learned about Codd’s theory. They developed a language named Structured English Query Language (SEQUEL). SEQUEL was designed to work with IBM’s first implementation of Codd’s model. Later in the 70s, SEQUEL’s vowels were dropped, resulting in the familiar-sounding SQL - structured query language.
In the late 70s, Oracle, then named Relational Software, developed its own SQL-based relational database management system (RDBMS). It was the first-ever commercially available database system based on Codd’s principles. Later in the 80s, ANSI and ISO began their efforts to standardize the SQL language, and SQL databases were ready to take over the world.
Relational model: What is the ACID principle?
ACID stands for atomicity, consistency, isolation, and durability. The term ACID was coined in the 1980s after Jim Gray's research in the field. It is a set of database properties that guarantee data validity despite possible errors, such as disk failure, power outages, etc.
A sequence of database operations that follow the ACID rules is called a transaction.
Let’s take a look at each letter of this acronym:
- Atomicity
This means that transactions in the database can only succeed or fail. This can be thought of as an all-or-nothing scenario: when one element fails, the whole transaction fails, and the database is restored to its state before the transaction began.
- Consistency
This refers to the characteristic that the data can only be modified with respect to rules and constraints defined within the database. Consistency prevents database corruption by an illegal transaction but does not guarantee transaction correctness.
- Isolation
This ensures that concurrent transactions leave the database in the same state they would have had if the transactions were executed sequentially. Isolation tries to ensure that there is only one transaction trying to access the resources at any one time.
- Durability
This factor guarantees that once the transaction is committed, it will stay committed no matter what happens, even in the case of a system crash.
The benefits of using an ACID-compliant database include data integrity and reliability. These rules ensure that your database will stay in a consistent state when an operation fails. But ACID transactions also have shortcomings. Compared to their non-ACID competitors, ACID-compliant databases are slower when it comes to read and write operations. This is due to their locking mechanisms.
Let's picture this in a quick scenario. An accountant needs to know the revenue for the last 48 months. You have checked and all 48 months are stored in your DB. In a relational, ACID-based DB, you will have all 48 months or nothing. If your query is wrong, in a NoSql database you can ask the DB five times and every result can give you a different number of months.
It is a known fact that SQL databases do not scale well. Sometimes the volume of data or number of requests to the database grows to the point where our current instance is not enough. In that case, the solution would be to upgrade the server and hope that works for now.
Most SQL databases scale only vertically. There is also the option to create an instance on another server and a connection between them called a link. But processing transactions over networks is a cumbersome task and affects the performance of the whole system. This is due to the ACID principles of relational databases.
The CAP theorem states that we can only choose two of three available options. These options are consistency, availability, and partition tolerance.
Traditional databases choose C and A so the tradeoff is P - partition tolerance. Most NoSQL databases do not follow ACID rules, so they can trade either C or A in favor of P and scale horizontally by creating a new instance of the database.

But hey, do we always need all the data to be consistent?
When designing the architecture for our system, data consistency is not always a must-have. For example, when building a search engine for an e-commerce app, it is not necessary to always have the most recent data available to users.
Let’s have a look at a theoretical example:
When Alice searches for product X, she doesn’t need to see the most recent entry for that query. When the query does not match anything relevant, similar results could be returned. Let’s imagine that while Alice is searching for X, Bob adds a new product that would match her query. It would not show up for her, but when she comes back in a while to check if it is now available and searches for the same product, it would now show up for her.
This is another case of “it depends”. When data consistency isn’t a necessity, we can sacrifice it in favor of availability and partition tolerance. But in other cases data needs to be consistent. Then we have to design our system differently to fulfill this requirement.
Data increase and the need for something more
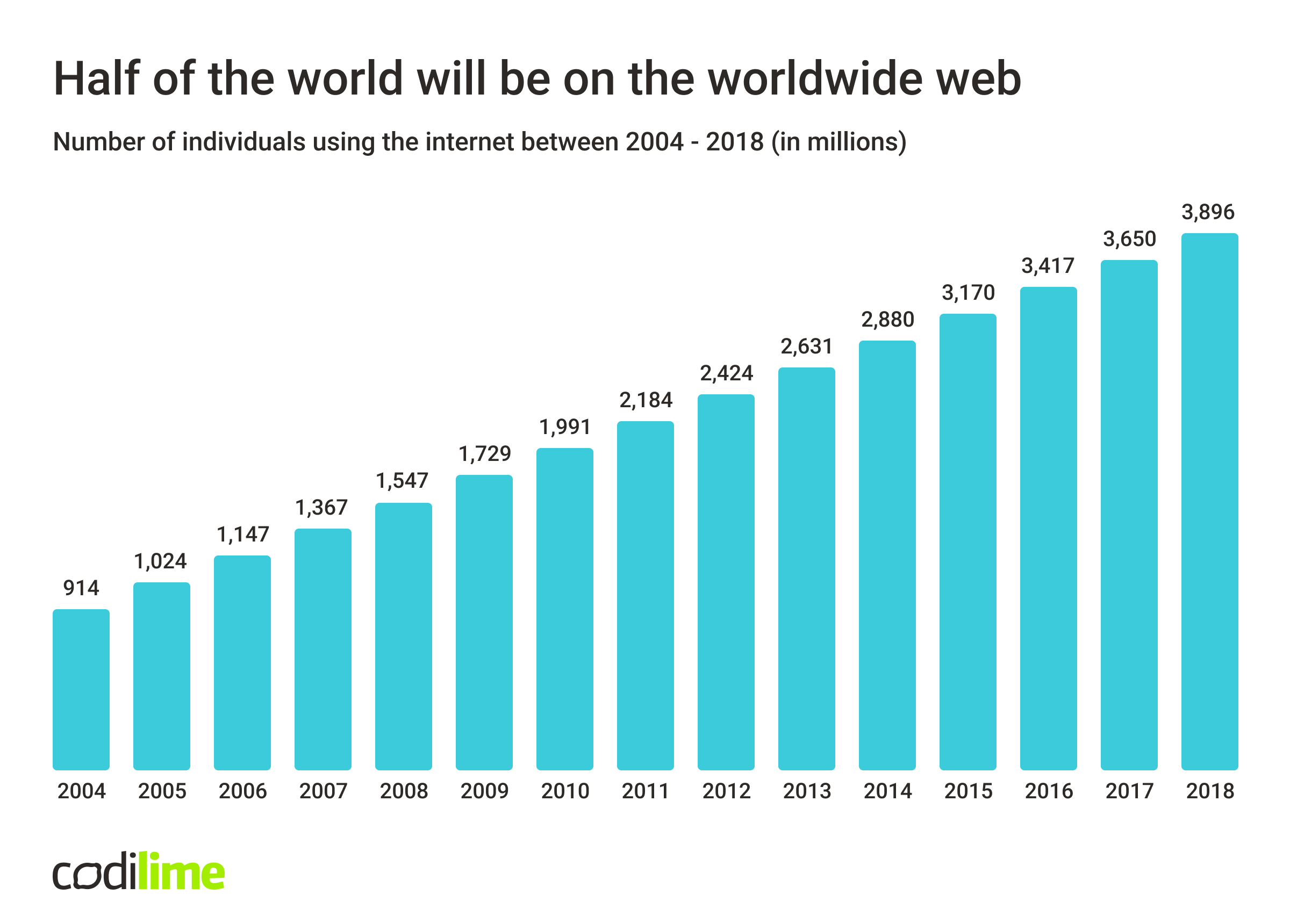
With ever-growing access to the internet and the shift towards digital services, the amount of created data started to grow exponentially. In the early 2000s, the internet had about 500 million users. In early 2010, it was about 2 billion users, and in early 2018, it was estimated that about 4 billion people use the internet. That’s around 50% of the global population ![]() .
.
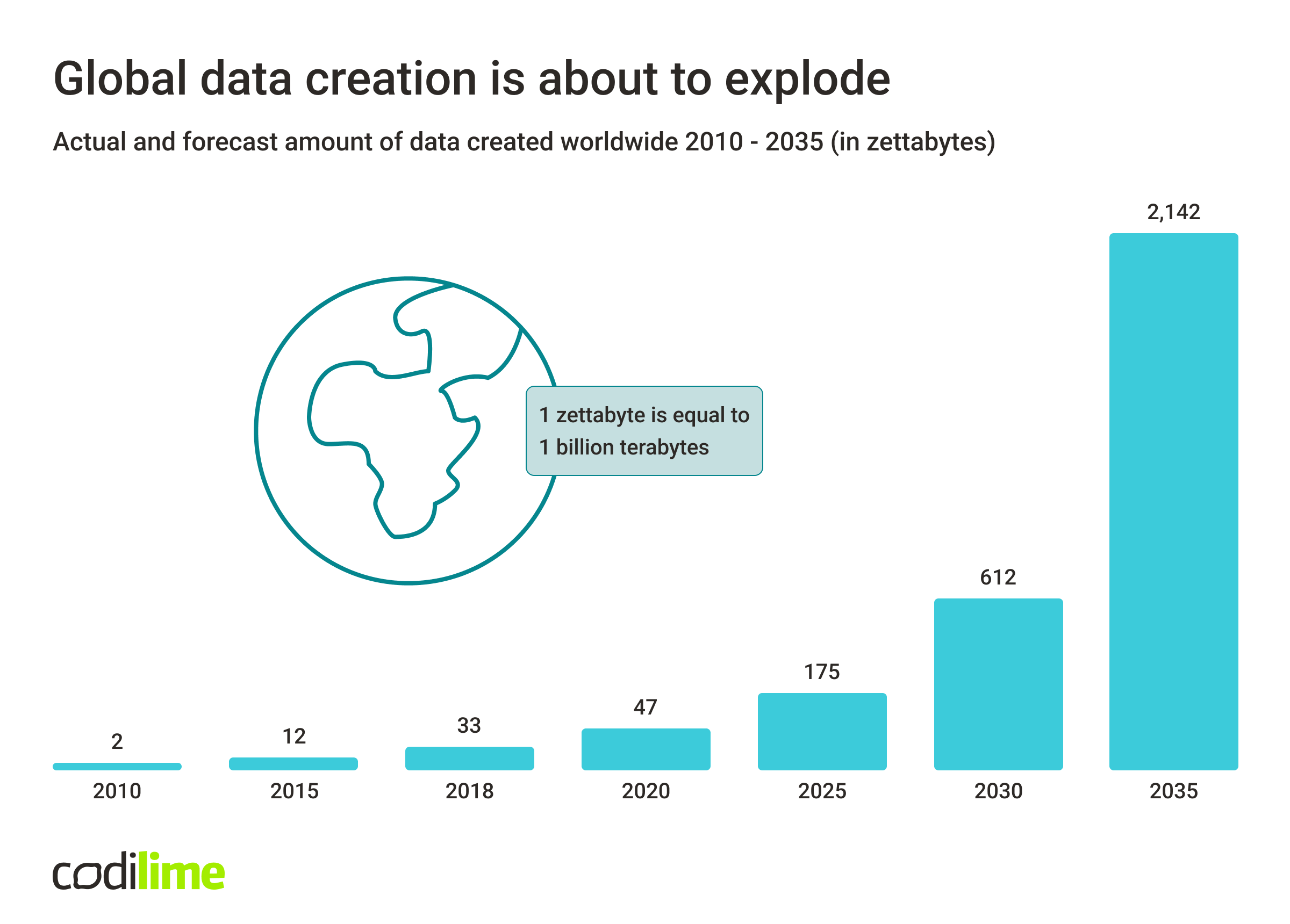
This has led to a massive increase in data produced and consumed. It is estimated that in 2025, the global data volume will exceed 175 zettabytes ![]() . To put that into perspective, a one terabyte HDD is about two centimeters tall. One zettabyte is one billion terabytes, so we would need 175 billion HDDs.That would be three and a half million kilometers, roughly nine and a half times the distance from the Earth to the Moon.
. To put that into perspective, a one terabyte HDD is about two centimeters tall. One zettabyte is one billion terabytes, so we would need 175 billion HDDs.That would be three and a half million kilometers, roughly nine and a half times the distance from the Earth to the Moon.
NoSQL approach
Most of this data is unstructured data. SQL databases were not designed to work with such loads and types of data. This has led to problems with performance, scalability, and data structuring.
One of the proposed solutions, called NoSQL (not only SQL), was to abandon the relational model and use document-like files often describing records as a whole, without breaking down the data into structured atomic parts. Another solution was to map the data into key-value pairs.
NoSQL databases also beat standard SQL databases in terms of scalability. Traditional DBMSs do not scale well horizontally; most of the time the only solution is to scale vertically. NoSQL databases are horizontally scalable. For example, in document-based databases, each document is a self-contained object. These objects can be stored on different servers without the need to set up a link between them.
SQL -> NoSQL (r)evolution
As previously described - it all starts with a particular use case or from an observation that “something is wrong”. It is important to set up the architecture depending on the use case one wants to achieve. When the system is under high load, we usually don’t want only one database instance to handle all the requests. When the system is read-heavy, we can set up a couple of read-only instances to optimize the load to each node and decrease the latency between each read.
When the system is write-heavy, it is more complex, but most of the time, we can trade off data consistency and use a distributed database to balance the load between nodes and then sync the data. It all depends on the context of the problem we are trying to solve.
How can we do it better?
The ideas described below were the historical answers for observed problems evolving from simple and straightforward to more and more complex.
Sharding
The idea of sharding is to partition the database horizontally. In other words, it is the practice of separating one table’s rows into multiple different tables, known as partitions. Each partition has the same schema and columns but also entirely different rows. Likewise, the data stored in each is unique and independent of the data held in other partitions.
The main appeal of sharding is that it can help to scale horizontally. Sharding can also make the application more reliable by providing more than one point of access to the database. In case of database failure, it is likely to affect only one shard, and the application might still run with some data missing. This is much better than a whole system crash in the case of monolithic database architecture.
Cloud storage—the beginning of modern data processing
Data storage media have come a long way since their introduction. Now, with widely available devices capable of storing terabytes of data, there are still some difficulties in creating data centers.
The first issue is that HDDs and SDDs scale poorly. The only option to increase the storage is to buy more disks and install them on the server. This is a significant inconvenience since disks take up a lot of room and are relatively expensive. At some point, it is unprofitable to buy more storage.
To resolve this problem, companies started to offer a service of renting disk space to customers; thus, the cloud was born. In 2006, Amazon launched its cloud storage service S3 as a part of its cloud-based portfolio. S3 allowed clients to store loads of data without the worry of running out of space or failures and downtimes. S3 quickly gained recognition in the industry and started providing storage for many virtual disk space services, such as Dropbox.
Bigtable
With increasing speeds and internet bandwidths, more data was being created and consumed, and with cheap storage from service providers, the idea to scale horizontally became viable. For such solutions, NoSQL databases come in handy. One of the pioneers of this process was Google which started to provide storage services when Google Drive was introduced in 2012, utilizing their custom database called Bigtable. Bigtable is a wide-column, NoSQL database that works under high analytical and operational workloads. It is available to use as a part of Google’s Cloud Platform portfolio.
Dynamo model
The Dynamo model is a set of techniques that can create highly-available storage based on the key-value storage system. It was developed at Amazon to help solve scalability issues they had in 2004. Now a service based on these principles is available as a part of the Amazon Web Services portfolio.
The principles in the short term are:
- The system should be able to scale horizontally one storage node with minimal impact on users and the system itself.
- Every node in the Dynamo model should have the same responsibilities. There should not be any nodes that serve special roles or take extra responsibilities.
- Nodes should be decentralized and favor peer-to-peer techniques over centralized control.
- Work distribution must be proportional to the capabilities of the individual servers. This is essential in adding new nodes with higher capacity without having to upgrade all hosts at once. This relies on the heterogeneity of the system it runs on.
Relational yet cloud-based
With the expansion of cloud services, the plain old SQL databases that used to be set up in local server rooms are not yet forgotten. The very same but cloud-deployed ACID-based databases become widely used data storage and warehouse engines.
AWS Redshift or GCP BigQuery can compute a very high amount of relational data and deliver it to users in no time. PostgreSQL is one of the most popular SQL databases. It offers a wide range of indexes, and very good JSON support, it uses a very clear SQL dialect and is free.
Another great example of SQL databases is Snowflake. This is used as storage space for your existing cloud storage. It is a columnar storage DB, so it is very efficient when it comes to working with big data sets. It also offers flexibility for users to allocate computing power from the code level.
Columnar storage
One of the ways of improving relational databases is so-called “columnar storage”. This way of storing data means that on pages - where the database stores data in rows - we store columns instead. Why all the effort? In most cases, the user is asking only for a few columns, almost never for an entire row. Columnar DB processes data only from the columns specified in the “select” part of the query, as opposed to row-based storage which uses computing power to get all records from the page and then selects columns. Also, columnar DB can guarantee the order of records (sort key in Redshift) and in row-based DBs, the order of records is random.
Another benefit of columnar DBs is the lack of indexes. We have only two keys - the sort key which describes the order of the loading and the distribution key where we can set the way data will be stored and read. All this plus parallel nodes working together make columnar databases a very powerful engine for analytical databases, especially where huge amounts of data are stored.
So far so good?
You might think that the problem of growing amounts of data would be easily solved with such great models and tools. Unfortunately, we are not even close. There is a whole new universe of something called big data which can be characterized by the 6Vs volume, value, variety, velocity, variability, and veracity. This, of course, is a completely different subject so I will not cover it here, but it is good to know that SQL and NoSQL are only a part of the big and wonderful world of data processing.
Stay tuned for the next part where we will cover real-life database scenarios and the possible ways and tools to achieve the best performance and functionality outcomes.



