


Large language models are deep learning algorithms that have gained much popularity in recent years. They are the power behind popular chatbots - they can recognize, summarize, translate, and generate new content. Read this article to find out how these models work, what technologies they use, and how businesses can use them.
Large language model definition
Large language models (LLMs) are a type of artificial intelligence; algorithms trained on massive amounts of data using deep learning techniques. They can perform various natural language processing tasks, including summarizing, generating, and predicting new content. Large language models are trained on a data set and then apply various techniques to generate content based on this data.
Language models emerged around the same time as the first AI solutions. One of the first language models was ELIZA ![]() , which was presented in 1966 at the Massachusetts Institute of Technology. This program could only match a preprogrammed answer based on keywords identified in the user input. A large language model is an evolution of that. It is trained on vastly larger data sets, which increases its capabilities and makes it more accurate. The variables that the model is trained on are called parameters. There should be billions of parameters for a language model to be called large.
, which was presented in 1966 at the Massachusetts Institute of Technology. This program could only match a preprogrammed answer based on keywords identified in the user input. A large language model is an evolution of that. It is trained on vastly larger data sets, which increases its capabilities and makes it more accurate. The variables that the model is trained on are called parameters. There should be billions of parameters for a language model to be called large.
Large language models is a part of our data services.
What is the difference between a large language model and generative AI?
Large language models are a type of generative AI similar to ChatGPT or Midjourney. While these terms are closely related, generative AI can generate any type of content, including images or video, and large language models are targeted specifically at providing text output.
How do large language models work?
Large language models use transformer models, which are deep-learning architectures. They are a type of neural network that consists of layered nodes inspired by the neurons of human brains. Neural networks track relationships in sequential data (for example, words in a sentence) to learn context and meaning.
Transformers were first introduced by Google in 2017 ![]() in a paper titled “Attention is All You Need”. A network is created from multiple transformer blocks called layers. These layers work together to understand input and provide a sequence of data as an output. The number of layers is related to the complexity of the model.
in a paper titled “Attention is All You Need”. A network is created from multiple transformer blocks called layers. These layers work together to understand input and provide a sequence of data as an output. The number of layers is related to the complexity of the model.
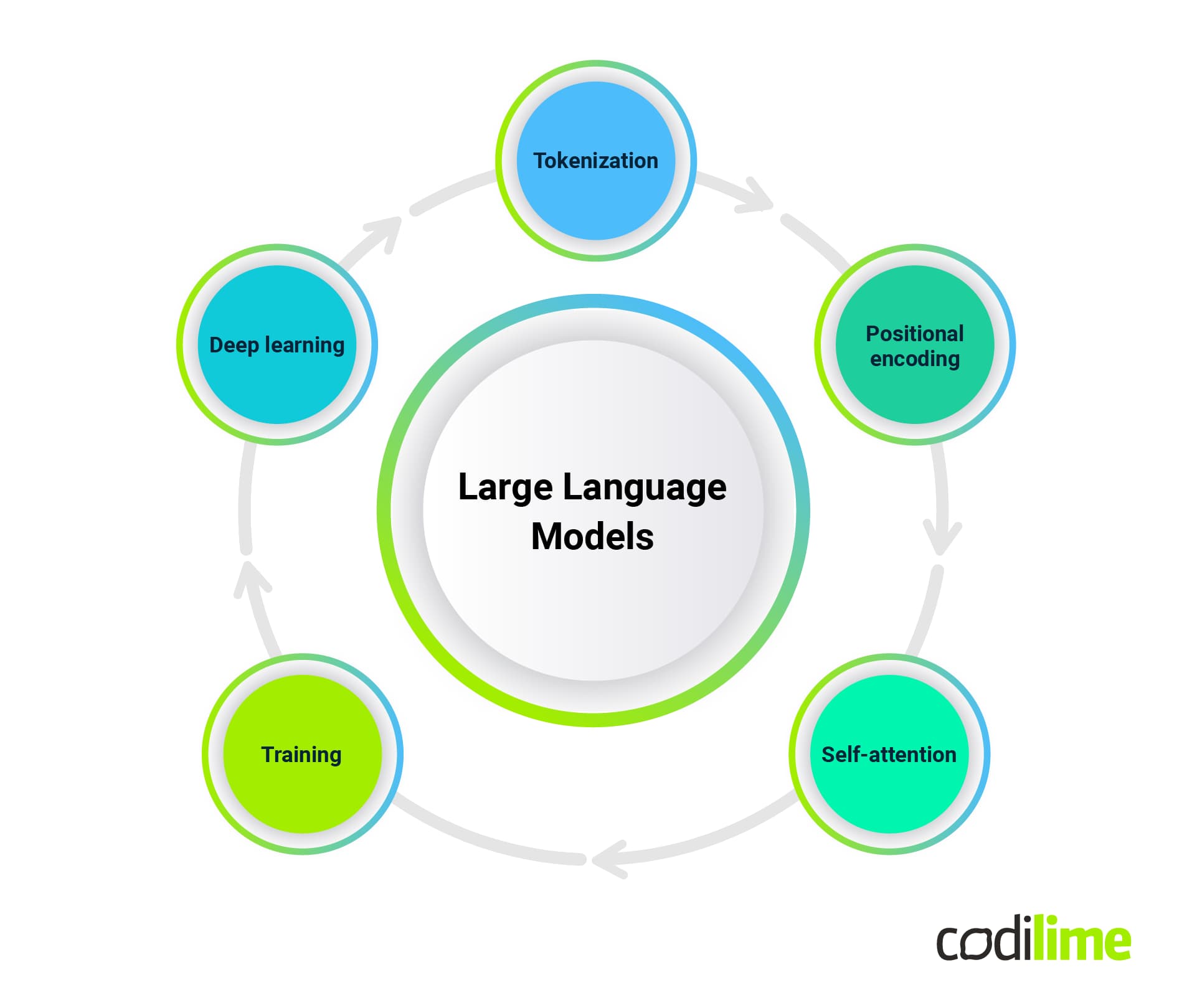
A transformer tokenizes input, which means splitting the input data into meaningful parts - in the case of language models, these are keywords - which can be called tokens. This allows the model to see patterns, such as grammatical structures.
An important innovation in transformer models was self-attention. This means models define the weight of each token, which signifies its importance in the context of the query. It allows them to pay attention only to the most important parts of the input. The capability to recognize the more important parts of the input is learned during training when the model analyzes large quantities of data.
Self-attention mechanisms allow LLMs to simultaneously process all elements in the input sequence, making it challenging to distinguish the elements' position or order. LLMs use embeddings - numerical representations of words or tokens in a continuous vector space that enable the model to understand and manipulate language by capturing semantic relationships between words. Positional encoding is introduced to provide the model with information about the position of each element in the input sequence. This is a set of values added to the embeddings of each element in the input sequence. These values carry information about the position of the element within the sequence. This addition allows the model to consider both the semantic content of the words and their positions in the sequence when making predictions. These encodings are learned along with the model's other parameters.
Key components of large language models
The key components of large language models are their layers. Each layer is responsible for a different task, and they work simultaneously to understand and generate accurate text.
- The feed-forward layer (FFN) is a complex structure of many fully connected layers. They work together to understand high-level abstractions and decode the user’s intention.
- The embedding layer turns tokens into vector representations that the model can process. It captures the semantic and syntactic meaning of the input, making it understandable for the large language model.
- The recurrent layer captures and models dependencies and relations between tokens in the sequence; in other words, it interprets the words in a sentence.
- The attention mechanism allows the model to focus only on the important parts of the query, as explained above.


Training of large language models
An important characteristic of large language models is how they are trained. These models use unsupervised learning, which means the model is trained on a dataset without explicit supervision or labeled data. During this phase, the model is exposed to a massive amount of text data. It learns to understand the statistical properties of human language, including syntax, semantics, and common patterns in text. This is achieved through self-supervised learning, where the model predicts missing words in a sentence or masks out words and learns to fill in the gaps.
This process results in the model acquiring a general language understanding called the foundation model or the zero-shot model. Such models can work well with many natural language processing tasks but can also be fine-tuned to fit more specific purposes. This part is usually supervised and includes training for text classification, language translation, and question-answering tasks.
Unsupervised learning allows models to gain a general understanding of the language, which is helpful in learning specific tasks during fine-tuning.
Types of large language models
Large language models can be divided into various types according to their purpose and training.
- A zero-shot model is a large, generalized model learning from a generic corpus of training data. It can provide fairly accurate results for general use cases without requiring additional training. A popular example is GTP-3.
- Fine-tuned or domain-specific models are created by adding extra training to a zero-shot model. These models are tailored for specific tasks, like OpenAI’s Codex, which is suited to programming.
- Conversational models are designed for human-like text generation in conversational contexts. They can understand and generate contextually relevant responses in a chat or dialogue setting, like DialoGPT or My AI on Snapchat.
- Language representation models like BERT utilize deep learning and transformers to excel in natural language processing.
- Multimodal models, like GPT-4, extend large language model capabilities beyond text by accommodating text and images in their processing.
The list of large language model types will likely grow in the future.
Large language models use cases
Large language models can be used for various tasks.
- Chatbots and conversational AI: large language models allow chatbots to interpret user queries and provide natural responses.
- Information retrieval: LLMs can retrieve and deliver information in a conversational style, like Bing AI, available on the search engine.
- Code generation: large language models understand patterns and can generate code, making them valuable in software development.
- Content summarization: large language models can generate summaries of long texts or documents.
- Classification and categorization: LLMs can classify and categorize content based on user-defined criteria.
- Translation: Multilingual large language models can translate text from one language to another.
- Sentiment analysis: large language models can analyze the sentiment in textual data, aiding businesses in understanding public opinions.
- Text generation: LLMs can produce text based on user prompts, crafting poems, creative pieces, or jokes.
Businesses can use LLMs to accelerate their marketing operations, for example, content writing, or to analyze public opinion on their brand via sentiment analysis. An organization can also benefit from a private chatbot that retrieves information from the intranet securely and delivers it to the user in a conversational manner.
Advantages of large language models
Using a large language model brings a lot of advantages. These tools can increase efficiency, aiding in content creation, translation, administrative work, and coding. They can also help learn new programming languages or explain inherited code. Specific tools can be used for data analytics, helping you become a data-driven organization. You can use sentiment analysis for monitoring public opinion, market research, and competition comparison. Large language models can also provide customer support via chatbots or help create training materials. You can also use an internal chatbot to help your employees access information about the company.
LLMs are already useful in healthcare and science: they can understand proteins, DNA, and RNA, making them great assistants in the development of new vaccines and medications. In the legal field, they can streamline the process by analyzing large files, and in finance, they can help to detect fraud. Overall, these tools, while not yet perfect, find many use cases in the modern business landscape and can be used to streamline important work.
Challenges of large language models
While large language models are an innovative and useful tool, they have their limitations. Most importantly, it is incredibly resource-intensive to create, train, and maintain large language models. Due to the vast amounts of data, the training process requires a great amount of computational power, including GPUs and TPUs. For example, CNBC estimates the cost of training a model similar to GTP-3 to be 4 million dollars ![]() . It can quickly exceed any budget, making the models impossible to scale and feed more data. This process also isn’t quick - training a model takes a lot of time, making it difficult to experiment with LLMs.
. It can quickly exceed any budget, making the models impossible to scale and feed more data. This process also isn’t quick - training a model takes a lot of time, making it difficult to experiment with LLMs.
The resource use and high energy consumption of LLMs raise an environmental concern. Especially when more such tools are available to a greater public, millions of queries are asked daily, and each of them requires resources. There is an option for governments to take action regarding this issue, but as of 2023, there are no regulations in place.
The next shortcoming of large language models is the quality of their responses. While this is an advanced technology, it is not immune to bias learned from the data set it was trained on. This might result in responses based on stereotypes present in languages rather than facts. The instances when LLMs provide false or imaginary information are called hallucinations.
It’s also important to remember that large language models generate text based on patterns in language; essentially, they just sort data and put it in a sequence, which, in this case, is words and sentences. They cannot reason, which sometimes results in plausible but incorrect answers. They also lack common sense and other human traits, such as a sense of humor, so they cannot understand the real world. Because of that, an experienced user can differentiate the human content from the generated.
The amount of data a large language model needs for training can also be an issue in some domains where insufficient information is available. There are other issues regarding the mechanisms of large language models themselves. They operate in a black box way, so the user only knows the input and the output, with no explanation of the model’s decision-making process.
Future advancements in large language models
Large language models are a powerful but fairly new technology. The launch of ChatGPT sparked a lot of speculation about ethics and the future of this technology. A heated debate is ongoing on the influence of these tools on the job market, raising concerns about workers being replaced by AI completely.
While the large language model is not to be feared quite yet, its future lies in the hands of the humans writing it. There are use cases where LLMs perform better than humans, but in 2023 developers, copywriters, administrative workers, and many more professions are still safe. There is a future whereLLMs will write themselves, and they are very likely to become smarter and perform better. However, there are no signs of them becoming sentient. Most likely, we will see the rise of more fine-tuned LLMs specialized in a specific domain instead of further development of foundation models. They will be able to handle more business operations, automating the mundane and repetitive tasks.
The bias and accuracy issue can be addressed by training models on bigger amounts of more filtered data. It’s likely that they might have to provide an explanation of the output, including sources of their information. Another important factor shaping the future of LLMs is reinforcement learning from human feedback (RLHF), which means using user feedback to generate better responses. There are also possibilities for optimizing the learning process, including using a smaller number of parameters and less time to achieve similar and better results.
The development of AI and LLMs is nowhere near slowing down. These models are shaping the future of technology, and using them in daily operations is becoming the norm for many industries.


