


There are other great approaches to improving reliability and scalability besides splitting big monolith applications into microservices. But we have found the microservices approach to be the most promising in our case. With a team of just three software engineers and a DevOps engineer we started working on a migration in parallel to developing new functionalities for the migrated application. Here is a story of the journey we started a few months ago.
Why did we even start
I have to admit, “monolith” might not be the most precise description of the solution we built, as it already consisted of not one but a few elements. The mix starts with a rather dull set of standard, open-source components: a database (PostgreSQL in our case), a message queuing system (RabbitMQ) and a HTTP proxy (nginx) that binds together the components which we actually developed and built.
And these are:
- a Flask-based REST application responsible for handling around 99% of our REST traffic, our “monolith”,
- a smaller REST application based on FastAPI, which serves just one endpoint. One could say it marked the initial step in our exploration of microservices (as it has been developed separately from the “monolith” and implemented as a separate service),
- a service managing worker applications (running tasks that take longer to process than one would want for HTTP requests),
- a job scheduler service, which starts tasks at a specified time (internal cron-like service).
In this publication ![]() , you can read more about monoliths.
, you can read more about monoliths.
We shipped the application as a set of RPM packages, with roughly one RPM per component. We utilize upstream RPMs for open-source components (e.g. PostgreSQL and RabbitMQ), and created custom RPMs for the internally developed elements. All these components make up the product which has been deployed by our customers either on-premises (for example, due to their security policy), in the cloud or as a mix of both (hybrid deployment). We have also delivered the product “as a service”. Our users have included banking and financial institutions, telecommunication companies, manufacturing enterprises, healthcare businesses and others.
The problems which occurred with this architecture started with scalability and resilience issues. First, it was rather “coarse-grained”: if someone wanted to increase the number of processes handling a particular service, they would have to proportionally increase these numbers for the other services at the same time.
Moreover, the services used a local file system to store and share the artefacts necessary for their operation. That situation made horizontal scaling impossible, only vertical scaling was applicable. To address this problem, we prepared a specific cluster solution.
It was clear to us that customers may come with different requirements based on the specifics of their workloads. For some (the majority), fault tolerance was extremely important. Increasingly, our solution was installed in a Kubernetes environment. Some customers may have built a solution requiring a large number of workers, while others depended on the peak processing performance of the REST service. So from an application point of view, it was a mix. The two prevailing requirements, which we faced pretty much always and everywhere, were flexibility and reliability. Flexibility enables being able to fit different needs, various scenarios. It is the foundation of a service which can adapt to various business verticals. Practically speaking, we wanted to build a solution that offers the possibility of scaling one of its services and not the other; to choose a particular database or message broker solution etc. The requirement for reliability is self-evident for business processing applications. Customers running banks, maritime logistics or production lines demand minimum downtime, a resilient solution, which will work even if one of the components fails.
So, a few months ago a decision was made and we started the analysis and preliminary work before breaking down our large REST service application (“the monolith”). This is a project developed over several years in Python, using Flask at its core. We use a few other Flask-related libraries for example to deal with user management, security, authentication etc. Our project has several tens of thousands lines of code (plus tests). So we were not faced with a trivial task. Fortunately the application has quite easily distinguishable groups of endpoints related to certain functionalities. It seemed that from this we should be able to extract a decent number of microservices.
How did we start
Our initial effort was focused on writing a Helm chart with which we were to install our application from now on in a Kubernetes environment. Helm is the de facto standard when it comes to installing slightly larger applications in a Kubernetes environment, so we didn't reinvent the wheel and just used best industry practices instead. At this stage, we planned to split our application into several containers. The division roughly corresponded to the earlier division into RPM packages. We prepared a Dockerfile for each, built images, at first just manually, and created Pod definitions in the cluster, which used those images. In addition, we defined several Kubernetes services and replaced nginx with an Ingress Controller definition. This created a framework with which we could easily install and update the components of our product.
To make it easier for us programmers to develop the application, we have described in a simple Makefile the few steps needed to run the whole cluster locally, on a programmer's laptop. So we have a step where we initialize a local Kubernetes environment using a Docker container (we use kind ![]() for this purpose). Another Makefile section is used to define how to generate the Kubernetes secret needed to download Docker images from AWS ECR. Finally, another one instals our Helm chart in the created cluster.
for this purpose). Another Makefile section is used to define how to generate the Kubernetes secret needed to download Docker images from AWS ECR. Finally, another one instals our Helm chart in the created cluster.
The first approach
We planned to carve out just three microservices from the monolith to begin with. We choose groups of pretty much self-contained pieces of our application, with well-defined functionalities not especially dependent on other parts of the system.
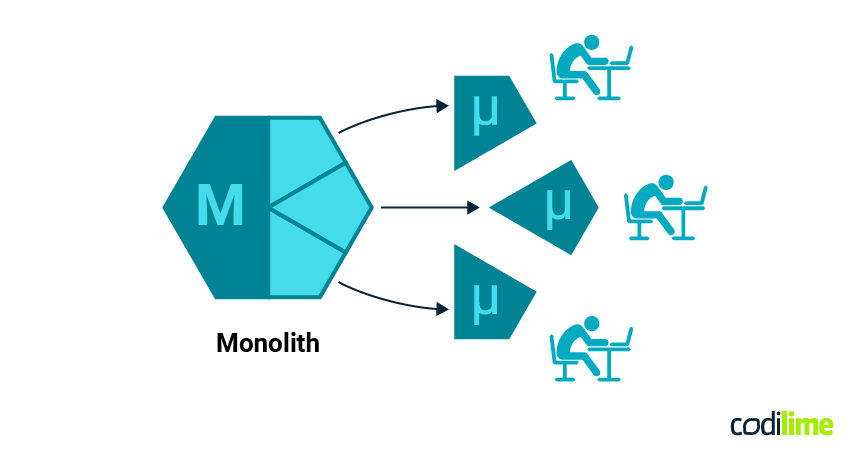
We could start working on each one of the new microservices independently, even in parallel. That was a huge benefit in the beginning, but turned out to also be a challenge later on.
>> In these articles, you can read more about how microservices differ from a monolith, and what the benefits of microservices are.
The process and the steps of each migration looked somewhat similar. Each started off by creating an empty repository with just a scaffolding consisting of a Dockerfile and an entrypoint script. We chose python:3.11-slim for a base image (which was the latest and greatest at that time), and a Gunicorn WSGI HTTP Server, which we already had experience of working with in the monolith.
Then we copied the part of our monolith responsible for handling requests for a specific group of HTTP/REST endpoints and all the utility code. It turned out there were a lot of the latter, but we didn’t care much about trimming it down at that moment. We decided to use the same database as the monolith did, so at that point in time we were not bothered by database migration scripts and such. We just copied one more thing (the database connection settings) from the monolith. After these steps were complete, we were able to build a Docker container image handling a request for a specific group of HTTP endpoints.
The time came to take care of our Helm chart. We added, again often using copy/paste functions, the configuration of a new Kubernetes deployment for the new service. We modified the configuration of the nginx deployment, which we use as the reverse proxy and main entry point for all of the (micro)services, for the changed endpoints so that they redirected to the new service. And, most importantly, we added a switch allowing us to choose the new configuration or stay with the old one. This was going to be useful for quite some time.
Anyway, after completing these steps, we had a separate service able to handle a group of the requests, and we were able to use it instead of the corresponding piece of the monolith application. It still used the same underlying database as the monolith. For that reason we did not (yet) have to bother about modifying the DB schema.
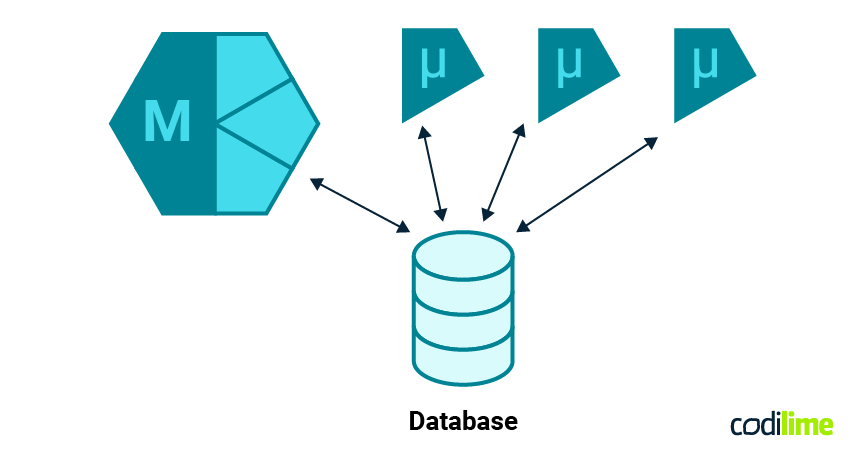
Database changes
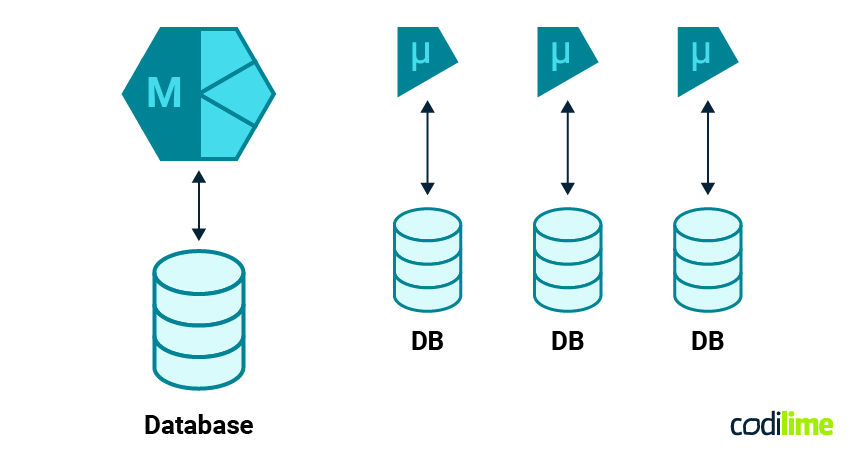
Following the initial effort, which was really a kind of “lift off”, we knew we had to follow-up with the DB separation. The goal was to have a completely separate database, potentially even using a completely separate database engine instance. To achieve this, we had to change the way we built relations between our database tables.
Previous to the split, we had been using the mechanisms built into every relational database (relationships defined using foreign keys) and the methods provided by SQLAlchemy. Both made working with related objects easy and safe. However, as we had moved some of the tables into a separate database, the previous mode of operation was no longer possible.
The process was two-sided: not only from the monolith we now needed to be able to query an entity identified by, for example, id=entity1 rather than _storage_id=56. Also in the microservice code we needed to be able to "translate" other identifiers we use into information that allows us to assess whether, in the context of a specific request, a particular operation on the selected entity should be allowed or forbidden.
This way we were able to either just use the same database engine as the monolith, just a separate database, or a completely different database engine. We could have a large, potentially clustered database for the monolith and a completely separate one with lower hardware requirements that could run on less powerful, and therefore potentially cheaper, machines.
Switching web application framework
When we started building our monolith application a “few years” ago, we chose Flask ![]() for our application framework. Rewriting parts of the monolith as microservices presented us with the opportunity to use something else. As we had some good experience with FastAPI
for our application framework. Rewriting parts of the monolith as microservices presented us with the opportunity to use something else. As we had some good experience with FastAPI ![]() , we decided to rewrite our solution based on that framework.
, we decided to rewrite our solution based on that framework.
We started by preparing Pydantic ![]() models for requests and responses. Then we rewrote, one by one, each of the handler methods (each microservice has somewhere around five to ten handler methods). During the lifespan of our solution (a good “few years”), we had developed quite a number of features tangential to listing all of the entities. We had some security mechanisms built into our application, for that we used flask-security. We had implemented multi-tenancy, results pagination, generic filtering, etc. All that had to be ported as well.
models for requests and responses. Then we rewrote, one by one, each of the handler methods (each microservice has somewhere around five to ten handler methods). During the lifespan of our solution (a good “few years”), we had developed quite a number of features tangential to listing all of the entities. We had some security mechanisms built into our application, for that we used flask-security. We had implemented multi-tenancy, results pagination, generic filtering, etc. All that had to be ported as well.
At that time we noticed that SQLAlchemy 1.4, which we used in monolith, had been marked as a legacy version. That meant we had better rewrite the microservices based on a newer version of the library. And not only that. However, this was not a simple update of the version number in the requirements.txt file, but an attempt to meet the suggestions (requirements?) for version 2.0 of SQLAlchemy (the so-called 2.0-style ![]() ).
).
We wondered whether functions common to all microservices (such as those mentioned above) should be separated into a separate repository. The advantages of such a solution are all the advantages of keeping common code in one place. Possible modifications, fixes, extensions to functionality, etc. should then be made in a single repository. Developers can then focus on the implementation of the solution, rather than tools and support functions not directly related to it. But such an approach also involves the difficulty of adapting the shared code to certain "special cases", which always, sooner or later, appear in every project... It also sometimes increases the time to deliver the solution. Those that require the programmer to also make changes to the shared code are prolonged for several reasons. Firstly, the additional process of evaluating and accepting the solution (code review). Then the time required to run tests (CI). And in the last stage, the building and archiving of the artefacts (shared library). Having considered all the advantages and disadvantages of the solution, we finally decided to go down this path. Not uncritically, however, and perhaps our approach will change at some point. So we have a “common” library, imported by all microservices, which provides a little bit of “scaffolding”, examples of use and some kind of “best programming practices”.
Tests add to development speed
During the lifespan of our monolith application, we have developed a number of test suites for the backend. These include unit tests for individual components, integration tests which test interoperability between the components, and system tests, which test the end-to-end processes of orchestrating life cycles of real entities, e.g. AWS EC2 instances. The switch to a microservices architecture running on Kubernetes necessitated a change in the way some tests are run. While unit tests by their very nature are insensitive to such changes, integration tests have already required us to change the way we run them. Prior to the change, we ran all tasks within the integration tests on a Docker all-in-one container. This container contained all the components required to run the application: the database, the message queuing system, our three backend services and nginx, which tied them together (→ monolithic architecture). As for the system tests, for reasons unrelated to the change in architecture we abandoned them.
It was having a reasonably complete set of tests that allowed us to work quickly and fairly confidently. We are thus able to verify that the elements carved out from the monolith, which use a separate database, rewritten using a different framework, are functionally no different from the original implementation. This is a fantastic “safety net” that adds to our confidence and therefore ultimately results in the speed of the changes we are able to make.
Future
We are looking to carve out more parts of our solution to microservices. With this experience, plus the tooling and the “common” library, we feel confident about repeating the scenario described here. First we would implement selected endpoints with the FastAPI framework, using a “common” library. The next step would be setting up a dedicated database, separate from the one the monolith uses. And finally we would upgrade our Helm chart to have the possibility of using the new solution (or stick to the old monolith-based version). These three steps might of course be executed in parallel, speeding up the process.
But since the new services do not rely in any part on the monolith code, it is also possible to implement them now in other programming languages. In fact, the sky's the limit: we can have multiple teams working simultaneously, using (possibly) different frameworks, languages, or databases. That is one of the advantages of microservices architecture.
Surprises
We didn't anticipate that rewriting parts of our solution to microservices, using a modern web framework would consume that much time. We approached the task optimistically, eager to leverage new technologies for improved efficiency (e.g. async/await). However, the process eventually evolved into a more complex venture. This happened for reasons which were beyond our control (e.g. the transition from Pydantic V1 to V2), but we also contributed to it ourselves. We decided to use FastAPI (so Pydantic models), and upgrade SQLAlchemy. That meant re-implementing entity models in SQLAlchemy 2.0 (declarative mapping). As the Pydantic and SQLAlchemy models were not compatible with each other, the definitions of these entities for Pydantic had to be prepared as well (slightly different models for incoming and outgoing data). That was already quite some work.
Moreover, the monolith, which had been built over several years using Flask, was “overgrown” with additional tools, helper functions, etc. Moving a piece of the monolith was not just a simple rewrite of a few functions, but it also involved recalling and understanding the additional functionality and recreating it using the new framework. All of this added up to a significant increase in the time we spent rewriting the microservices. On the flip side, perhaps forced by circumstances, we gained a lot: we got rid of many (almost) deprecated dependencies, and untangled a few toolboxes and helper functions that had accumulated over the years.
As a result, the application once again benefits from modern, up-to-date, maintained and secure dependencies. This will undoubtedly benefit both the developers (easier to understand code) and the application itself (we are removing a kind of technical debt).
Some changes “around” the product made us do things differently than we anticipated. A shift towards a Kubernetes-based deployment for example made our system tests rather obsolete and we had to let them go. It was with a heavy heart though, as we had put a substantial amount of effort into writing them and keeping them up to date. Luckily other test suites serve the same purpose and we were able to adapt and evolve our testing strategy accordingly.
The ability to easily switch between the new microservice and the legacy solution is also a pitfall of sorts. It did not “force us” to choose a new solution quickly and definitively, and sometimes we ended up with months of uncertainty. During this time, new functionalities had to be introduced into both independent codebases.
Conclusions
Migrating a monolith code base can be tempting, especially given that it is still a trendy concept, but I would recommend caution here. For an application such as ours (several tens of thousands lines of code), it is a time-consuming process and one that requires great care (after all, “rewriting” has been prone to errors for centuries). The operation is also not always justified by technical arguments. If part of the application's functionality is used to its limits and the rest is used much less, if flexibility and adaptability are important, then breaking it down into fragments is likely to be beneficial.
However, there are situations where it is worth thinking twice about whether this is the best way to evolve an application. This, though, is a topic for a separate article.


