


Everyone's Adding Capabilities. Almost Nobody's Adding Controls.
There is a pattern I keep seeing in how companies adopt agentic AI: they start with capabilities. They connect an LLM to internal tools. They build MCP servers. They give agents access to APIs, databases, and infrastructure. The demo works. Everyone is impressed.
Then someone asks: "Who is allowed to do what?"
And the room goes quiet.

This is not a theoretical concern. According to Gartner's 2025 predictions ![]() , 25% of enterprise breaches by 2028 will be traced back to AI agent abuse, from both external and malicious internal actors. In the same report, Gartner predicts that 40% of CIOs will demand "Guardian Agents" to autonomously track, oversee, or contain the results of AI agent actions.
, 25% of enterprise breaches by 2028 will be traced back to AI agent abuse, from both external and malicious internal actors. In the same report, Gartner predicts that 40% of CIOs will demand "Guardian Agents" to autonomously track, oversee, or contain the results of AI agent actions.
And it is not just Gartner raising the alarm. BigID's 2025 AI Risk & Readiness Report ![]() found that 47% of organizations have no AI-specific security controls in place, and only 6% have an advanced AI security strategy. The gap between adoption and governance is enormous.
found that 47% of organizations have no AI-specific security controls in place, and only 6% have an advanced AI security strategy. The gap between adoption and governance is enormous.
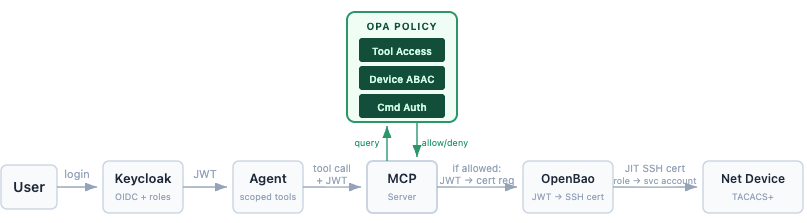
At CodiLime, we hit this problem head-on when building a system that connects AI agents to live network infrastructure via MCP. The protocol makes connectivity easy, and it does include some security guidance, such as token audience binding, scope minimization, and confused deputy mitigations. But MCP does not by itself solve enterprise-grade authorization, downstream identity propagation, or target-side enforcement. Those layers are your responsibility.
We needed a policy engine. We chose OPA. What followed was a first-hand lesson in what policy-as-code actually means for agentic systems.
What Is Open Policy Agent (OPA)
Open Policy Agent is a general-purpose policy engine, created in 2016 by Tim Hinrichs, Torin Sandall, and Teemu Koponen. It graduated from CNCF in February 2021 ![]() and was the first CNCF project focused entirely on authorization. At graduation, 91% of surveyed organizations were already using OPA from QA through production, with over half employing it for at least two different purposes.
and was the first CNCF project focused entirely on authorization. At graduation, 91% of surveyed organizations were already using OPA from QA through production, with over half employing it for at least two different purposes.
The core idea is simple: decouple policy decisions from policy enforcement. Instead of hardcoding authorization logic into every application, you write policies in a dedicated language (Rego) and query OPA whenever a decision needs to be made. OPA takes three inputs…
OPA in one line: Input (JSON) + Policy (Rego) + Data (JSON) = Decision (allow/deny)
That simply means who is asking, what they want to do, and what the current context is, which then returns a decision.
This architecture is what makes OPA fundamentally different from application-level authorization libraries. It is not tied to one framework, one language, or one use case. The same engine that validates Kubernetes admission requests can authorize API calls, enforce Terraform compliance, and, as we discovered, control what an AI agent is allowed to do on a network device.
As OPA co-founder Torin Sandall put it at graduation ![]() : "OPA today has become the de facto toolset for expressing authorization policy across the stack." Production adopters include Netflix, Goldman Sachs, Google Cloud, Pinterest (handling ~400K QPS
: "OPA today has become the de facto toolset for expressing authorization policy across the stack." Production adopters include Netflix, Goldman Sachs, Google Cloud, Pinterest (handling ~400K QPS ![]() for Kafka access control), Capital One, Intuit, and T-Mobile.
for Kafka access control), Capital One, Intuit, and T-Mobile.
Why Use Open Policy Agent for AI Agents?
When an AI agent calls a tool, someone needs to answer a set of questions in real time:
- Who is the human behind this agent?
- What tool is the agent trying to use?
- On which resource: which device, which dataset, which service?
- Is this allowed, given the user's role, the device's sensitivity, and the current context?
This is attribute-based access control (ABAC). And OPA was built for exactly this pattern.
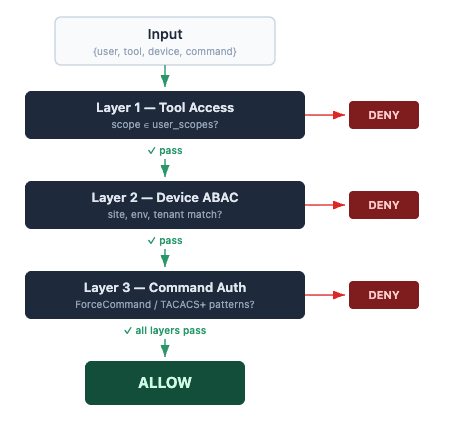
In our Secure AI Net Inspector platform, OPA sits as a centralized policy decision point that reasons across three authorization layers in a single query:
- Layer 1: Tool access — can this user invoke this MCP tool?
- Layer 2: Device access — can this user reach this specific device (based on site, environment, and tenant)?
- Layer 3: Command authorization — is this specific CLI command allowed for this role on this device type?
OPA Policy in Practice
Here is what this looks like in practice with a simplified excerpt from our authz.rego (helper rules omitted for brevity):
package authz
import rego.v1
# Layer 1 — Tool Access
default allow_tool := false
allow_tool if {
required := data.tool_scopes[input.tool]
required in user_scopes
}
# Layer 2 — Device Access ABAC
default allow_device := false
allow_device if {
not _maintenance_active
device_info := data.devices[input.device]
_site_allowed(device_info)
_env_allowed(device_info)
_tenant_allowed(device_info)
}
# Layer 3 — Command Authorization
default allow_command := false
allow_command if {
data.devices[input.device].enforcement == "forcecommand"
principal := ssh_principal
principal != "net-admin"
not _denied("forcecommand", principal, input.command)
_allowed("forcecommand", principal, input.command)
}
# Combined Decision — all layers must pass
default allow := false
allow if {
allow_tool
allow_device
allow_command
}
OPA evaluates this against a data file that maps 40+ MCP tools to scopes, 9 network devices to sites/environments/tenants, and command patterns per role per enforcement type (ForceCommand for FRR/VyOS, TACACS+ for SONiC). The policy includes batch evaluation, a single API call can check access to multiple devices at once, and return per-device denial reasons.
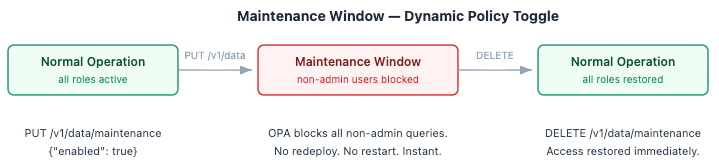
Maintenance Windows: Toggling Access Without Redeployment
One feature we found particularly valuable, and honestly did not expect to use so early, was maintenance windows. A single PUT /v1/data/maintenance {"enabled": true} to OPA's Data API instantly blocks all non-admin users from all devices, without redeploying anything. When the window ends, DELETE /v1/data/maintenance restores normal access. Try doing that with hardcoded decorators.
This is readable, testable (we have 60+ Rego unit tests covering every user/tool/device/command combination), version-controlled, and auditable. It is also fast since OPA is designed for low-latency authorization ![]() and fits comfortably within a typical millisecond-class decision budget for well-structured policies.
and fits comfortably within a typical millisecond-class decision budget for well-structured policies.
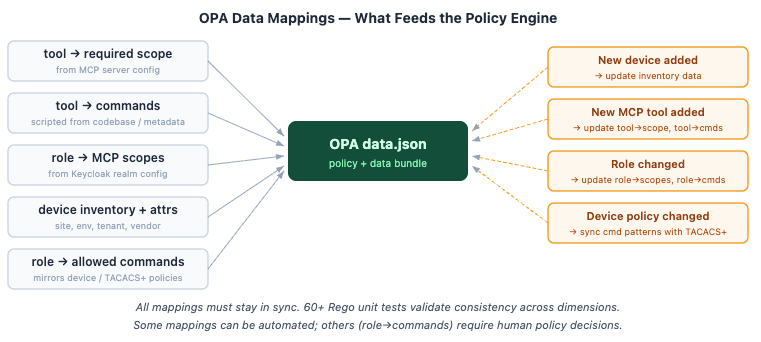
The Hard Part: Keeping OPA's Data Mappings in Sync
One thing we learned the hard way: the policy is the easy part; the data mappings are the real work. For OPA to make a 3-layer decision, it needs consistent, up-to-date data across multiple dimensions: which MCP tool requires which scope, which commands each tool actually executes on the device, which roles map to which scopes, device inventory with ABAC attributes, and per-role command patterns matching what is enforced locally on devices or in TACACS+. All of these must stay in sync. When a new device joins the inventory, a new MCP tool is added, or a role changes, the data file must be updated, or OPA makes decisions against stale reality.
Some of this can be automated. For example, the mapping from MCP tools to the commands they execute can be extracted from tool metadata or scripted from the MCP server codebase. Device inventory can be pulled from a source of truth. But some mappings, like which commands a role should be allowed to run, are policy decisions that require human judgment and review. The 60+ unit tests are not a luxury; they are what keep these mappings from contradicting each other as the system evolves.
As Composio describes in their guide to secure AI agent infrastructure ![]() : "The tool-calling layer queries this policy engine before every action, ensuring every operation is explicitly permitted."
: "The tool-calling layer queries this policy engine before every action, ensuring every operation is explicitly permitted."
The Confused Deputy Problem
A confused deputy attack occurs when a system with broad privileges is manipulated into performing actions on behalf of an attacker. In agentic AI, this means tricking an agent into calling tools or executing commands it should never have been authorised to use.
An AI agent has broad capabilities by design. It is meant to understand requests and select the right tools. But what happens when a prompt injection or a badly designed MCP tool causes the agent to call something it should not? Without a policy layer, the agent becomes a confused deputy, meaning it has the technical ability to act but no concept of whether it should.
The MCP specification's security best practices ![]() dedicate an entire section to the confused deputy problem, warning that "attackers can exploit MCP proxy servers that connect to third-party APIs, creating 'confused deputy' vulnerabilities." The spec also explicitly warns against over-broad scopes, which is when an MCP server exposes every scope in scopes_supported, and the client requests them all; a single leaked token becomes a skeleton key.
dedicate an entire section to the confused deputy problem, warning that "attackers can exploit MCP proxy servers that connect to third-party APIs, creating 'confused deputy' vulnerabilities." The spec also explicitly warns against over-broad scopes, which is when an MCP server exposes every scope in scopes_supported, and the client requests them all; a single leaked token becomes a skeleton key.
Catalogued Threats: MITRE ATLAS and OWASP on Agentic AI
MITRE ATLAS ![]() expanded its coverage of agent-related attack patterns in the 2025-2026 releases, adding techniques around prompt injection (AML.T0051
expanded its coverage of agent-related attack patterns in the 2025-2026 releases, adding techniques around prompt injection (AML.T0051 ![]() ), agent context poisoning, configuration discovery, and tool-invocation-based exfiltration, developed in collaboration with Zenity Labs
), agent context poisoning, configuration discovery, and tool-invocation-based exfiltration, developed in collaboration with Zenity Labs ![]() . These are catalogued attack techniques, not theoretical risks.
. These are catalogued attack techniques, not theoretical risks.
The OWASP Top 10 for Agentic Applications (2026) ![]() , peer-reviewed by 100+ experts, frames Agent Goal Hijacking as the leading risk and emphasizes minimizing unnecessary agent capability. Agents should never have more access than the minimum required for the current task.
, peer-reviewed by 100+ experts, frames Agent Goal Hijacking as the leading risk and emphasizes minimizing unnecessary agent capability. Agents should never have more access than the minimum required for the current task.
OPA addresses this by enforcing policy at the tool-calling layer, not at the agent layer. The agent does not decide what is allowed; instead, the policy engine does. Even if the agent is tricked into attempting a prohibited action, OPA blocks it before it reaches the target system.
Defense in Depth in Practice: How OPA Can Catch a Misconfigured Tool Scope
We tested this on our platform. In one scenario, an intentionally misconfigured MCP tool (run_raw_command_on_device) had a scope that was too broad — ctrl-plane:read instead of the admin-level scope it should have required. The agent could invoke the tool. But OPA's Layer 3 command authorization caught the actual command (vtysh -c 'configure terminal') and blocked it, because the user's role did not allow configuration commands. Defense in depth, working exactly as designed.
This is the core of a zero-trust approach: assume any single layer can fail, and make sure the next layer still stops the action.

Multi-Tenancy with OPA: Attribute-Based Access Control (ABAC) in Practice
One area where OPA really shines over simple scope-based decorators is multi-tenant device access. In our platform, devices belong to different sites (Denver, Seattle, Chicago), environments (prod, lab), and tenants (acme, globex, shared). A user's JWT carries ABAC attributes, such as allowed_sites, allowed_envs, allowed_tenants, and OPA evaluates them against the device inventory in real time.
A Worked Example: How OPA Evaluates Multi-Tenant Device Access
In our demo, Alice, a net-viewer for tenant "acme" in Denver production, can query den-spine-01 and den-leaf-01. But she cannot see chi-leaf-01 (Chicago, globex) or sea-spine-01 (Seattle). Bob, a net-operator for acme and globex across Denver and Seattle, has a wider view. Mark, a net-admin, sees everything, including during maintenance windows when everyone else is locked out.
When we first deployed this, we expected the ABAC rules to need constant refactoring as the device inventory grew. What surprised us was how stable the original policy stayed; the complexity lives in the data file, not in the Rego. With OPA, the whole thing is about 30 lines of policy and a single REST API call that returns {allowed: [...], denied: {device: reason}}.
OPA for AI Agents Beyond Network Devices: Other Use Cases
While our implementation focuses on network infrastructure, the pattern applies anywhere AI agents interact with real systems:
- Database access — OPA can enforce row-level or column-level security based on the agent's context
- Cloud operations — policies can restrict which cloud resources an agent can modify, in which regions, and under what conditions
- API calls — fine-grained control over which endpoints an agent can reach and what parameters it can use
- CI/CD pipelines — ensuring AI-assisted deployments comply with organizational policies before execution
This is not just our approach. Strata's Maverics AI Identity Gateway ![]() uses an embedded OPA engine to evaluate fine-grained policies on MCP tool calls at request time, positioning OPA as a containment boundary where every tool invocation must pass policy evaluation before reaching any upstream service. NIST's AI Agent Standards Initiative
uses an embedded OPA engine to evaluate fine-grained policies on MCP tool calls at request time, positioning OPA as a containment boundary where every tool invocation must pass policy evaluation before reaching any upstream service. NIST's AI Agent Standards Initiative ![]() , announced in February 2026, also highlights the need for enforceable security and identity standards in agentic architectures.
, announced in February 2026, also highlights the need for enforceable security and identity standards in agentic architectures.
The pattern of "policy engine as intelligent proxy between agents and tools" is emerging across the industry.
Running OPA in Production: Avoiding a New Single Point of Failure
If OPA becomes the central policy decision point for your agent architecture, it also becomes a dependency. If it goes down, what happens? The OPA documentation is refreshingly honest about this ![]() : a centralized OPA service is explicitly called a "failure point if not highly available."
: a centralized OPA service is explicitly called a "failure point if not highly available."
Sidecar vs Centralised Deployment: Choosing the Right OPA Architecture
The recommended approach is to co-locate OPA with the services that need it, as a sidecar or host-level daemon rather than a shared cluster service. As the OPA integration docs ![]() put it: "Running OPA locally on the same host as your application or service helps ensure policy decisions are fast and highly available." Each service gets its own OPA instance, so there is no single point of failure and no network hop for decisions.
put it: "Running OPA locally on the same host as your application or service helps ensure policy decisions are fast and highly available." Each service gets its own OPA instance, so there is no single point of failure and no network hop for decisions.
When a centralized deployment makes more sense, for example, when data volumes are large, or you want to manage fewer instances, the OPA team's Kubernetes reference deployment ![]() runs 3 replicas by default with pod anti-affinity, a HorizontalPodAutoscaler (min 3, max 10), and a PodDisruptionBudget.
runs 3 replicas by default with pod anti-affinity, a HorizontalPodAutoscaler (min 3, max 10), and a PodDisruptionBudget.
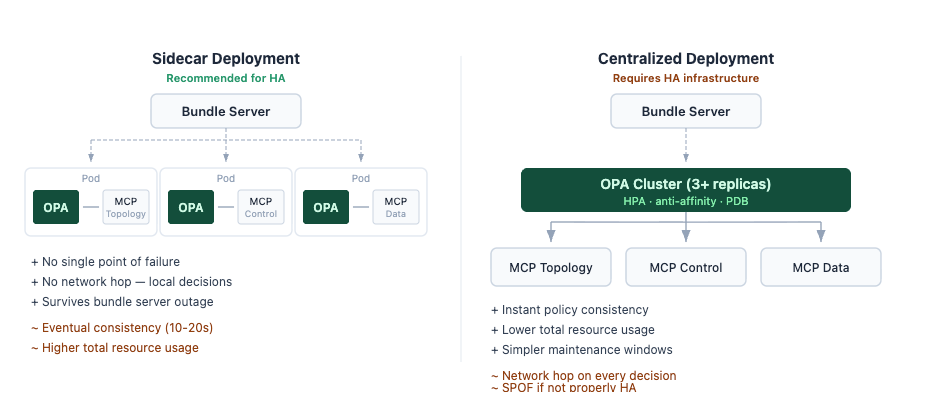
Five Operational Details That Matter When Running OPA
A few operational details that matter:
- Bundle persistence. OPA can persist activated bundles to disk
 , so if the bundle server goes down, OPA continues to enforce the last successfully loaded policy. This is critical — without it, a bundle server outage means OPA restarts with no policy at all.
, so if the bundle server goes down, OPA continues to enforce the last successfully loaded policy. This is critical — without it, a bundle server outage means OPA restarts with no policy at all. - Fail-open vs fail-closed is your decision, not OPA's. The operations docs are explicit: "This logic is entirely the responsibility of the software asking OPA for a policy decision." In an agentic context, fail-closed is almost always the right choice — a denied agent action is recoverable, but an unauthorized one may not be.
- The startup gap. Before bundles are loaded, OPA returns undefined to all queries — which most integrations treat as a deny, but some may not. Use the /health?bundles endpoint as a readiness probe to ensure OPA has loaded its policies before it starts receiving traffic.
- No decision caching across queries. OPA re-evaluates policies from scratch on every request. This is by design as it guarantees consistency, but it means you cannot rely on cached decisions during an outage.
- Eventual consistency in sidecar deployments. When you update a policy bundle, each sidecar picks it up independently on its next polling cycle. With a 10-20 second interval, there is a window where some sidecars enforce the new policy while others still run the old one. For routine policy changes like adding a tool or adjusting a role, this is rarely a problem. But for time-sensitive operations like emergency access revocation or maintenance windows, even a 20-second gap matters. OPA supports long polling to reduce this window, meaning the bundle server responds immediately when a change is available instead of waiting for the next cycle. For operations where instant consistency is critical, a centralized OPA deployment or pushing the change into device-level enforcement (TACACS+, ForceCommand) may be a better fit.

In our deployment, we run OPA as a sidecar alongside the MCP servers, with bundle persistence enabled. If the bundle source becomes unreachable, each OPA instance continues enforcing the last known-good policy independently. The eventual consistency trade-off is acceptable for us because the defense-in-depth layers below OPA, the device-level command authorization, catch anything that slips through during a propagation window. We have not had a policy outage in production yet, which, admittedly, may say more about the simplicity of the sidecar model than about our operational skill.
OPA Is Not a Silver Bullet
OPA is one layer in a defense-in-depth architecture. In our system, it works alongside:
- Keycloak for identity propagation — so we always know who is behind the agent
- OpenBao for JIT SSH certificates — no static credentials, ever
- TACACS+ for device-level command authorization — because when you connect AI to infrastructure, you do not throw away proven mechanisms
- End-to-end audit trails— not a separate subsystem, but built into OPA itself. Every policy query carries the user's JWT (with username), plus an agentId and mcpRequestId propagated from the calling service. OPA's decision logs include these correlation IDs automatically, so you can trace any action from the user's question through the agent, the MCP tool call, and the OPA decision to the final command on the device. This does require configuring OPA's decision logging and ensuring your MCP servers pass the right context in each query
If you only deploy OPA without identity management, you are checking policies against anonymous requests. If you only deploy OPA without device-level enforcement, you are trusting that the policy layer never fails. The zero-trust approach means every layer assumes the others might be compromised.
The Apple Signal
In August 2025, OPA's creators and several Styra engineers joined Apple ![]() . The OPA project confirmed that "there are no changes to the project governance or licensing."
. The OPA project confirmed that "there are no changes to the project governance or licensing." ![]()
Apple's interest signals the strategic value of policy-as-code technology at the highest level. For teams evaluating OPA today, the important point is that OPA remains a mature CNCF project with broad production use — Netflix, Goldman Sachs, Google Cloud, T-Mobile, and hundreds of others. The transition around Styra is worth monitoring, but it does not change OPA's viability for new deployments.
The Bottom Line
We keep adding capabilities to AI agents. We connect them to databases, APIs, infrastructure, and services. The demos are impressive, and the productivity gains are real.
But capabilities without controls are a liability.
OPA gives you a way to define, in code, what your agents are allowed to do, and to enforce it consistently, fast, and across your entire stack. It is not the only piece you need. But if you are building agentic systems that touch production infrastructure, it is a piece you cannot skip.
References
| # | Source | Description |
|---|---|---|
| 1 | Gartner Top Predictions 2025 and Beyond | 25% of enterprise breaches by 2028 from AI agent abuse; 40% of CIOs will demand Guardian Agents |
| 2 | BigID AI Risk & Readiness Report 2025 | 47% of orgs have no AI security controls; only 6% have advanced AI security strategy |
| 3 | OPA CNCF Graduation Announcement | Feb 2021; first CNCF project focused on authorization |
| 4 | OPA Adopters (GitHub) | Production users incl. Pinterest (400K QPS), Netflix, Goldman Sachs |
| 5 | OPA Policy Performance Docs | Sub-millisecond evaluation benchmarks |
| 6 | Composio: Secure AI Agent Infrastructure Guide | Policy engine pattern for AI agent tool calls |
| 7 | MCP Security Best Practices | Confused deputy, token misuse, over-broad scope warnings |
| 8 | MITRE ATLAS | AI/ML attack techniques including prompt injection and agentic patterns |
| 9 | Zenity Labs & MITRE ATLAS Collaboration | Agentic AI attack techniques added to ATLAS |
| 10 | OWASP Top 10 for Agentic Applications 2026 | Agent Goal Hijacking as leading risk |
| 11 | Strata: Securing MCP Servers at Scale | OPA-based policy enforcement for MCP tool calls |
| 12 | NIST AI Agent Standards Initiative | Feb 2026; security & identity standards for agentic AI |
| 13 | OPA Creators Join Apple | Aug 2025; OPA creators and Styra engineers joined Apple |
| 14 | Note from OPA Maintainers | "No changes to project governance or licensing" |
| 15 | OPA Deployment Guide | Sidecar vs centralized; HA considerations |
| 16 | OPA Bundle Management | Bundle persistence for resilience during outages |
| 17 | OPA Operations | Fail-open/fail-closed guidance; startup behavior |
Further reading from CodiLime:


