


This is the third part of the series, where we focus on the next two classes of ML methods: natural language processing and reinforcement learning. Also, we outline the major challenges of applying various ideas for ML techniques to network problems. This part also summarizes all three parts of the blog post. The first part can be found here, and the second part can be found here.
Natural language processing (NLP)
Natural language processing is a part of AI which allows computer programs to understand statements and words written in human language. NLP combines a plethora of algorithms, statistical models and machine learning techniques to process and analyze text and speech data. There are many such applications, such as sentiment analysis, chatbots, answering questions, and information extraction, to name a few.
The recent success of ChatGPT, its relatively high quality responses and possibility for fine-tuning provoke the question, how can such models be used in networking and data center management tasks.
For instance, ChatGPT can be appropriately fine-tuned on a specific set of verified device configuration scripts together with corresponding templates and best practices. OpenAI (the company behind ChatGPT) promises that this allows for fast extraction of useful information from device configuration scripts.
For example, this can speed up troubleshooting, e.g. such an updated model can analyze and verify device configuration scripts in terms of semantic and syntax errors. It is also said that it could help to automate the process of updating device configuration. The required changes can be identified and new scripts can be generated, ensuring they conform to industry standard and security policies. For sure a domain expert is making the final decision and is taking responsibility, but if even only some of these promises are true, the expert’s efficiency could be improved significantly.
Another practical use case that could help network administrators is using a chatbot for querying various databases storing various configuration data. The possibility for writing or communicating queries in natural language for the needed information, which can be translated to a specific query language, can improve the data retrieval time without thorough knowledge of database schema and query language.
One task that can be done by ChatGPT is text summarization. It is worth checking if trouble ticket data, extended by engineers with specific comments, or contextual data in consecutive trouble handling steps, can be nicely summarized by such an NLP tool. This could help to organize knowledge from trouble ticket data to organize a system of hints when a new trouble ticket arrives.
Current NLP-based solutions have many limitations and can provide incorrect, misleading and silly answers, but the technology is getting better and better and it is definitely worth checking out other NLP promises and finding potentially profitable use cases.
NLP tools and frameworks worth your attention
Below we listed the most popular NLP tools/frameworks:
Reinforcement Learning
Reinforcement learning (RL) is another type of machine learning. The objective of reinforcement learning is to learn how to make decisions based on past experiences, on past decisions which could have been right or wrong. The key notions related to RL are AI agent, an environment, environment state space, actions set, and reward system.
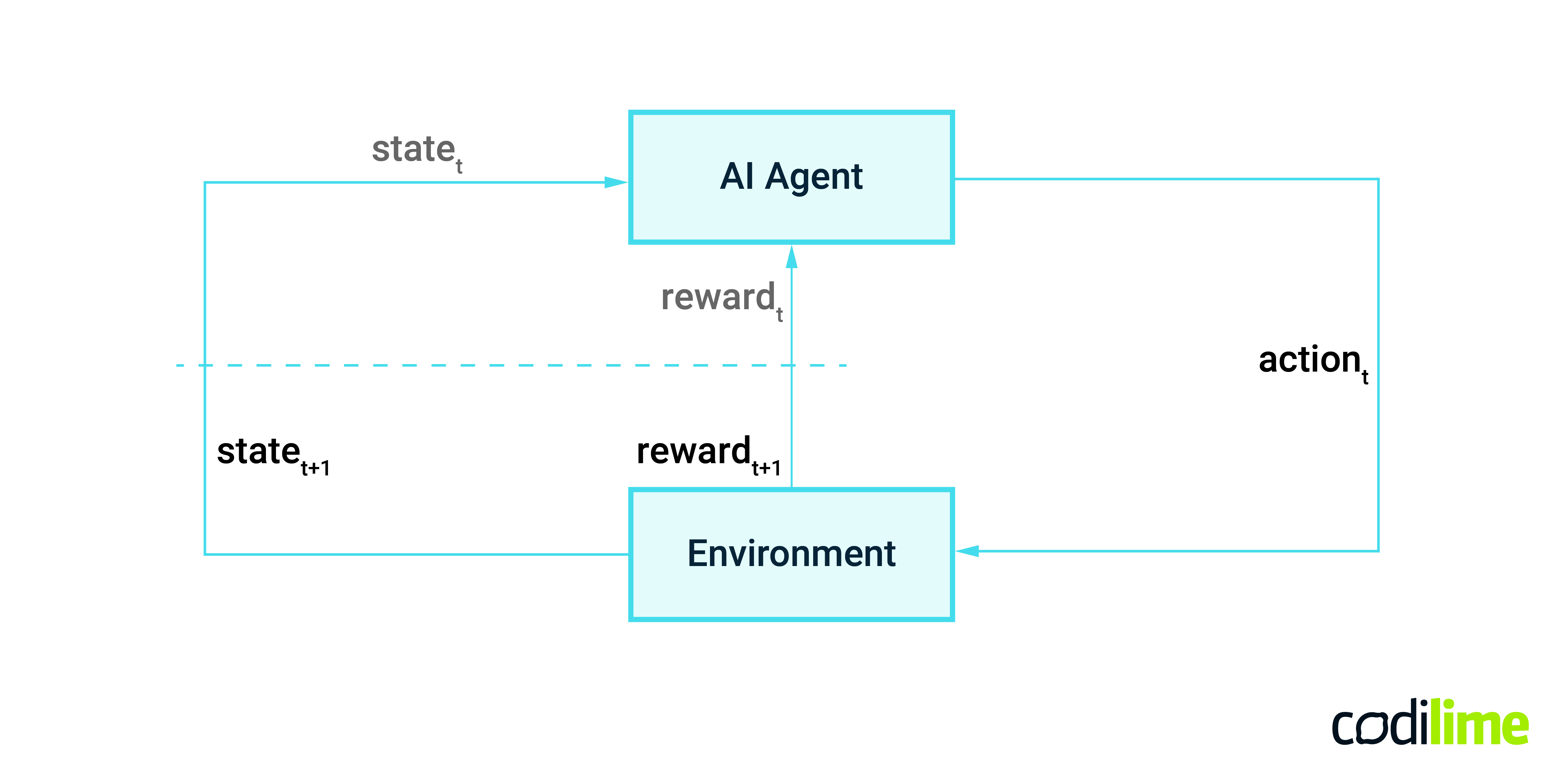
The AI agent interacts with the environment by making actions. Each action changes the state of the environment and can be evaluated in the form of a reward or penalty value. The discovered combinations of state, action, reward are used to learn a policy, which is a decision-making strategy the agent can use to select an optimal action in a given state. The goal is to maximize the cumulative reward value, obtained in finite consecutive time steps (Figure 5).
The reinforcement learning approach can be applied for network use cases, e.g. to optimize routing metrics in a network with link-state routing protocol (OSPF, IS-IS). In such a case, the network is an environment consisting of nodes and links with a given capacity. The environment state can be described by particular link weights that are used to compute the shortests paths between any pair of nodes. The AI agent is a central unit that can perform an action, i.e change those link weights. In consequence, the optimal routing paths for some origin-destination pairs of nodes may change.
Imagine that you also have a forecasted time series representing traffic demands between any pair of nodes, for which you would like to optimize the link weights. Let us assume that forecasted trends in traffic flows between nodes for current routing settings will cause some congestion on some links. Then some of the traffic will start to drop. The goal of the RL algorithm would be to learn the sequence of actions (changes in link weights on particular links), so that some routing paths traversing congested links are modified and less loaded parts of the network are used for them.
Designing RL algorithms for network problems is very challenging, as it usually assumes access to the real environment. This is a very unrealistic assumption, because no one will allow the training of an RL-based decision policy in a real environment, especially one as dynamic as a network environment. That is why the example presented above is slightly different. It operates on a network model at traffic flow level and tries to learn how to optimize routing for future traffic conditions. The goal is to find a set of changes in the routing configuration and proactively inform a network admin of expected congestion with solutions to overcome it.
There are many other approaches applying RL to routing-related problems in networking. They can be found here ![]() .
.
If you want to improve your environment, see what we can do for you with our network environment services.
Challenges of AI and ML use in networks
If you want to solve practical network problems, you can use a wide range of available AI/ML methods, depending on the nature of the problem and the specific requirements related to it.
However there are many challenges to overcome. The most important are listed below.
- Data volume and quality: Measuring and collecting data from the network is a complex issue (you may want to read this blogpost for more details). Sometimes the possibility of obtaining the appropriate volume of data needed for further analysis may be limited for various reasons. Lack of proper data may limit the potential of the ML methods that you want to use. Also the quality of data used to train ML models is crucial for their accuracy.
- Training data imbalance: Collected training data can be imbalanced. For instance data anomalies that need to be discovered may be too rare to build valuable classification models.
- Feature extraction and model accuracy: Extracting relevant features from raw data and selecting the right features is critical to model accuracy. The process usually requires iterative experimentation and close cooperation between a data scientist, ML engineer, and domain expert.
- Model interpretability: Even accurate models must be interpretable. Decisions made based on such models need to be understandable to network engineers.
- Scalability: Many machine learning methods can be used for network data but in many cases they were not designed for such data. That is why choosing the right ML model in terms of its scalability can be a challenge.
- Real time processing issue: You need to know that many ML algorithms were not designed for real-time data processing, which is often the case in a dynamic network environment.
- Unique characteristics of network environments: It is quite probable that ML models that work well for a given network environment can be inappropriate for other, bigger or more complex networks. You should also know that networks are a very heterogeneous environment (in terms of technology, topology, target use, etc.) and individual network segments can differ significantly from each other. Thus the usage of pretrained models (transfer learning) may not be possible and the models will have to be built from scratch.
- Required resources: Data collection as well as training, usage and maintenance of ML models require significant storage and computational capacity. Especially when deep learning algorithms are used.
- Multidisciplinary teams: Application of various ML techniques usually requires engagement of engineers skilled in many disciplines. Tight collaboration between data scientists, ML engineers and domain experts is crucial for successful deployments.

Conclusions
In the last part of the series, we have presented two classes of ML methods: natural language processing and reinforcement learning. We briefly described which data they work on and what they can produce as the output. We suggested a few ideas of using them in the context of network and DC management and listed examples of the most popular algorithms and frameworks. We also describe the main challenges that need to be overcome when putting ML into practice.
Final conclusions
We have presented the crucial types of AI/ML methods and algorithms that are, at least in our opinion, the most relevant and helpful in the context of network-related problems. Also, some potential use cases where particular methods can be used have been mentioned. For each class of AI/ML problems, we have listed examples of the popular algorithms and frameworks. Finding the optimal algorithm requires iterative experiments with well-prepared data for the specific use case. We have outlined the necessity of tight collaboration between data scientists, ML engineers and domain experts at the stage of preparing valuable ML models.
There is a common opinion among researchers and practitioners dealing with network problems, and trying to deploy various ML techniques, that there are many clear ideas but little transfer to industry. Engineers can identify weak points in existing network deployments and know what needs to be improved, but very often they do not know exactly how to apply ML techniques to automate such a process. At the same time, tremendous progress in the area of AI applications and in ML methods and algorithms is taking place. It seems mandatory for modern companies to build competences and data processing culture in this area.


