


According to the Stack Overflow Developer Survey 2020, Rust is the most popular programming language. It won the title for the fifth year running, and the good news hardly ends there. Also in 2020, Linux kernel developers proposed including Rust in Linux Kernel, which was originally written in C. Quite recently, Facebook joined the Rust Foundation, an organization driving the development of the language Rust, with the intention of helping it go mainstream.
Given all this, we decided to check if Rust can replace C in low-level network programming to ensure higher safety without sacrificing high performance. For our proof of concept, we chose the DPDK library, as it is used to write user space applications for packet processing, where performance plays a crucial role.
>>Check our low-level programming enginnering services to learn more.
Rust as a language for system programming
Rust was created to provide high performance, with a strong emphasis on the code’s safety. C compilers don't really care about safety. This means programmers need to take care not to write a program that causes memory violation or data races.
In Rust, most of these problems are detected during the compilation process. You can write code in two different modes: safe Rust, which imposes on the programmer additional restrictions (e.g. object ownership management), but ensures that the code works properly. The other mode is unsafe Rust, which gives the programmer more autonomy (e.g. can operate on raw C-like pointers), but the code may break. For these reasons, Rust is an excellent choice for system programming calling for both high performance and safety. You can also compare Rust's performance vs C++.
If you're also facing a dilemma whether to use Go or Rust, we have a great comparison article.


C libraries in Rust
Numerous low-level system-related projects, like operating systems, game engines, and networking applications are written in C. This is mainly because there has never been any real alternative guaranteeing high performance and easy access to memory and operating system functionalities.
Today, Rust is considered an alternative, even if rewriting entire projects in Rust would break most budgets. Luckily, we don't have to. Rust supports calling C functions from Rust code without any additional performance overhead.
Another popular comparison in performance is Rust and Python.

Suppose we have a simple library written in C:
#include <stdio.h>
#include <stdlib.h>
struct CStruct {
int32_t a;
};
struct CStruct *init_struct(int32_t a) {
struct CStruct *s = malloc(sizeof(*s));
if (s != NULL)
s->a = a;
return s;
}
void free_struct(struct CStruct *s) {
free(s);
}
We can create bindings to these functions and structure and use them as follows:
#[repr(C)]
struct CStruct {
a: i32,
}
extern "C" {
fn init_struct(a: i32) -> *mut CStruct;
fn free_struct(s: *mut CStruct);
}
fn main() {
unsafe {
let s = init_struct(5);
if !s.is_null() {
println!("s->a = {}", (*s).a);
}
free_struct(s);
}
}
These bindings are easy to write. There are even special tools (rust-bindgen ![]() ) that can generate them automatically. They are unfortunately very raw and require unsafe blocks to use them so we cannot take full advantage of the Rust capabilities. In this case, the programmer needs to check if the allocation succeeded (s is not null) before dereferencing it and accessing a field. We could theoretically ignore the fact that init_struct can return nullptr in some cases and read s.a without this check. This would work most of the time but would sometimes fail in runtime—that's why it's unsafe in Rust. We also need to remember to free up memory—or risk a memory leak. However, these bindings are a good first step to a more decent API that would enforce the correct usage of this library. The above code can be wrapped like this:
) that can generate them automatically. They are unfortunately very raw and require unsafe blocks to use them so we cannot take full advantage of the Rust capabilities. In this case, the programmer needs to check if the allocation succeeded (s is not null) before dereferencing it and accessing a field. We could theoretically ignore the fact that init_struct can return nullptr in some cases and read s.a without this check. This would work most of the time but would sometimes fail in runtime—that's why it's unsafe in Rust. We also need to remember to free up memory—or risk a memory leak. However, these bindings are a good first step to a more decent API that would enforce the correct usage of this library. The above code can be wrapped like this:
struct RustStruct {
cstr: *mut CStruct,
}
impl RustStruct {
fn new(a: i32) -> Result<Self, ()> {
// use raw bindings to create the structure
let cstr = unsafe {init_struct(a)};
// return Err if failed to create or Ok if succeeded
if cstr.is_null() {
return Err(());
}
Ok(RustStruct {cstr})
}
fn get_a(&self) -> i32 {
// at this point we know that self.cstr is not null
// so it's fine to just dereference it
unsafe {(*self.cstr).a}
}
}
impl Drop for RustStruct {
fn drop(&mut self) {
// freeing the struct won’t fail
unsafe {free_struct(self.cstr)};
}
}
// no need to remember freeing the struct - it will be freed when out of scope
fn main() -> Result<(), ()> {
// we need to handle the case where RustStruct::new failed and
// returned Err so we cannot use incorrectly allocated s
let s = RustStruct::new(5)?;
println!("s->a = {}", s.get_a());
Ok(())
}
unsafe blocks are moved to library code so in main()we can use the safe Rust API.
DPDK in Rust
Allowing for packet processing in user-space, DPDK is a library used in high-performance networking applications programming. DPDK is written in C, so using it with Rust is inconvenient and unsafe without a properly prepared API.
We are not the first ones who have attempted to create bindings for DPDK in Rust. We decided to base our API on some other project—ANLAB-KAIST/rust-dpdk ![]() . This project uses bindgen while compiling the code to generate bindings for the specified DPDK version.
. This project uses bindgen while compiling the code to generate bindings for the specified DPDK version.
Thanks to that, updating the API to the newer DPDK version is straightforward. Additionally, a good deal of the high-level API was already well written so we didn't need to write it from scratch. Ultimately, we only added a few features to this library and fixed some issues. Our final version of this API is here: codilime/rust-dpdk ![]() .
.
The interface for communication with DPDK has been designed in such a way that the programmer doesn't have to remember nonobvious dependencies that could often cause errors in DPDK applications. Below, we present some examples of the API with the corresponding code in C.
EAL initialization
{
int ret = rte_eal_init(argc, argv);
argc -= ret;
argv += ret;
// parse application specific arguments
// ...
rte_eal_cleanup();
}
{
// args - command line arguments
let eal = Eal::new(&mut args)?; // parse eal specific arguments
// parse application specific arguments
// ...
} // eal.drop() calls rte_eal_cleanup() and others
Most of the DPDK functions can be called only after EAL initialization. In Rust, this was solved by creating an instance of an Eal structure. This structure provides more functionalities in its methods. Additionally, thanks to wrapping the EAL to structure, a cleanup need not be performed at the end of the program. It's automatically called when the eal structure drops.
Ethdev and RX/TX queue initialization
{
RTE_ETH_FOREACH_DEV(portid) {
// configure the device and create 1 RX and 1 TX queue
rte_eth_dev_configure(portid, 1, 1, &port_config);
// configure the queues
rte_eth_rx_queue_setup(portid, 0, nb_rxd,
rte_eth_dev_socket_id(portid),
&rxq_config,
pktmbuf_pool);
rte_eth_tx_queue_setup(portid, 0, nb_txd,
rte_eth_dev_socket_id(portid),
&txq_config);
rte_eth_dev_start(portid);
rte_eth_promiscuous_enable(portid);
}
// ...
// deinitialization
RTE_ETH_FOREACH_DEV(portid) {
rte_eth_dev_stop(portid);
rte_eth_dev_close(portid);
}
}
{
let uninit_ports = eal.ports()?;
let ports_with_queues = uninit_ports.into_iter().map(|uninit_port| {
// configure the device, create and configure 1 RX and 1 TX queue
let (port, (rxqs, txqs)) = uninit_port.init(1, 1, None);
port.start().unwrap();
port.set_promiscuous(true);
(port, (rxqs, txqs))
}).collect::<Vec<_>>();
// ...
} // port.drop() calls rte_eth_dev_stop() and rte_eth_dev_close()
In DPDK applications, ethdev initialization is usually done once, at the beginning of the program. In initialization, a number of queues can be passed to configure. In Rust, eal.ports()returns a list of uninitialized ports, which can later be initialized separately, begetting a structure corresponding to the initialized port and lists of RX and TX queues. Calling eal.ports() a second time causes a runtime error, so a single device can’t be initialized multiple times.
Our Rust API simplifies initialization—a large portion of DPDK function calls is hidden inside the uninit_port.init()implementation. This of course means that we don't have that much power when configuring devices and queues in Rust, but we get simpler implementation.
RX/TX queues
{
struct rte_mbuf *pkts_burst[MAX_PKT_BURST];
uint16_t nb_recv = rte_eth_rx_burst(portid, queueid, pkts_burst, MAX_PKT_BURST);
// ...
uint16_t nb_sent = rte_eth_tx_burst(portid, queueid, pkts_burst, MAX_PKT_BURST);
}
{
let mut pkts = ArrayVec::<Packet<TestPriv>, MAX_PKT_BURST>::new();
let nb_recv = rx_queue.rx(&mut pkts);
// ...
let nb_sent = tx_queue.tx(&mut pkts);
}
Each queue is assigned to some ethdev, so it would be easier to operate on queues rather than on devices when sending and receiving packets. In Rust, we have specific structures for RX and TX queues, so operating on them is easier.
Additionally, the RX and TX queues in DPDK are not thread-safe, so the structures were designed in such a way that any attempt to use them in multiple threads results in a compile-time error.
Packet content modification
{
struct rte_ether_hdr *eth = rte_pktmbuf_mtod(pkt, struct rte_ether_hdr *);
struct rte_ether_addr smac = (struct rte_ether_addr) {
.addr_bytes = {1, 2, 3, 4, 5, 6}
};
struct rte_ether_addr dmac = (struct rte_ether_addr) {
.addr_bytes = {6, 5, 4, 3, 2, 1}
};
memcpy(ð->d_addr.addr_bytes, &dmac.addr_bytes, sizeof(dmac.addr_bytes));
memcpy(ð->s_addr.addr_bytes, &smac.addr_bytes, sizeof(smac.addr_bytes));
}
{
let mut eth = match EthernetFrame::new_checked(pkt.data_mut())?;
eth.set_src_addr(EthernetAddress([1, 2, 3, 4, 5, 6]));
eth.set_dst_addr(EthernetAddress([6, 5, 4, 3, 2, 1]));
}
Using Rust allows us to easily add functionalities written by somebody else by simply adding crate names to the Cargo.toml file. So, in the case of packet data modifications (e.g. header modification), we can simply use external libraries. We've tested and compared several open-source libraries—conclusions and performance tests can be found below.
Multiple threads
{
RTE_LCORE_FOREACH_WORKER(lcore_id) {
rte_eal_remote_launch(lcore_function, private, lcore_id);
}
}
{
dpdk::thread::scope(|scope| {
for lcore in eal.lcores() {
lcore.launch(scope, |private| lcore_function(private));
}
})?;
}
DPDK allows us to start some code on a specific logical core. We've combined Rust thread management with DPDK lcore management. Thanks to this, the API allows you to create threads on specific lcores and at the same time provides the convenience and safety Rust threads are known for.
Example: l2fwd
In order to test the Rust API, we implemented an application from DPDK sources in Rust. We decided to test l2fwd (l2fwd description ![]() ). It is a simple application that can receive packets from one port, modify the MAC addresses of an Ethernet header, and then forward the packets to another port. Here you can find the source codes of l2fwd in C
). It is a simple application that can receive packets from one port, modify the MAC addresses of an Ethernet header, and then forward the packets to another port. Here you can find the source codes of l2fwd in C ![]() and l2fwd in Rust
and l2fwd in Rust ![]() .
.
>> Explore our Rust development services
Rust vs C: performance comparison
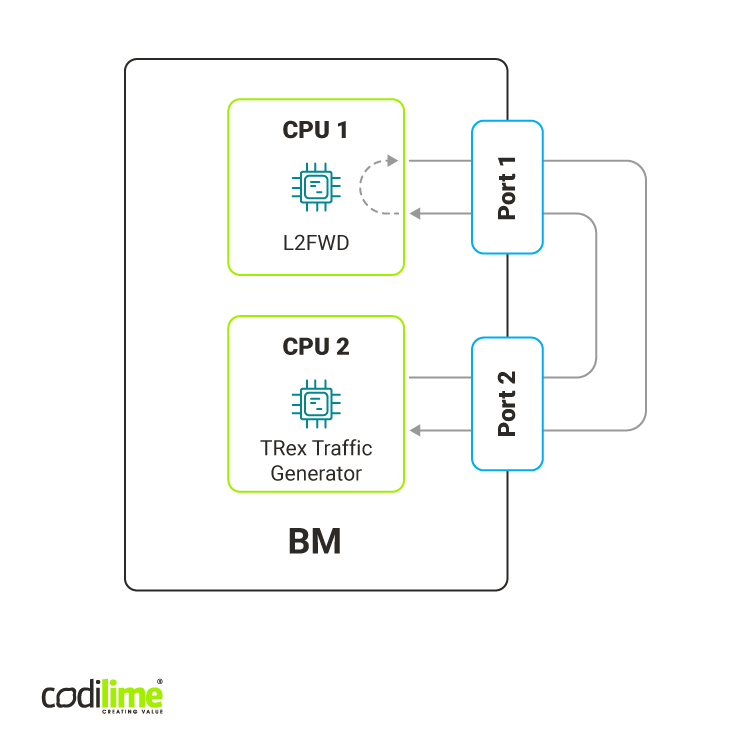
We compared the performance of both applications in a one bare-metal environment with two Intel Xeon Gold 6252 CPUs. The l2fwd used one core of the first CPU (NUMA node 0) while the TRex traffic generator used 16 cores of the other CPU (NUMA node 1). Both applications used memory local for their NUMA node so they didn't share the resources that could have an impact on performance (e.g. caches, memory).
Also, l2fwd used a single interface of a 25Gbps Intel Ethernet Network Adapter XXV710 connected to NUMA node 0 and one RX and TX queue for traffic management. TRex used an NIC with one 25 Gbps interface connected to NUMA node 1.
The traffic generated consisted of L2 packets with a single IPv4 and UDP headers with varying IP addresses and UDP ports. When testing bigger packet sizes, additional data was added at the end of the packet. More details about the environment can be found in our repository ![]() .
.
While testing, we also measured the core utilization. In the main function, l2fwd polls on the incoming packets in an infinite loop. This allowed us to achieve better performance than traditional interrupt packet handling. However, CPU usage is always around 100%, so measuring the real core utilization is harder. We used the method described here ![]() to measure the CPU utilization.
to measure the CPU utilization.
Every loop iteration, l2fwd tries to read at most 32 packets using rte_eth_rx_burst(). We can calculate the average number of packets received from these calls. If the average value is high, it means that in most loops l2fwd receives and processes packets. If this value is low, l2fwd mostly loops without doing any crucial work.
Overload Test
The overload test involved sending as much traffic as we could in order to exceed l2fwd's processing capabilities. In this case, we wanted to test software performance knowing that l2fwd would always have some work to do.
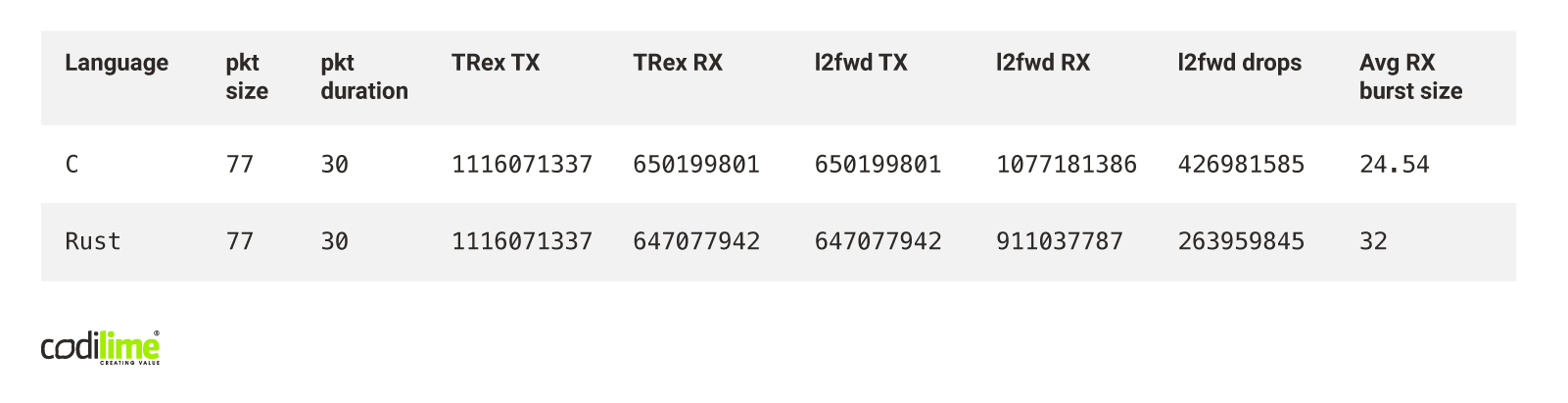
Tab. 1 Rust vs C: overload test results
Rust clearly achieved worse results in this test. Rust l2fwd received around 1.2 less packets than C l2fwd and sent fewer packets. We can also see that the average RX burst is maximal (32) for Rust l2fwd and we achieved around 24.5 RX burst size for C l2fwd. This all means that the C implementation is overall faster because it could process more packets. We believe that the main cause of these differences is that the management of dropped packets written in Rust is less efficient when compared to C.
The drop rate in both applications is very high. The most probable cause is that we used a single TX queue and it couldn't handle more packets.
It also explains why C’s implementation drop rate is higher than Rust’s. Both applications wanted to send more than the TX queue could handle, but C was faster than Rust and tried to send more packets, which ultimately resulted in a higher drop rate.
RFC2544
We ran the RFC2544 test on both l2fwd implementations. The results are presented below.
Note that the real sent packet sizes in the charts consist of the packet data and additional 13 bytes added by TRex (preambule and IFG).
![C vs Rust throughput comparison [bps]](/img/codilime_graph_1.png)
![C vs Rust throughput comparison [pps]](/img/codilime_graph_3.png)
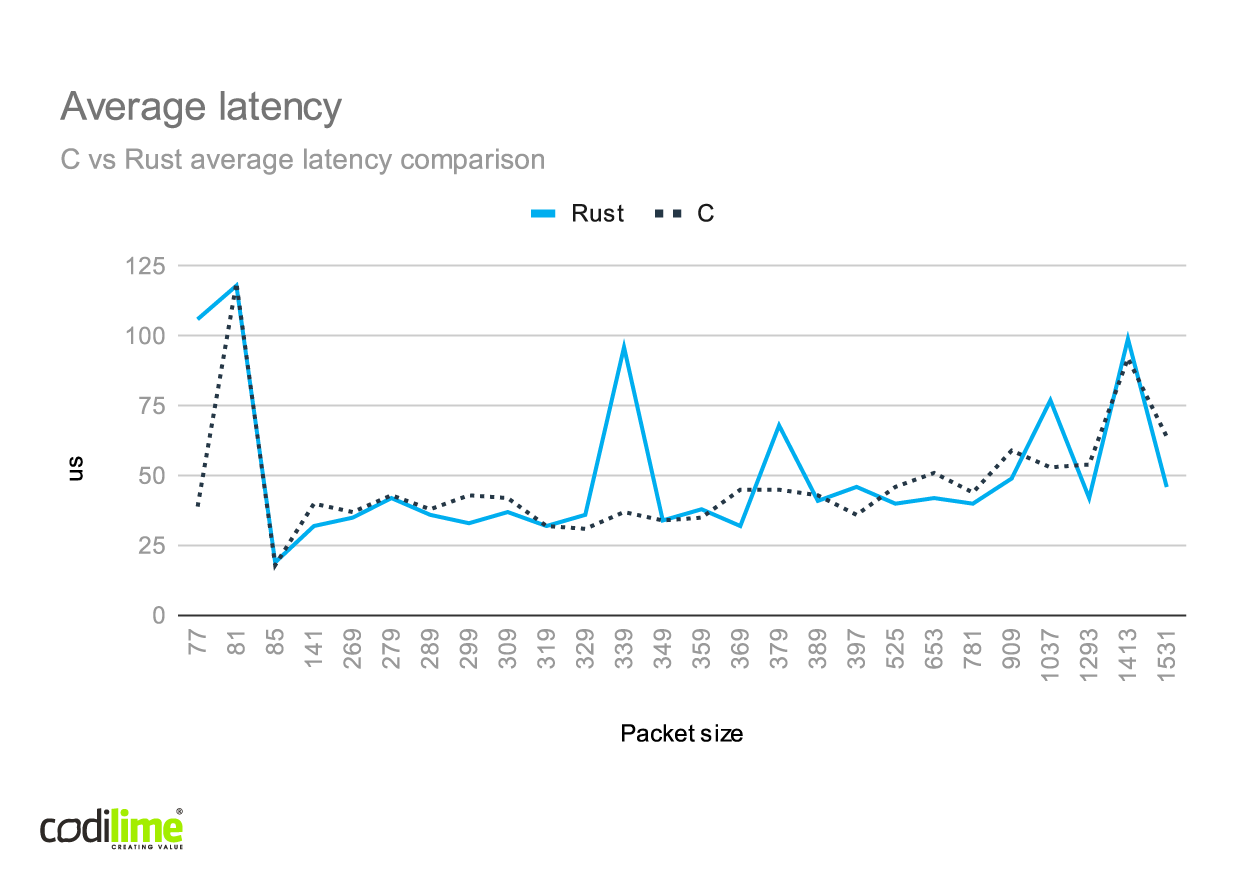
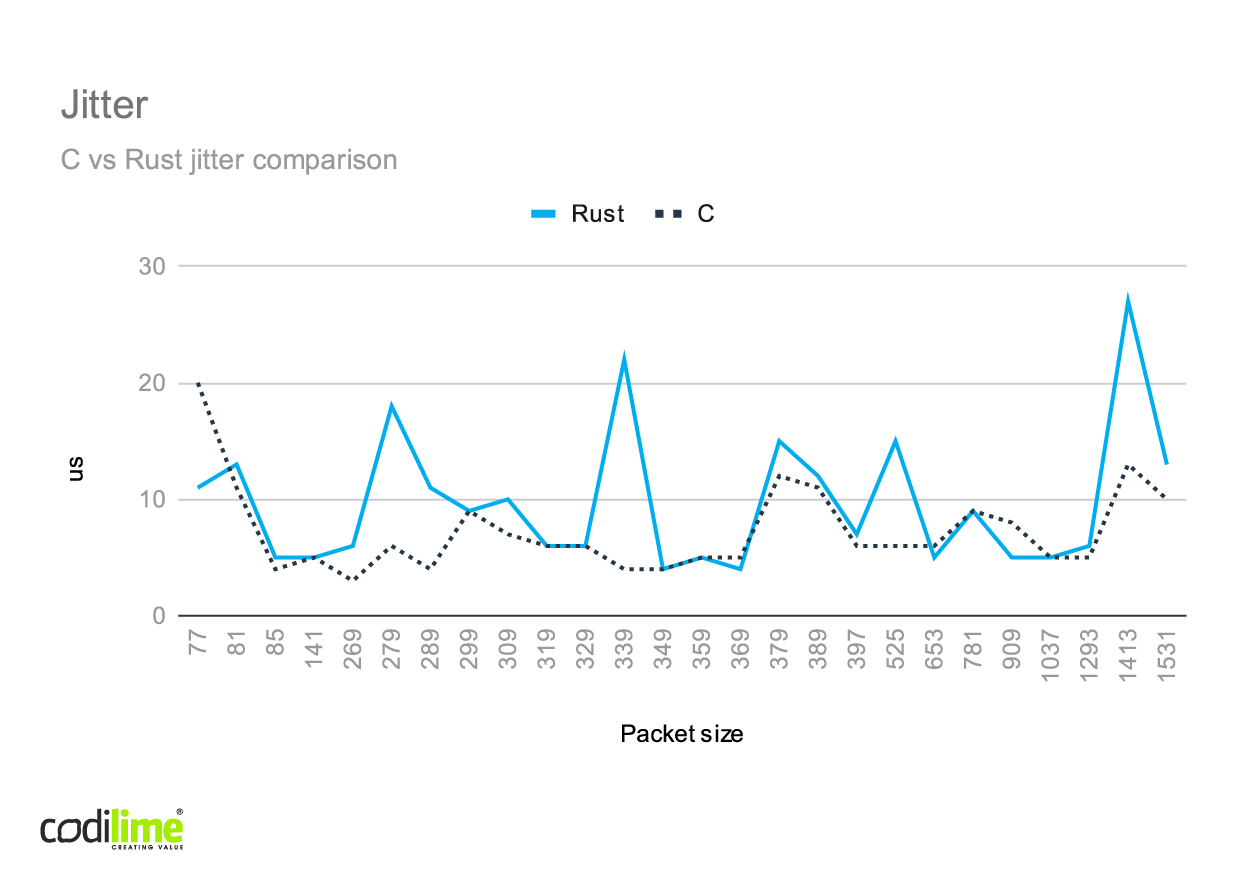
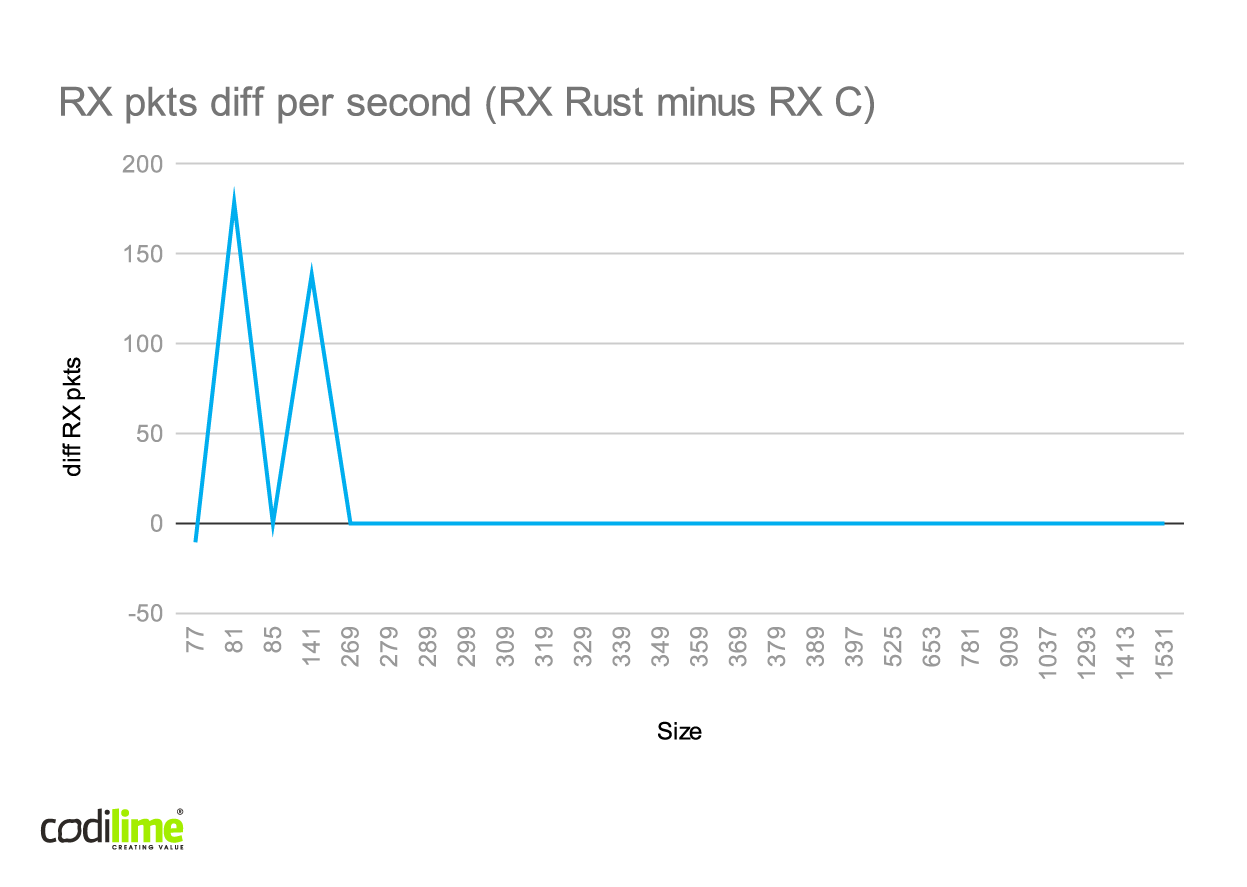
While testing, we observed that the average number of packets per RX burst was always less than 2. This means that l2fwd was mainly idle during tests, which explains why the results for C and Rust are so similar. To see visible differences, we would need to test them with more complex applications.
In the case of smaller packets, we couldn't achieve 25 Gbps, even though l2fwd was quite idle. This was attributable to a single TX queue failing to handle the whole traffic.
We can also see that there were some tests in which Rust achieved slightly better performance than C, though in the overload test it fared worse. We suspect that the Rust implementation is worse mainly in dropped packet management, so in the case of RFC2544, where drops are not allowed, we can see that the Rust implementation gives comparable or sometimes better results than C.
Appendix: Packet processing libraries
We tested some libraries for packet data modifications. The tests consisted of modifying the packet's data (setting source and destination MAC addresses and source IP address to constant values). The whole test was performed locally on a single machine, so it tested only memory modifications performed by the libraries, not traffic management. The test sources can be found in our repository ![]() .
.
Tests compiled with link time optimizations performed significantly better than those without them, so we compared these two cases.
Etherparse library
For etherparse ![]() , we tried multiple packet modification methods:
, we tried multiple packet modification methods:
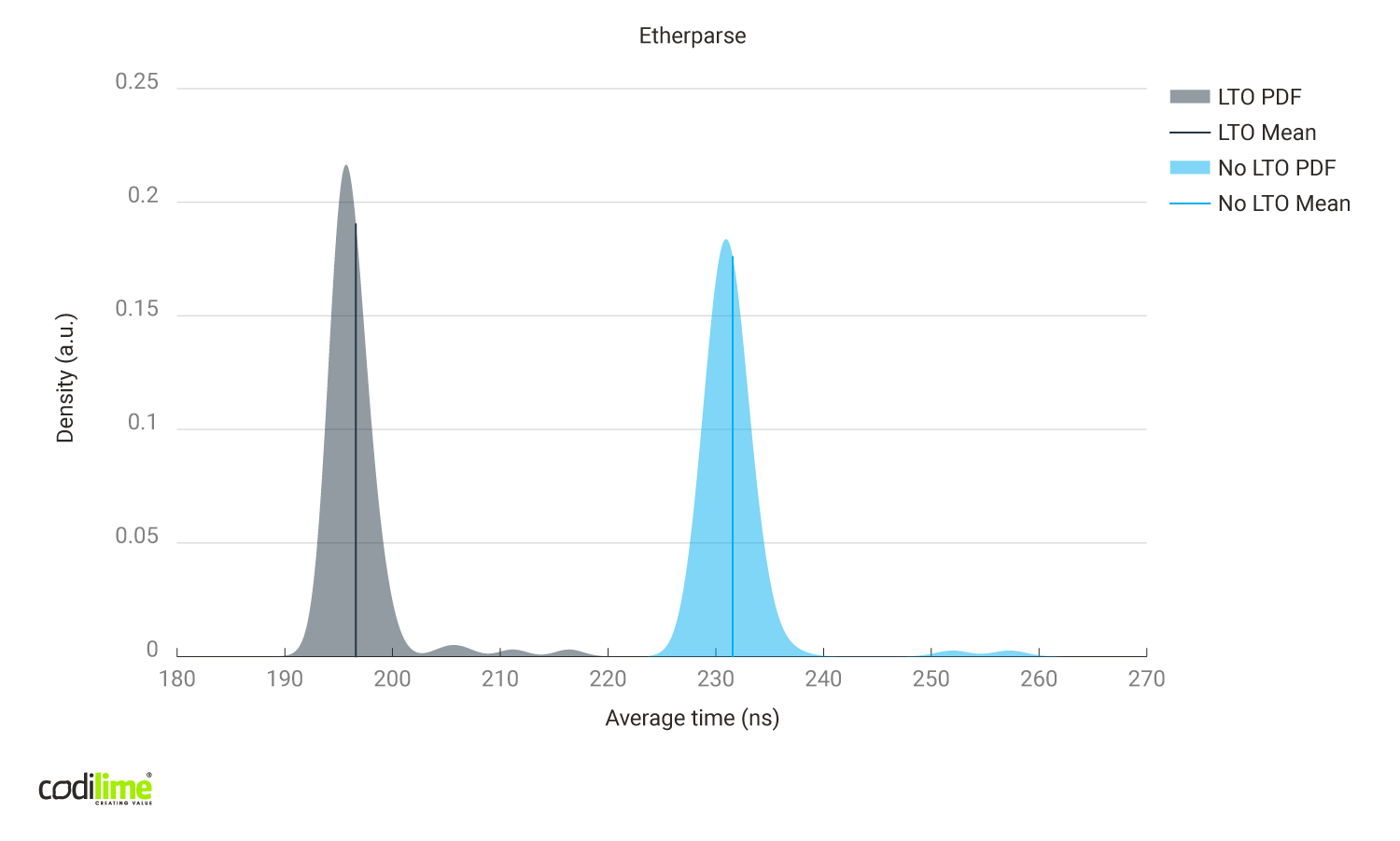
- creating the packet from scratch instead of modifying just the places needed:
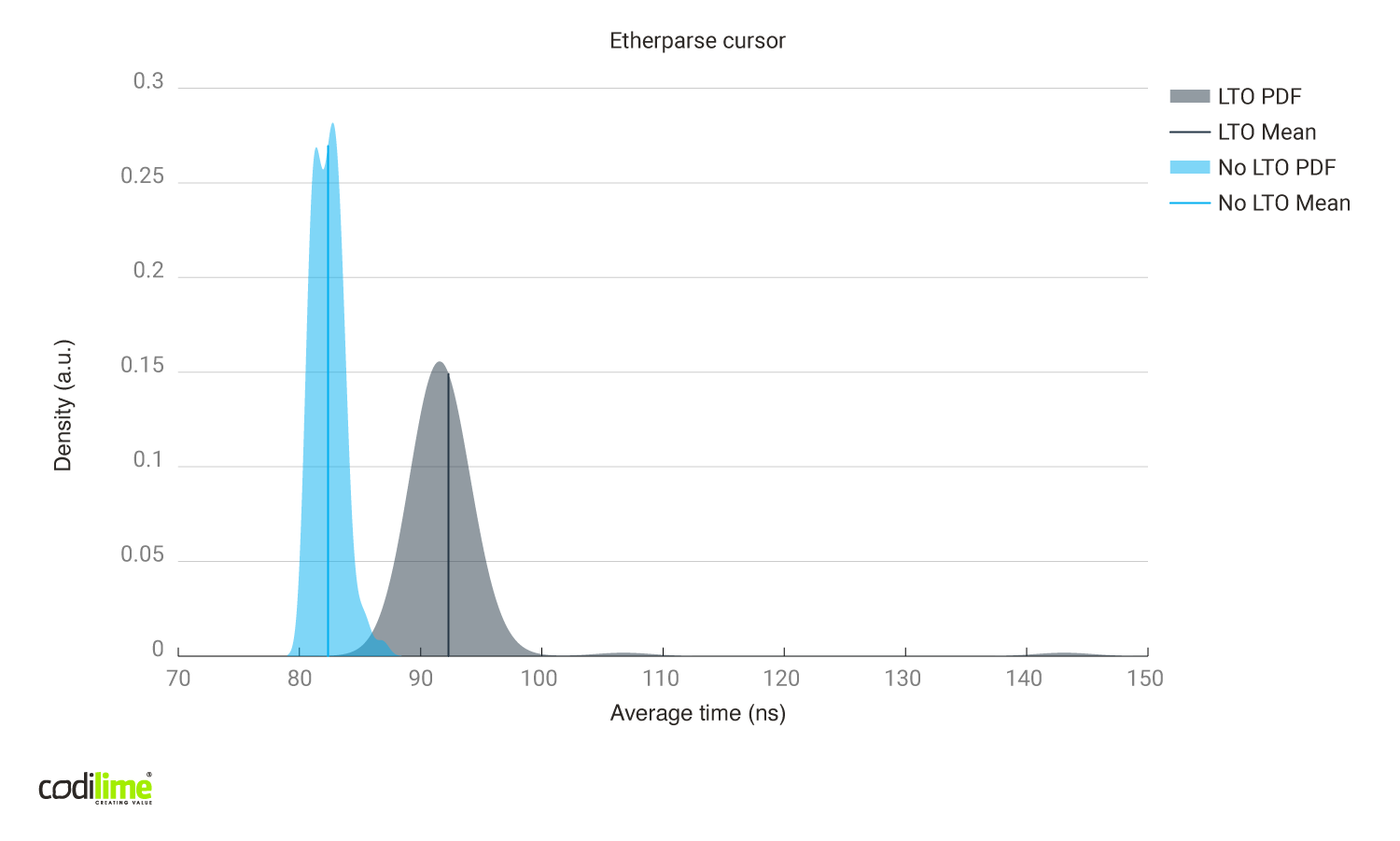
- using the Rust std::io::Cursor, which copies just the memory needed:
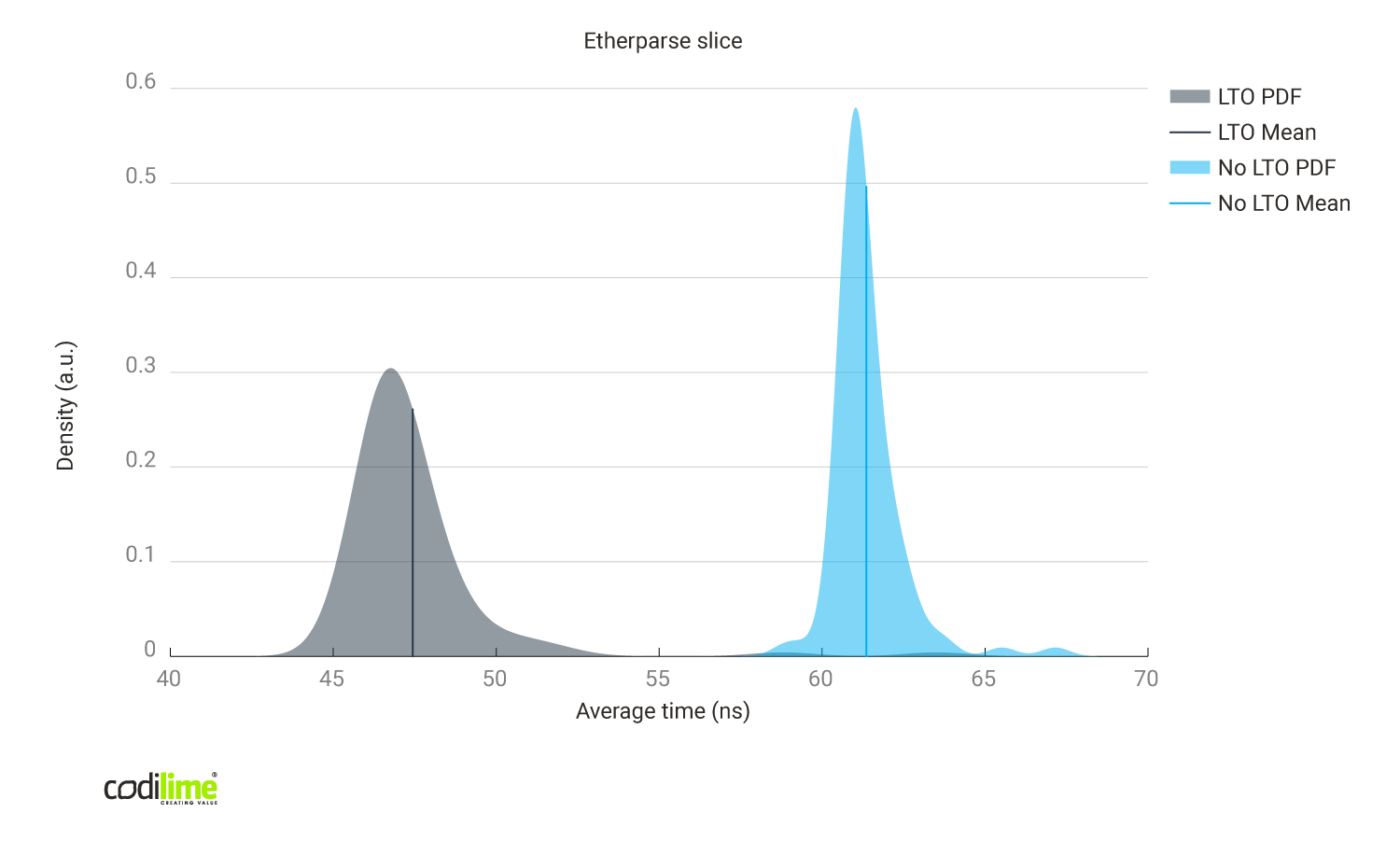
- using pure slices instead of cursors:
We've compared the Assembly instructions generated in all of these cases after link time optimizations:
-
Slice method:
- 465 asm instructions
- contains calls to memcpy, memset, malloc
-
Cursor method:
- 871 asm instructions, almost two times bigger than slice method. This is why the results in benchmarks are worse than in slices
- contains calls to memcpy, memset, malloc
-
Creating a packet from scratch:
- 881 asm instructions
- a lot of memory manipulations
- allocates and frees memory
Pnet library
In pnet ![]() , In-place packet modifications:
, In-place packet modifications:
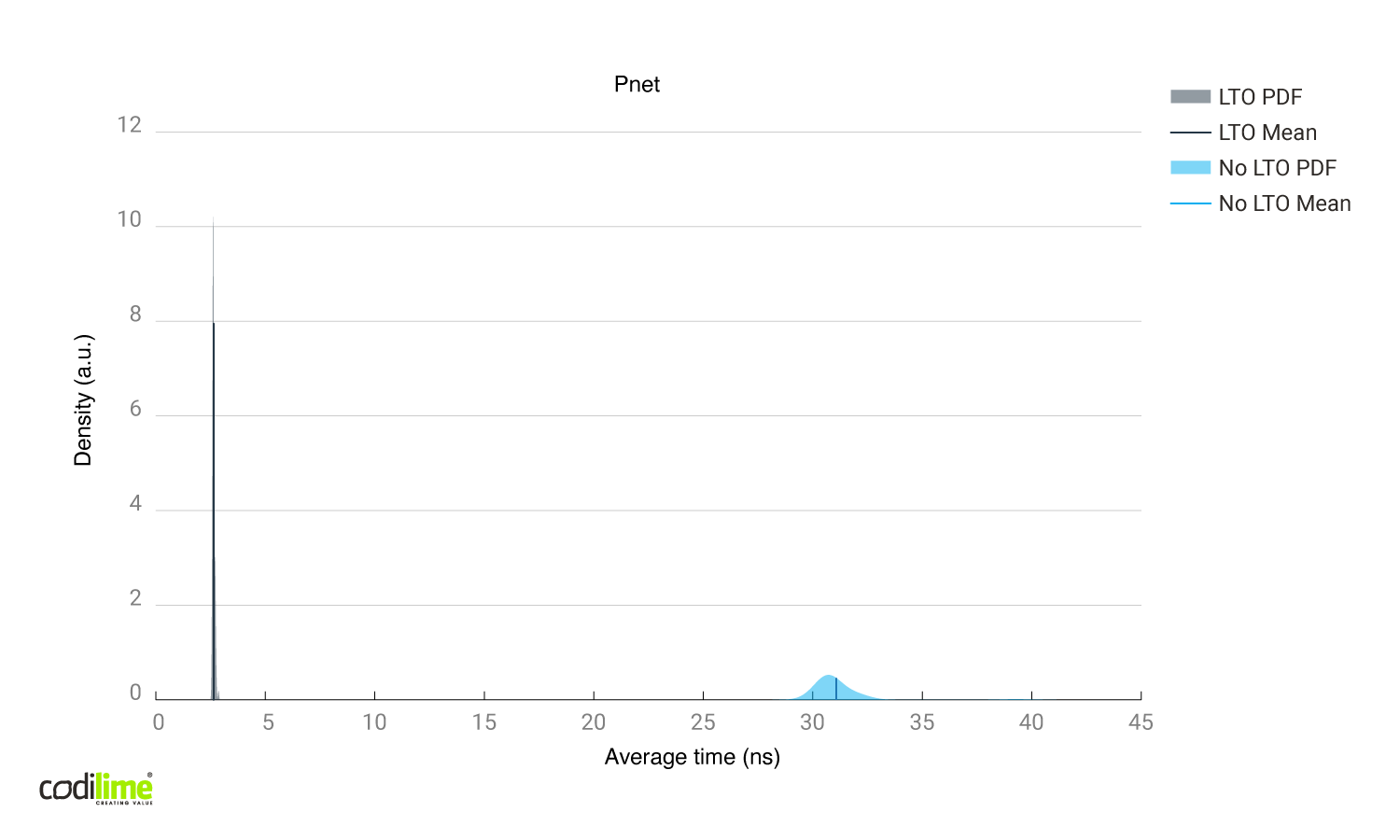
Inspection of the generated Assembly instructions after link time optimizations:
- 19 asm instructions
- 2 branches
The smoltcp library
In smoltcp ![]() , In-place packet modifications:
, In-place packet modifications:
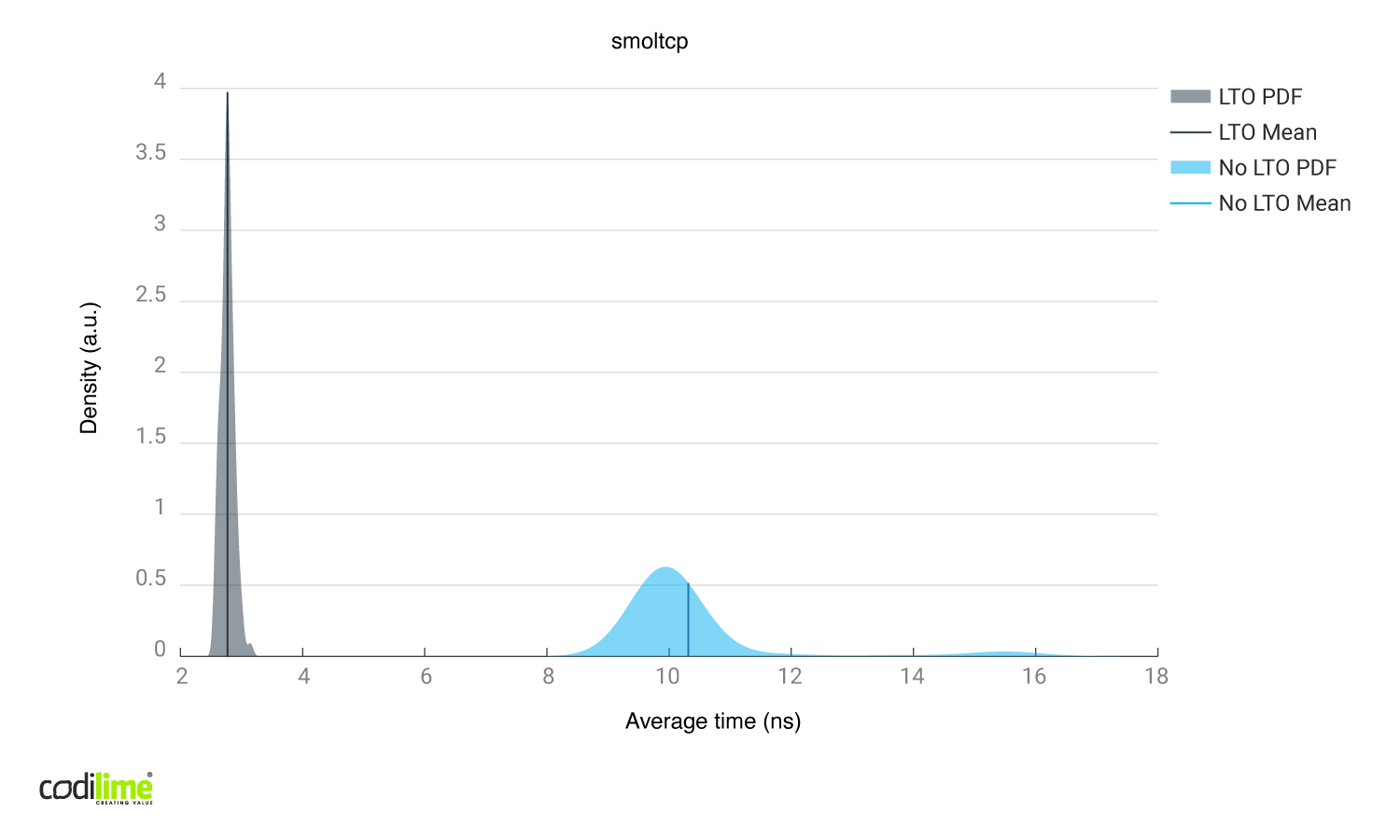
Inspection of the generated Assembly instructions after link time optimizations:
- 27 asm instructions
- 5 branches
Conclusions from the performance results
A comparison of all libraries can be found below:
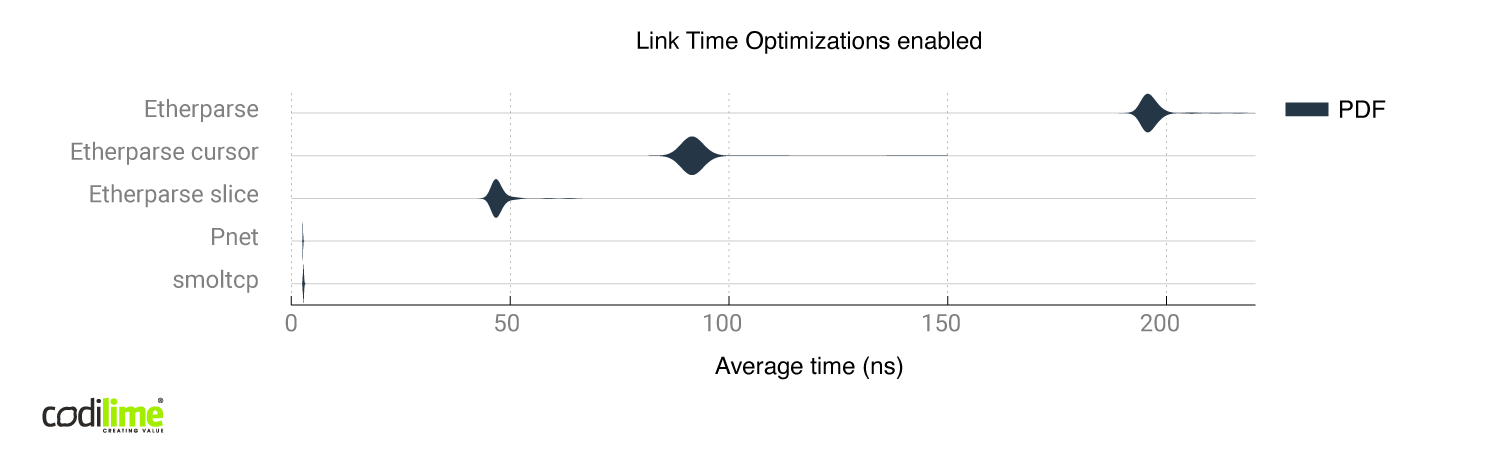
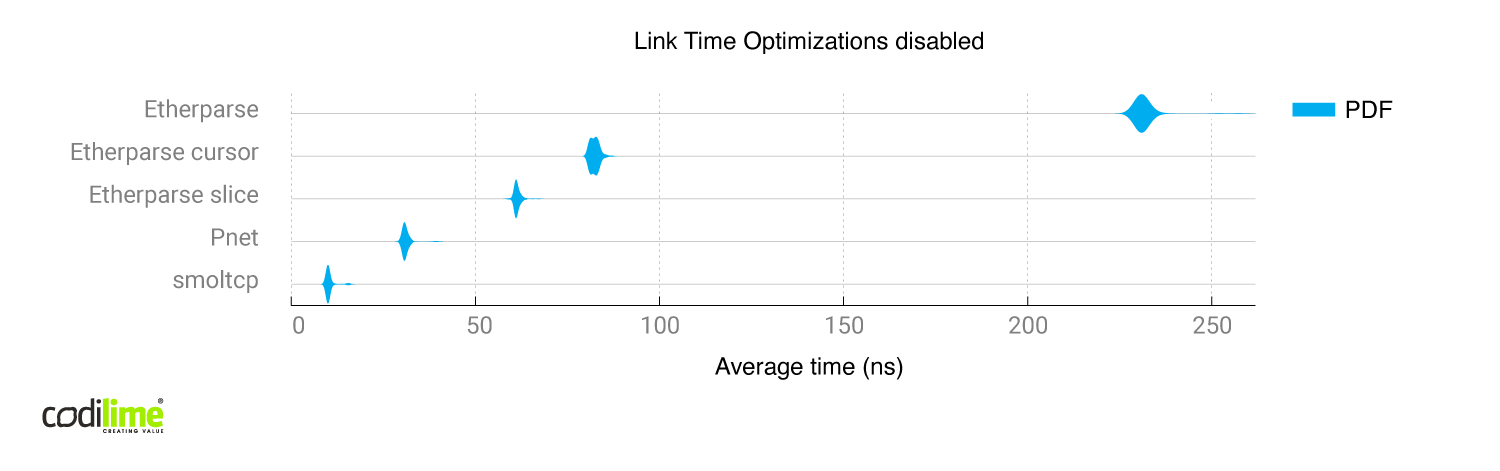
Without link time optimizations, pnet and smoltcp differed greatly even though both modify packets in place. A possible reason is the worse implementation of the pnet library, which was harder for the compiler to optimize. After enabling link time optimizations, both the pnet and smoltcp produced similar time results, though smoltcp generated more assembly instructions and branches than pnet. All of those branches were error checks so the branch predictor didn't have much trouble optimizing it.
Etherparse generates far more Assembly instructions than pnet and smoltcp, and also seems to be better adjusted for building packets from scratch instead of modifying them.
We used smoltcp in the l2fwd implementation because it achieved very good performance with and without link time optimizations.
Final thoughts
Our tests indicate that replacing C with Rust led to some performance degradation. An implementation written in Rust achieved around 85% of the C performance in the overload test, but we still see some space for improvements in the bindings implementation, which could bring us closer to C’s performance. At the cost of this performance loss, on the other hand, we get Rust safety controls, which simplify the creation of safe code. In the case of system programming, such as network applications, that is very valuable.
We also used a quite simple l2fwd, which is why the RFC2544 results were so close. We can’t be sure how Rust would behave in a more demanding scenario. That’s why, in the future, we intend to create a complex application in C and Rust using the bindings we’ve described. This would allow us to perform a more detailed performance comparison.
Language creators learned their lesson and created Rust, a modern alternative to C that fixes many of the problems (e.g. related to memory management and or multi-thread programming) in programming languages. We are thrilled to see it replacing C in some use cases.



