


Large language models are one of the most hyped topics in the industry since their introduction. However, the concept and utilization of LLMs can appear daunting to both beginners and seasoned professionals. This comprehensive guide brings LLMs closer, offering a deep dive into their fundamentals and practical insights into deploying your own LLM.
In this article, we will present the basic setup of an LLM hosted on private infrastructure and provide a deeper understanding and practical application of large language models while keeping a keen eye on performance monitoring for optimal operation.
Basics of Large Language Models
Before we start hosting an LLM, let’s establish a fundamental understanding of the large language model itself. An LLM is a statistical language model built from an extremely large text corpus. The model's job is to predict the continuation of text strings. Typically such strings are prompts provided by the user.
As you may have noticed, the model’s job (or, to rephrase, the problem statement it tries to solve) is relatively vague. Here is the area where the large in “large language model” comes into play, causing the recent hype. Even before LLMs, smaller and more specialized language models were successfully used. For example, the BERT architecture for NLP was in widespread use from 2018-2019. With modern LLMs, the assumption is that the single model is extremely versatile and can solve many problems from the NLP space, including, but not limited to content generation, question answering, instruction following, sentiment analysis and more.
Take note that there is no “black magic” around these models. From a computational standpoint, the model itself is a set of matrices that are used to compute probabilities of subsequent tokens based on a combination of user inputs, embeddings computed from user input, and conversation context. This means that in principle, nothing forbids us from running a large language model in our private infrastructure. Let’s explore this opportunity.
Looking for more information related to this topic? Check out our previous publication about what a large language model is.
LLM open source ecosystem
If you are interested in the LLM space, you have definitely heard about proprietary models. Names like ChatGPT quickly became household names with all the buzz around them.
At the same time, we are not talking today about using proprietary llm-model-as-a-service, we want to manage the model ourselves.
If you want to get your hands on open-source models, you’ll most likely end up at HuggingFace. HuggingFace is an open community built around the ML ecosystem, and it has become the de facto standard in the industry, where a majority of state-of-the-art models can be found.
In addition, OpenLLM Leaderboard is a hub where the most popular models are tracked and evaluated across a variety of benchmarks.
Leveraging open source is essential for modern software engineering. At CodiLime, we combine proprietary and open-source solutions to build business value. We encourage you to check out our platform engineering services.
Selecting a model
Selecting a model is arguably not an easy task. Benchmarks that are used to place models on the OpenLLM leaderboard attempt to evaluate models across a variety of synthetic tests.
While these tests have merit and quantify models in some sense, one has to remember that they are not an absolute metric.
Keep in mind that benchmarks are useful, but they need to be put in the context of your problem instead of being taken purely at face value.
For self-hosted LLMs, benchmarks cannot be the only criteria. One has also take into consideration:
- performance per dollar - a larger model requires more hardware, primarily bounded by GPU memory (more on that later),
- latency - a larger model needs to crunch more numbers to produce results if the model is for use in a latency-sensitive service,
- payload characteristics - if an LLM is supposed to generate answers based primarily on internal knowledge, a larger model is necessary; if the application can inject contextual knowledge as part of the prompt (e.g. based on an internal knowledge base backed by vector database) then smaller models may be sufficient,
- licensing - even if open-sourced, models often impose certain limitations on using certain models in commercial or mission-critical (e.g. medical) contexts.
Later examples are based on Falcon-40B ![]() but general rules will follow for other modes.
but general rules will follow for other modes.

Selecting hardware
To run such a large model, you’ll need some GPU. All of the examples shown later will use AWS as a cloud vendor and NVIDIA as a GPU vendor. For the test setup, I’ve selected g4dn.12xlarge, which was roughly estimated to be able to fit Falcon-40B in terms of memory.
Since you’ll be running some code on the GPU, it’s important to have the relevant drivers installed.
Luckily NVIDIA provides an AMI in AWS which we can use to spawn our EC2 with all the necessary dependencies. These dependencies include some utility tools on top of essential drivers. One of these tools is the Nvidia-smi - a CLI tool from a GPU vendor designed to help manage and monitor your GPU devices.
sh-4.2$ nvidia-smi
Fri Jun 23 09:44:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A10G On | 00000000:00:1B.0 Off | 0 |
| 0% 25C P8 9W / 300W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A10G On | 00000000:00:1C.0 Off | 0 |
| 0% 26C P8 9W / 300W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A10G On | 00000000:00:1D.0 Off | 0 |
| 0% 25C P8 9W / 300W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 |
| 0% 26C P8 9W / 300W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
As we can see in the snippet above, this tool gives us our driver version, and our CUDA version (which is just a library that allows us to leverage GPU for general computing problems).
Here we can see that we have four Nvidia GPUs available on our machine.
They are in an idle state, they consume close to no power, and no memory is allocated.
This is expected, because it’s a freshly spawned instance, without any LLM workload deployed.
Serving a model
Typically, the model documentation on HuggingFace will include sample code that can run inference from a Python script. While this approach is sufficient for data scientists to conduct their experiments, for the POC I went for a different approach and used the TGI or Text Generation Interface. This is another tool in the open source offering from HuggingFace.
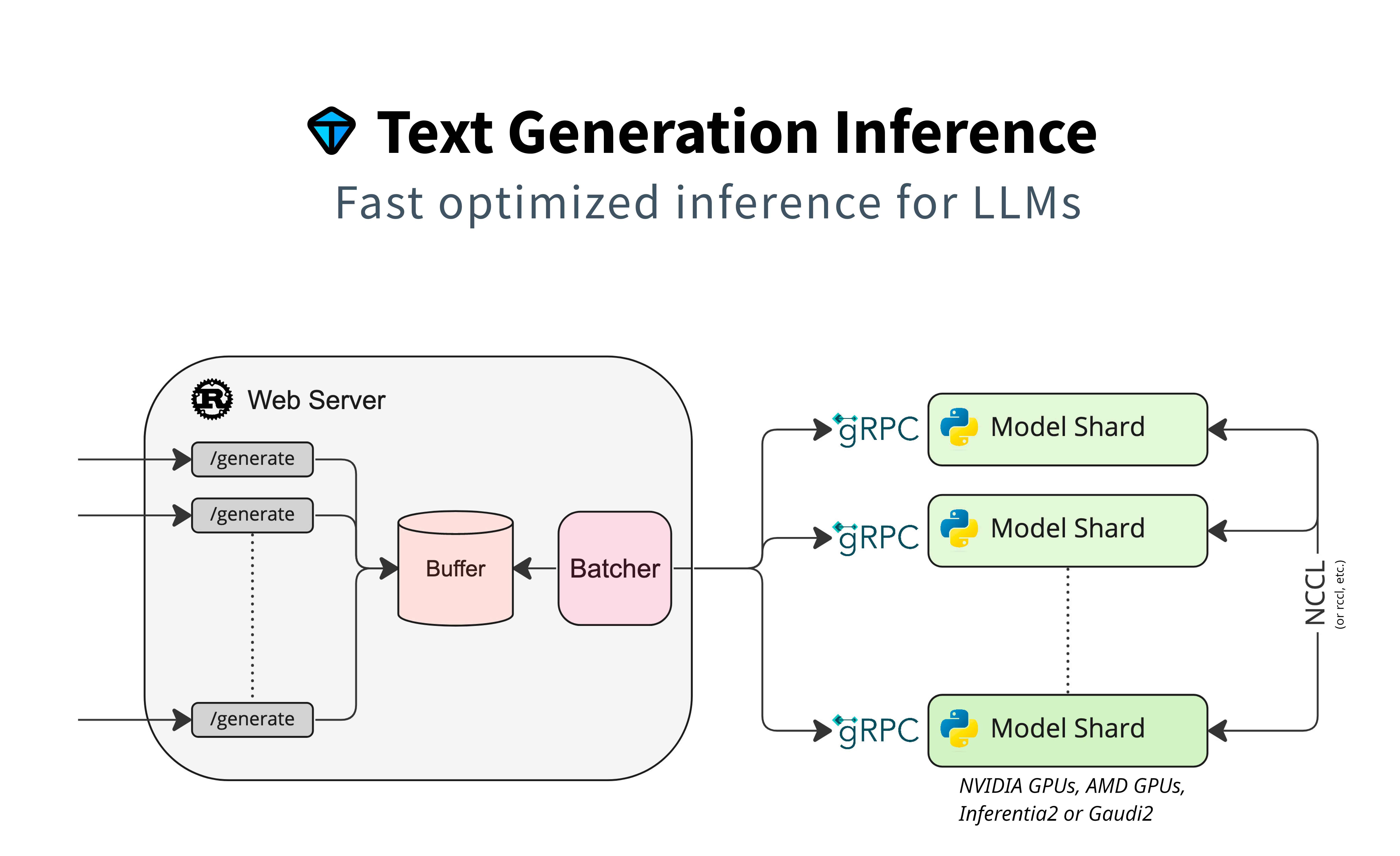
Two primary reasons drove me to this decision:
First of all, I was hoping to get my setup closer to production-grade “LLM as a Service” should our client decide to pursue that avenue.
Second of all, I was hoping to delegate some of the operational complexities to externally maintained software, so I did not have to solve them on my own.
The ultimate goal was to deliver operational deployment as soon as possible.
With TGI, running a model is the same as running any other containerized application.
docker run
-d --rm # detached, remove container on terminate
--gpus all # allow container to use GPUs
--shm-size 1g # shared memory for data sharing between devices via host
-p 8080:80 # expose ports for HTTP API
-v $PWD/data:/data # volume to store data (model weights) between runs
ghcr.io/huggingface/text-generation-inference:0.8.2 # container image
--model-id tiiuae/falcon-40b-instruct # model id, downloaded automatically
--quantize bitsandbytes # quantize weights to 4bits to fit on NV T4 memory
--num-shard 4 # distribute model across 4 GPUs available
- We want to run it as a server process, therefore we detach tty.
- We allow the container to use GPUs because that’s where we want to run computations for inference.
- We use shared host memory to exchange data between GPU devices, as recommended in TGI docs.
- As in any other web service, we expose relevant ports.
- We use a volume to cache model weights in between container restarts.
- We pull an image from the official HuggingFace container registry.
- We provide a model ID to allow TGI to pull it from HuggingFace.
- We shard and quantize the model to fit it to the GPU memory.
In this POC, we use runtime bitsandbytes quantization scheme, but the current TGI version allows you to run ahead-of-time GPT-Q quantization as well.
Once we start our container, the same Nvidia-smi tools give us valuable insights.
ubuntu@ip-10-192-14-231:~$ nvidia-smi
Thu Jun 29 07:18:40 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1B.0 Off | 0 |
| N/A 45C P0 26W / 70W | 12095MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 On | 00000000:00:1C.0 Off | 0 |
| N/A 45C P0 27W / 70W | 12095MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla T4 On | 00000000:00:1D.0 Off | 0 |
| N/A 45C P0 27W / 70W | 12093MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 44C P0 25W / 70W | 12093MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 8677 C /opt/conda/bin/python3.9 12090MiB |
| 1 N/A N/A 8678 C /opt/conda/bin/python3.9 12090MiB |
| 2 N/A N/A 8680 C /opt/conda/bin/python3.9 12088MiB |
| 3 N/A N/A 8679 C /opt/conda/bin/python3.9 12088MiB |
+-----------------------------------------------------------------------------+
First of all, we can see that our configuration was indeed correct. GPU cores are active now. GPU memory is allocated.
It may sound trivial, but during deployment preparation, you may need multiple attempts before the infrastructure is configured correctly, and having such feedback is very beneficial.
We can also see that we used 12GB out of 16GB memory on each core, which means that for this setup we are not overprovisioning our infrastructure.
Last but not least we can precisely see which host processes are using which GPU, which is also important feedback in case you try to run multiple containers on the same host.
Consuming a model
Since it's a containerized web service, this means we can ask the model to predict prompt response by simply issuing a REST API call.
ubuntu@ip-10-192-14-231:~$ curl 127.0.0.1:8080/generate -X POST -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":1000}}' -H 'Content-Type: application/json'
{"generated_text":"\nDeep learning is a subset of machine learning that uses neural networks to learn from large amounts of data. It is a type of artificial intelligence that allows machines to learn and improve from experience without being explicitly programmed. Deep learning algorithms are designed to mimic the structure and function of the human brain, with layers of neurons that process and learn from data. This allows for more complex and accurate predictions and decision-making."}
Production-grade setup
Running a single container on a single machine fulfills the definition of POC, but is far from being considered a production-grade setup. In order to improve the reliability and resiliency of the overall solution, the following improvements can be made:
Load balancer between user requests
By enabling load balancer you can achieve things like high availability setup and seamless failover.
Resilient orchestration, e.g. using Kubernetes
If your infrastructure is already on Kubernetes, you can access the desirable properties such as a consistent deployment model, automated recovery, and more. Device plugins or node selectors can be used to force the allocation of containers onto GPU-enabled nodes.
Telemetry
Experiments show LLMs can hallucinate, provide incorrect information or suboptimal responses, and incur bad retrieval, among many things that can go wrong. It is essential to monitor the performance of our models and the entire business process they are supporting to know at any point in time whether our production works as expected (If you can’t measure it you can’t manage it).
The TGI container can be configured to emit monitoring data to the OTLP connector. Attaching an OTLP endpoint gives us free observability by which we gain insights into the details of our LLM pipeline execution exposed as telemetry data. That can significantly help us identify areas where our LLM might potentially need improvements.
Here, you can find another article about how to use OpenTelemetry for Kubernetes. Moreover, below you can find a video with an in-depth explanation of open-source LLM ecosystems.
Summary
This blog post has sought to establish an understanding of large language models for both newcomers and experts. Starting with LLM basics, it explored the vibrant open-source ecosystem with tools and resources for building, fine-tuning, and leveraging these models.
The core is a detailed guide for deploying your own LLM. It covered crucial steps like choosing the right model architecture and hardware to fit your specific needs; showing how to set up the LLM as a RESTful service and manage requests seamlessly.
Finally, the post highlighted the importance of monitoring LLM performance using OpenTelemetry Protocol, ensuring its effectiveness and reliability in real-world applications.
Overall, this guide empowers you to understand, implement, and monitor LLMs for your projects, whether you're starting from scratch or aiming to optimize existing systems.


