


In the ever-evolving landscape of machine learning and artificial intelligence, the complexity of how data is structured, understood, and utilized plays a pivotal role in the development of technologies. One such aspect is the role of machine learning metadata and its significant influence on content embeddings. This article delves into the depths of metadata, exploring its types, purposes, and the challenges it presents. It explains how metadata acts as the backbone of data management, offering a structured approach to understanding and managing data which, in turn, enhances the efficacy and applicability of machine learning models.
Moreover, I will discuss the realm of content embeddings, a crucial concept in machine learning that transforms complex data into a format that machines can efficiently process. By highlighting the significance of content embeddings in preserving semantic relationships and enhancing machine learning models, the article sets the stage for a comprehensive examination of how metadata enriches these embeddings. Through improving data quality, providing contextual relevance, and enabling feature engineering, metadata is shown to be a crucial element in the development of advanced AI systems.
What is metadata?
Before diving into the significance of metadata in content embeddings, let's first understand what metadata is. Imagine it as a detailed label or summary that provides essential information about data without disclosing the data itself. For example, if we consider a digital photo, its metadata might include details like the photo's size, resolution, location, the date it was taken, and the camera model used. However, it doesn't show the image itself.
Types of metadata
There are generally three types of metadata: descriptive, structural, and administrative. Descriptive metadata is about helping to find and understand data, structural metadata gives information about the design and specification of the data structures, and administrative metadata provides information to help manage a resource.
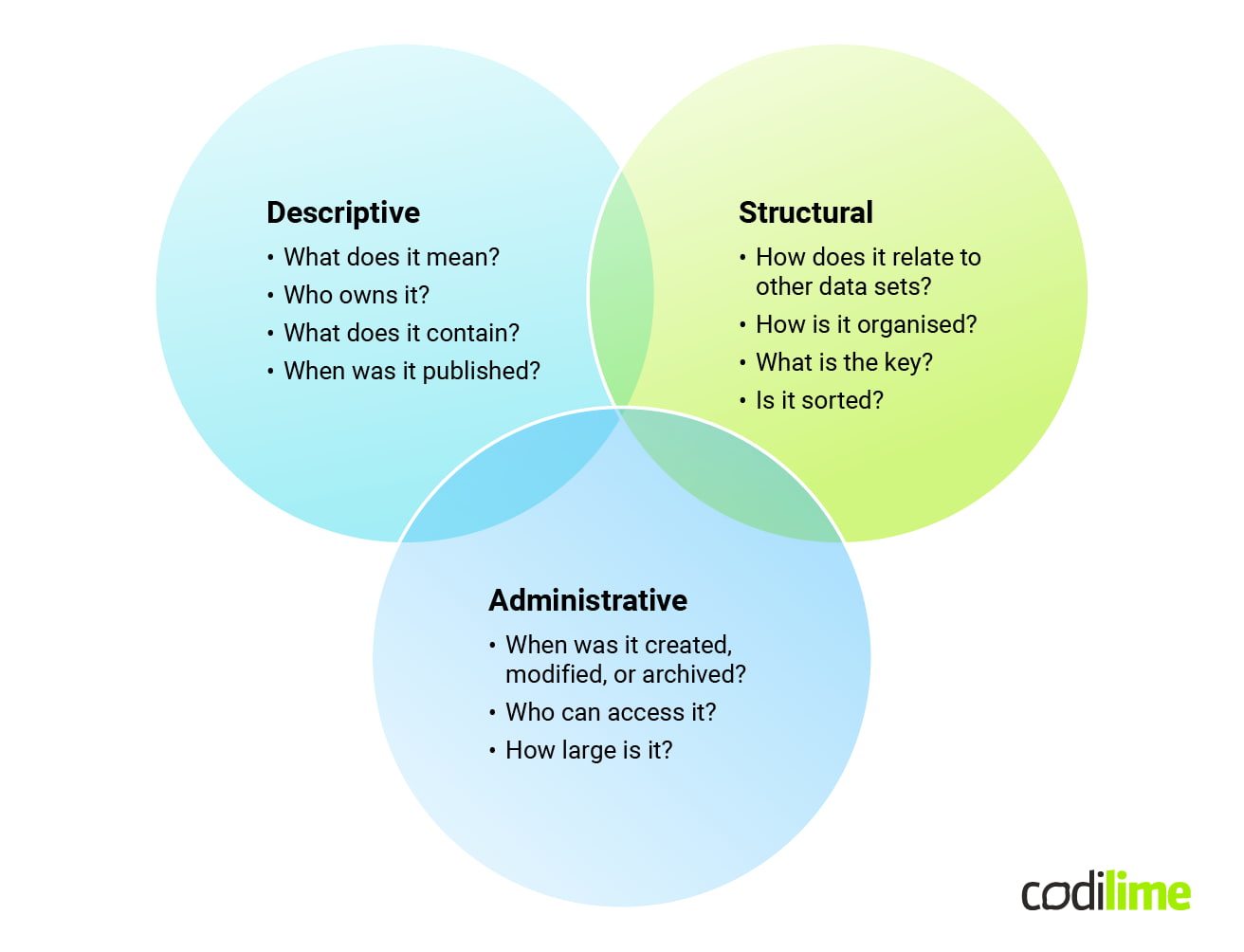
The role of metadata in the digital environment
Metadata is invaluable for a variety of purposes, including organizing data, ensuring compliance with standards and regulations, and managing the data's life cycle. It acts like a behind-the-scenes guide, helping both users and systems to handle data efficiently. This involves knowing the data's origin, how it can be utilized, and how to preserve it over time.
Metadata repository
A system or database that is designed to store and manage such information is often called a metadata repository. This repository plays a critical role in keeping data organized and identifiable, similar to how a library catalog helps in finding books.
Challenges with managing metadata
However, there are challenges associated with metadata. Organizations might struggle to see immediate benefits, leading them to opt for simpler, though less effective, methods like using spreadsheets. Moreover, metadata can become hard to manage when it is stored across different locations and not updated regularly.
However, there are challenges associated with metadata. Organizations might struggle to see immediate benefits, leading them to opt for simpler, though less effective, methods like using spreadsheets. Moreover, metadata can become hard to manage when it is stored across different locations and not updated regularly.
The role of metadata in enhancing web page visibility cannot be overstated. It includes descriptions and keywords related to the page's content, which search engines display in search results. Historically, meta tags played a crucial role in search engine rankings until the late 1990s. However, the advent of search engine optimization (SEO) practices like keyword stuffing led to a decrease in the reliance on meta tags by search engines. Nonetheless, meta tags remain an important element in indexing pages, with search engines continuously adapting their algorithms to ensure relevance and counteract deception.
Metadata creation can be manual or automated. Manual creation allows for more accurate and relevant information input, while automated methods might only capture basic details such as file size, type, creation date, and the creator's identity.
The importance of meta information
In summary, metadata serves as the foundation of data management, ensuring data is not just stored but is meaningful and usable over the long term. It unlocks the full potential of data by providing a structured and comprehensive way to understand and manage it, demonstrating its importance across a wide range of digital content and applications.
Overview of content embeddings
Content embeddings are a fundamental concept in machine learning and data science, serving as a powerful tool for representing complex data in a more manageable and insightful way. At their core, content embeddings are mathematical representations of data, often in a high-dimensional space, that capture the essence of the data's content in a form that computers can understand and process efficiently. This technique transforms text, images, and other types of content into vectors of real numbers, making it easier for algorithms to perform tasks like similarity searches, clustering, and classification.
How do content embeddings work in machine learning?
The significance of content embeddings lies in their ability to preserve the semantic relationships between data points. For example, in the context of natural language processing (NLP), words or phrases that have similar meanings are represented by vectors that are close to each other in the embedding space. This not only enhances the performance of machine learning models by providing them with rich, contextual information but also allows for a more nuanced understanding and processing of natural language.
Usability of content embeddings
Content embeddings are widely used in various applications, from recommending products based on user preferences to powering search engines that understand the intent behind queries. They are crucial for developing sophisticated AI systems that can interpret, categorize, and generate human-like responses or content. By converting complex, unstructured data into a structured, numerical format, content embeddings enable machines to 'learn' from the data, uncover patterns, and make informed decisions or predictions.
Content embeddings are a cornerstone of modern machine learning and data science, enabling the development of more intelligent, responsive, and capable systems. Their ability to capture and utilize the nuanced relationships within data makes them indispensable for advancing the field and applying AI in a wide range of real-world scenarios.

Influence of metadata in enhancing content embeddings
Incorporating metadata into content embeddings significantly elevates the performance and applicability of machine learning models by enriching the data quality and contextual relevance. Metadata, with its detailed information about the data, acts as a catalyst in this process, offering a deeper layer of understanding and interpretation that purely content-based embeddings might miss.
Improving data quality and contextual relevance
Metadata provides additional context that is crucial for improving the accuracy and relevance of content embeddings. By including information such as the source, authorship, creation date, and format of the data, metadata allows embeddings to capture not just the content but the context in which the content exists. This enriched context helps in distinguishing between seemingly similar content pieces that differ significantly in their purpose, audience, or sentiment. For instance, the use of metadata can help a model understand the difference between a professional article and a casual blog post on the same topic, enhancing the accuracy of content categorization and recommendation systems.
Furthermore, metadata improves data quality by adding layers of validation and verification, ensuring that the embeddings are built from well-described, accurate, and relevant data. This is particularly important in applications where precision is critical, such as legal document analysis, medical research, and academic content discovery.
Enhancing ML models with metadata-driven features
Metadata can be ingeniously used to generate more informative features for machine learning models. Features derived from metadata can include categorical data (such as the author's affiliation or the document type), temporal features (such as publication year), or even more complex features (such as the citation network in academic articles). These metadata-based features can be combined with traditional content-based features to create rich, multi-dimensional embeddings that capture a broader spectrum of information.
For example, in a recommendation system for scientific articles, incorporating metadata features like the article's citations, the journal's impact factor, and the authors' h-index can significantly improve the system's ability to recommend relevant and high-quality articles. Similarly, in image recognition tasks, metadata like the location and time the image was taken, or the camera settings, can provide critical context that enhances the model's understanding and classification accuracy.
In summary, the role of metadata in enhancing content embeddings is multifaceted and profound. By improving data quality and contextual relevance, and facilitating better feature engineering, metadata enables the creation of more accurate, relevant, and sophisticated machine learning models. This not only improves the performance of these models but also expands their applicability across a wider range of domains and tasks.
For instance, a practical application of metadata in improving the relevance and accuracy of content embeddings can be seen in the example below:
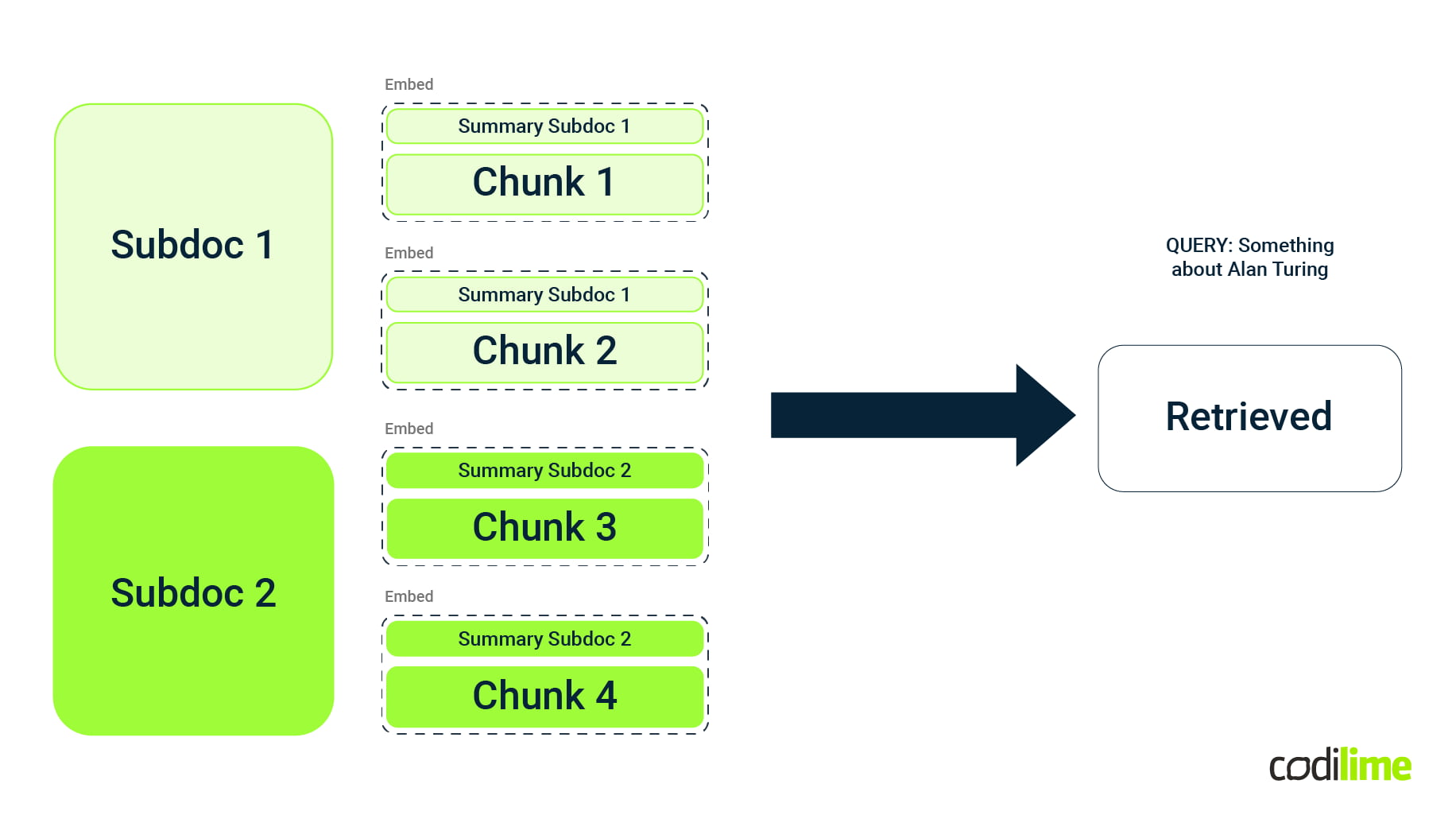
Metadata collection and management
Effective metadata management starts with a robust collection strategy, ensuring that the metadata is comprehensive, accurate, and well-structured. Best practices include:
- Automated metadata extraction
Utilize tools and algorithms capable of automatically extracting metadata from content, such as natural language processing (NLP) for textual data or image recognition technologies for visual data. This reduces manual effort and increases the scale at which metadata can be collected. - Standardization
Apply consistent standards and formats for metadata to facilitate interoperability and data integration across different systems and datasets. This includes adopting widely recognized metadata schemas relevant to your domain. - Quality assurance
Implement processes to regularly review and cleanse metadata, correcting inaccuracies and filling in missing values to maintain its reliability and usefulness.
Designing metadata-aware embedding models
To effectively incorporate metadata into content embeddings, consider the following:
- Hybrid models
Design models that combine traditional embedding techniques with metadata-aware layers or mechanisms. This approach allows the model to learn from both the raw content and its contextual metadata, enriching the embeddings. - Feature fusion
Develop strategies for intelligently merging content features with metadata features. Techniques like concatenation, weighted sum, or more sophisticated neural network architectures can be used to blend different types of information cohesively. - Contextual embeddings
Leverage metadata to produce contextual embeddings that reflect the semantics of the content in its specific context, enhancing the relevance and specificity of the embeddings**.**
Future directions and emerging trends
Recent advancements in AI and machine learning have significantly improved the capability to extract rich metadata from various content types automatically. Techniques such as deep learning-based image analysis and advanced NLP models have become more adept at understanding content at a granular level, facilitating the extraction of detailed metadata that was previously challenging to capture.
The role of AI and machine learning in metadata
The future of metadata in content embeddings is increasingly intertwined with AI and machine learning innovations. Emerging trends include:
- Automated metadata generation and refinement
AI models that can automatically generate and refine metadata, improving over time through feedback loops and continuous learning. - Semantic analysis and enrichment
Advanced AI techniques can perform deep semantic analysis of content to extract more nuanced and contextually relevant metadata, further enriching the embeddings.
Conclusion
In the rapidly evolving domain of data science and machine learning, metadata emerges not just as a supporting actor but as a pivotal force that enriches content embeddings and, by extension, the intelligence and efficacy of machine learning models. This article has underscored the multifaceted role of metadata in enhancing data quality, contextualizing content, and enabling sophisticated feature engineering, which together bolster the performance of AI systems across various applications.
Key takeaways in using metadata in content embeddings
- Enhances data quality and context
Metadata provides essential context that allows for a more nuanced understanding and processing of content, leading to more accurate and relevant machine learning models. - Facilitates advanced feature engineering
Metadata-driven features introduce a new dimension of information, enabling models to capture a broader spectrum of data insights. - Future-proofing with AI
Advancements in AI and machine learning are set to further revolutionize how metadata is generated, processed, and utilized, making it an area ripe for innovation and exploration.
Discover how to fully leverage your data with our comprehensive data services.
In conclusion, metadata is not just a backdrop to the data we seek to understand but a critical layer of intelligence that amplifies the value and utility of our analyses and machine learning endeavors. Embracing the strategic importance of metadata will be a key differentiator for those looking to advance the frontier of data science and artificial intelligence, ensuring that their work is not only relevant today but remains at the cutting edge of tomorrow's innovations.


