


The Vector Packet Processor (VPP) is a high-performance packet-processing stack that can run on commodity CPUs. In this article, I will take a closer look at what distinguishes this technology from others and how helpful it can be in meeting the demand for efficient network solutions.
The standard approach to packet processing
Regardless of the specific hardware or software implementation at the dataplane level, packet processing can be generally described as a sequence of operations that are performed on packets. This can be represented as a graph in which each vertex corresponds to an operation.
To understand the idea of vector packet processing, compare it with standard (scalar) processing—that is, where each packet is processed separately. For this purpose, we will use an illustrative example (see Figure 1 below). Imagine a very simple packet processing graph with only three vertices, with each representing an action performed on a different type of protocol header.
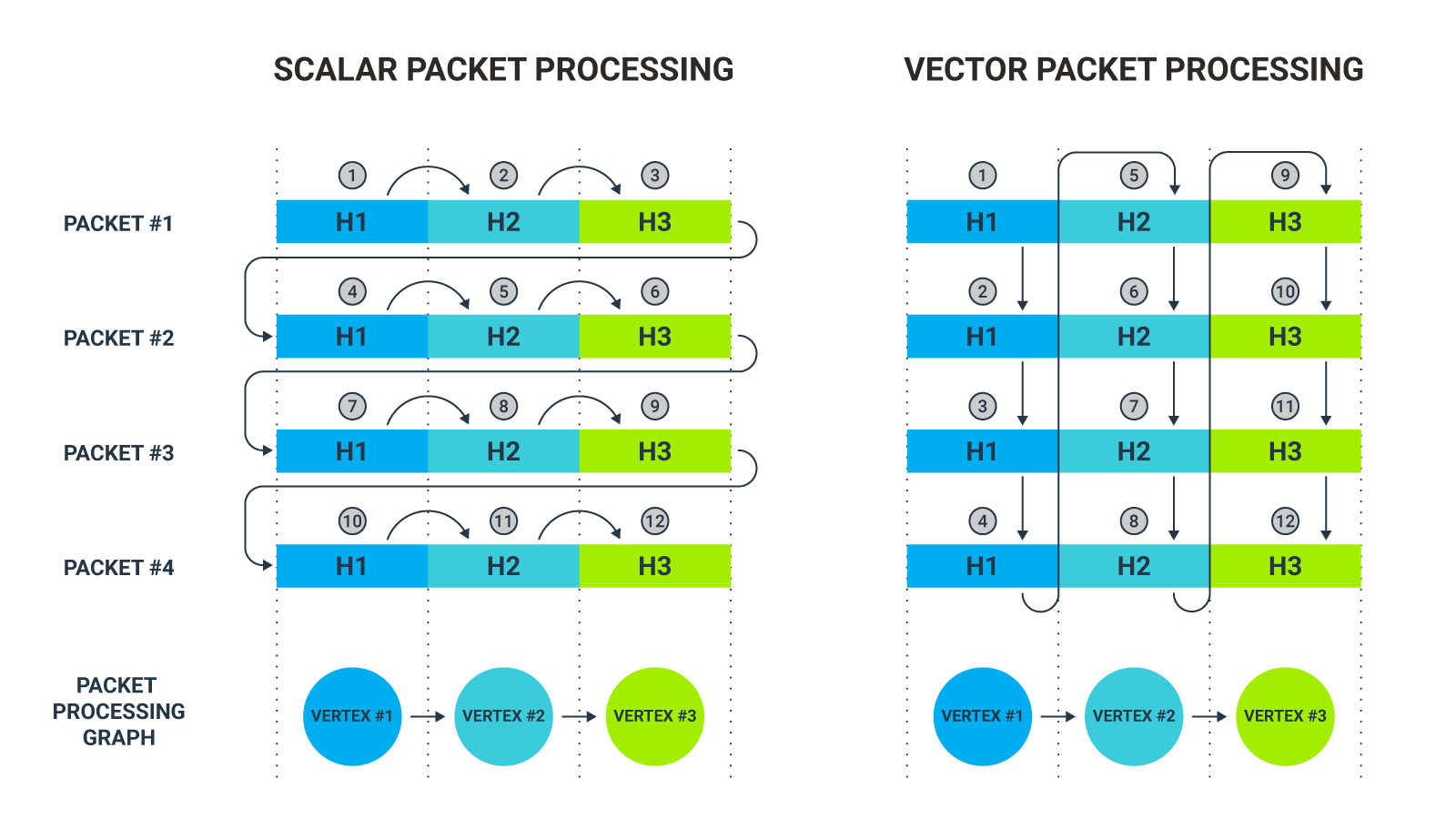
First, let's take a look at what the standard approach to packet processing will look like. When the first packet enters the dataplane, it will be processed through the entire graph, according to the established order. First, vertex #1 specific operations will be performed on the packet. Once completed, the actions appropriate to vertex #2 will be applied. Finally, the packet will be subjected to operations defined in the final vertex, #3, thus completing the processing. In each vertex, some specific operation will be performed on another header in the packet. All these steps will then be repeated for the second packet and then for all subsequent packets.
Here, you can check how our network professional services can help with making your business future-proof.
What is vector packet processing
Vector processing is completely different, as each packet is not processed separately. Instead, a certain group of packets is processed at the same time. This group is called a vector and is processed as follows. The whole vector of packets is processed according to what has been defined in vertex #1. After that, vertex #2 specific operations are applied, followed by operations from vertex #3.
At first glance, it may seem not to matter if each packet is processed separately but completely, or if several packets are handled in bulk but in stages. However, the technical details related to the packet processing mechanism quickly reveal that how it is done is of crucial importance.
When a processing unit starts to do its job, it always needs two things—instructions defining what and how it must be done, and, second, the data on which these instructions are to be executed. In our case, the data is packet headers, while the instructions are operations defined in the vertices of our processing graph that should be performed on these headers. Both data and instructions are initially located in main memory. From there they are taken to the so-called cache memory (we distinguish here data cache and instruction cache) and then used by the processing unit.

The problem is that taking anything from the main memory consumes time—lots of it. To streamline the processing, the most optimal means should be chosen. With vector packet processing, one instruction is kept in the instruction cache for a while and applied to several packets. With scalar packet processing, instructions in the instruction cache are constantly replaced by new ones—they need to be taken from the main memory much more often, which degrades efficiency of the overall packet processing.
To better visualize this, consider a simple example from another area of life. Imagine that we have a fairly large pile of boards in front of us. In each of them, three holes of different diameter should be drilled. How should this be done? Well, we can take the first board, make the first hole in it, then change the drill bit, drill the second hole with it, then change the drill bit again and make a third hole. And then we can repeat this procedure for all of the other boards.
But such an approach forces us to frequently change our drill bits, costing us time. The wiser approach would be to first drill a hole of the same diameter in all the boards one after another, then change the bit and drill a hole of that diameter in all boards one after the other, and then repeat the process for the last time.
VPP & FD.io
The open source VPP platform is based on Cisco's proven VPP technology and is part of the Fast Data Project (FD.io) ![]() , a Linux Foundation Networking (LFN)
, a Linux Foundation Networking (LFN) ![]() projects. The key characteristics of the VPP framework are the following:
projects. The key characteristics of the VPP framework are the following:
-
runs as a standard Linux user-space process
-
can be deployed on bare metal, VM or container
-
supports multiple processor architectures (x86/64, ARM-AArch64)
-
is a modular platform built on a packet processing graph, an abstraction of how a VPP processing pipeline is organized:
- vertices in the graph are small and loosely coupled, making it relatively easy to add new vertices or rewire existing ones
- external plugins are supported (shared libraries loaded at runtime) that can introduce new graph vertices or rearrange the packet processing graph
- a single vector of packets processed through the graph typically contains up to 256 packets
-
provides a variety of interfaces including those optimized for different scenarios such as container-to-container connectivity (“memif” interface) or VM-to-VM connectivity (“vhost-user” interface), etc.
-
can use DPDK technology to connect to physical NICs
-
offers built-in tracing capabilities for various types of interfaces
-
has its own test suite (functional and performance testing), which is implemented through an associated project called Continuous System Integration and Testing (CSIT)

-
can be configured via CLI-based utilities offered out-of-the-box (e.g. vppctl, vat)
-
offers multi-language API bindings
The VPP network feature set is quite rich today and includes support for a number of mechanisms and protocols, including L2/L3 forwarding, LLDP, LACP, ARP, IGMP, VRFs, VRRP, MPLS, Segment Routing, ACL-based forwarding, ACL, NAT, Load Balancing, DHCP, IPinIP, L2TP, GRE, VXLAN, PPPoE, IPSec, Wireguard, TLS, IPFIX. The complete VPP feature list with details on the implementation status of each network functionality is available here ![]() .
.
Where is VPP used?
Today, there are at least a few fairly significant projects, areas and solutions based on VPP. Here’s a look at some of them.
-
Ligato
Ligato ![]() is an open-source Golang framework for developing Cloud Native Network Functions (CNFs). In particular, it provides a whole set of tools for building software agents that allow you to control and manage CNFs. One of the key components of the Ligato platform is the VPP agent that configures and monitors a VPP data plane. It provides a collection of plugins, each of which is used to program a different network feature offered by VPP.
is an open-source Golang framework for developing Cloud Native Network Functions (CNFs). In particular, it provides a whole set of tools for building software agents that allow you to control and manage CNFs. One of the key components of the Ligato platform is the VPP agent that configures and monitors a VPP data plane. It provides a collection of plugins, each of which is used to program a different network feature offered by VPP.
-
Container Network Interface (CNI) solutions
“A Cloud Native Computing Foundation ![]() project, CNI
project, CNI ![]() consists of a specification and libraries for writing plugins to configure network interfaces in Linux containers, along with a number of supported plugins. CNI concerns itself only with network connectivity of containers and removing allocated resources when the container is deleted.” In practice, this kind of interface is commonly used in various kinds of container engines and container orchestration tools. The flagship example here will be Kubernetes. Today, there is a wide range of plugins that conform to the CNI specification. Some of them use VPP technology. This applies, for example, to Contiv-VPP
consists of a specification and libraries for writing plugins to configure network interfaces in Linux containers, along with a number of supported plugins. CNI concerns itself only with network connectivity of containers and removing allocated resources when the container is deleted.” In practice, this kind of interface is commonly used in various kinds of container engines and container orchestration tools. The flagship example here will be Kubernetes. Today, there is a wide range of plugins that conform to the CNI specification. Some of them use VPP technology. This applies, for example, to Contiv-VPP ![]() or Calico/VPP
or Calico/VPP ![]() .
.
-
Network Service Mesh
Network Service Mesh (NSM) ![]() is a kind of system that allows you to handle complex L2 / L3 use cases in Kubernetes. The NSM network is completely orthogonal to the standard CNI interfaces. In practice, NSM enables the creation of dedicated interfaces for direct connections between containers or with external endpoints. One of the functional components of the NSM system is the NSM dataplane, which provides forwarding mechanisms for the implementation of connections between containers. It can be based on kernel networking or a vswitch. One option is to use the VPP here.
is a kind of system that allows you to handle complex L2 / L3 use cases in Kubernetes. The NSM network is completely orthogonal to the standard CNI interfaces. In practice, NSM enables the creation of dedicated interfaces for direct connections between containers or with external endpoints. One of the functional components of the NSM system is the NSM dataplane, which provides forwarding mechanisms for the implementation of connections between containers. It can be based on kernel networking or a vswitch. One option is to use the VPP here.
-
TNSR
As described at https://www.netgate.com ![]() , TNSR is a “high-performance software router based on Vector Packet Processing. Developed, tested, commercially-packaged and supported by Netgate.” The solution can be deployed on dedicated hardware (Netgate security gateway device with pre-installed TNSR software), bare-metal and virtual machines. It is also available as a product in AWS and Azure.
, TNSR is a “high-performance software router based on Vector Packet Processing. Developed, tested, commercially-packaged and supported by Netgate.” The solution can be deployed on dedicated hardware (Netgate security gateway device with pre-installed TNSR software), bare-metal and virtual machines. It is also available as a product in AWS and Azure.
How to start?
For those who would like to take the first few steps with VPP a good option is to go through the official tutorial ![]() . It contains some useful tips on how to install VPP and perform basic operations using the vppctl utility. For example, it shows how to configure the appropriate interfaces on the VPP in order to be able to communicate with the host system or with the second VPP instance. The tutorial also includes simple L3 (routing) and L2 (bridge domains) configurations. To learn more about the VPP architecture and the capabilities it offers, the official documentation
. It contains some useful tips on how to install VPP and perform basic operations using the vppctl utility. For example, it shows how to configure the appropriate interfaces on the VPP in order to be able to communicate with the host system or with the second VPP instance. The tutorial also includes simple L3 (routing) and L2 (bridge domains) configurations. To learn more about the VPP architecture and the capabilities it offers, the official documentation ![]() and VPP Wiki
and VPP Wiki ![]() are worth a look.
are worth a look.
Summary
In the era of deployments based on NFV and cloud-native paradigms, any solution that offers not only the required functionality but also performance is certainly worth some attention. As VPP meets this condition, it’s likely to become a key component of many solutions and products addressed to the network and cloud markets.


