


In computer networks, with the development of new methods, some specific and well-known problems, at first small and manageable, in time grow and become much more difficult to solve. Then they require smarter algorithms, better hardware and a lot of computing power. Access Control List (ACL) processing is a great example of this.
What is the issue with ACL?
This problem has been well known in computer networks for several decades. Typically, ACLs were relatively small - a few dozen entries max - and were used for simple network traffic filtering. However, over time ACLs started to be used in other places**, such as SDNs or DDoS attack mitigations** (e.g. as a part of the BGP Flowspec method). Access Control Lists with several thousand entries began to appear much more frequently. Because of that, algorithms needed much more computing power to cope with the growing demand.

Alternatively, better algorithms could be implemented to solve the problem with the same hardware more efficiently. It turned out that it was possible to create algorithms that don't need to process ACLs from start to finish but can do it smarter.
>>You can read more about ACL processing algorithms here.
Despite improved algorithms, the required amount of computation for larger lists was still very high. For example, for ACLs having 10k elements, the best algorithms could process no more than 1.5 MPPS of traffic using one CPU core. This means that processing 100 MPPS (which is not unattainable these days, especially in large data centers) would require more than 65 CPU cores. These cores must be allocated for traffic filtering and, for example, when used in the cloud, cannot be allocated to customers’ VMs, which means high infrastructure costs.
This begs the question: can something be done about this without losing CPU power?
One possibility is offloading computation to external devices, preferably ones that provide more computing power than the CPU, at a lower cost. Typically, in this scenario, you can use SmartNICs, which provide the services of typical network cards, but can also perform additional operations, such as ACL processing.
An alternative to SmartNICs that has recently been gaining popularity is the use of GPU cards.
GPUs offer very high computing power at the expense of some limitations in the code being executed. In many cases, these limitations prevent the effective use of the GPU to solve a problem, but in the case of network problems, it turns out that these limitations are usually not that significant.
>>You can read more about GPUs and various ways to speed up traffic processing in computer networks in this blog.
Our R&D team implemented an application that offloads ACL processing to a GPU. In this blog post, we will present the results, comparing the traffic processing efficiency of our application to that of the VPP application using an ACL plugin ![]() .
.
Tests description
The environment used for tests
All tests were performed on a single server with an Intel Xeon Silver 4110 CPU (8 physical cores, 16 threads), Nvidia Quadro RTX 4000 GPU, and two Intel XXV710 NICs with two 25Gb interfaces each. The first interface of the first NIC was connected to the first interface of the second NIC, and the second interface of the first NIC was connected to the second interface of the second NIC. This allowed us to perform performance tests by using one NIC to send generated traffic on one interface and receive filtered traffic on the other.
Tested systems
We tested the following applications providing ACL processing features:
-
VPP using an ACL plugin (which uses the Tuple Merge (TM) algorithm for ACL processing),
-
Our implementation of the filtering application (later called “myapp”) in several variants:
a. GPU implementation of the Tuple Space Search (TSS) algorithm,
b. GPU implementation of a naive algorithm (find the first matching rule by checking consecutive rules in ACL),
c. CPU implementation of a TM algorithm,
d. CPU implementation of a naive algorithm.
What needs to be mentioned is that VPP, besides ACL processing, needed to carry out routing – checking the routing table and modifying packet MAC addresses – while myapp performed ACL processing only. This will mostly affect results for smaller ACLs. In the case of bigger ACLs, routing overhead should be negligible compared to the time needed to perform filtering.
Test scenarios
Test scenarios can be divided into two categories:
- Tests of the ACL module itself. Here, all packets are generated inside the testing application and are placed in the appropriate memory (GPU or CPU depending on the tested algorithm) before the test starts. The application only counts the number of classified packets without actually forwarding or dropping them. These tests check how many packets theoretically can be processed by the algorithm without delays, caused by receiving packets, transferring them to GPU, etc.
- Tests of the whole application. Here, packets are generated by the TRex traffic generator and sent to the application where they are filtered based on the provided ACL and dropped or sent back to TRex. These tests check how the ACL module performs in a fully-fledged application that receives packets from a NIC and processes them. These tests show results that can be achieved in practice.
Tests for the first scenario were done only for myapp – running them for VPP would require separating the algorithm from the rest of the VPP, which we did not undertake.
In each test, we were looking for the highest rate that didn’t cause any drops.
Generating test rules
Algorithms that solve the general ACL processing problem optimally aren’t fast enough to be used in practical applications. But one can make some observations regarding the rule sets used in computer networks and design an algorithm based on these observations. This is what happened with Tuple Space Search and Tuple Merge – it turned out that the rules usually have some structure that can be used to create fast algorithms. Therefore, the rules used for testing had to have an appropriate structure.
>> If you want to read more about this you can check out our blog post about ACL processing algorithms here.
Test results
ACL module tests
Batch size
Batch sizes represent the number of packets that are processed by the algorithm simultaneously. This can positively affect the performance because of better instruction cache utilization and less work needed to coordinate and schedule the same number of packets.
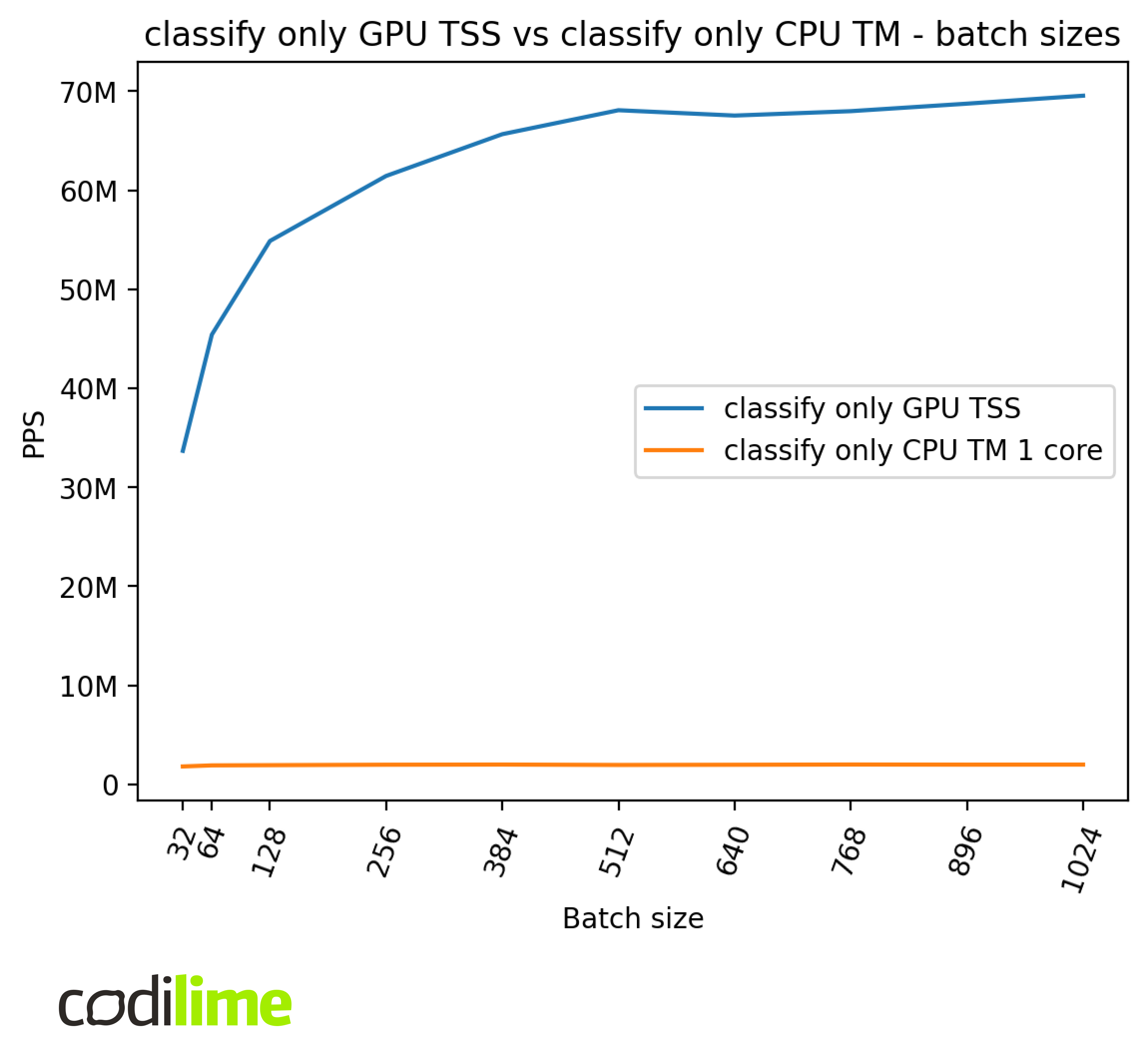
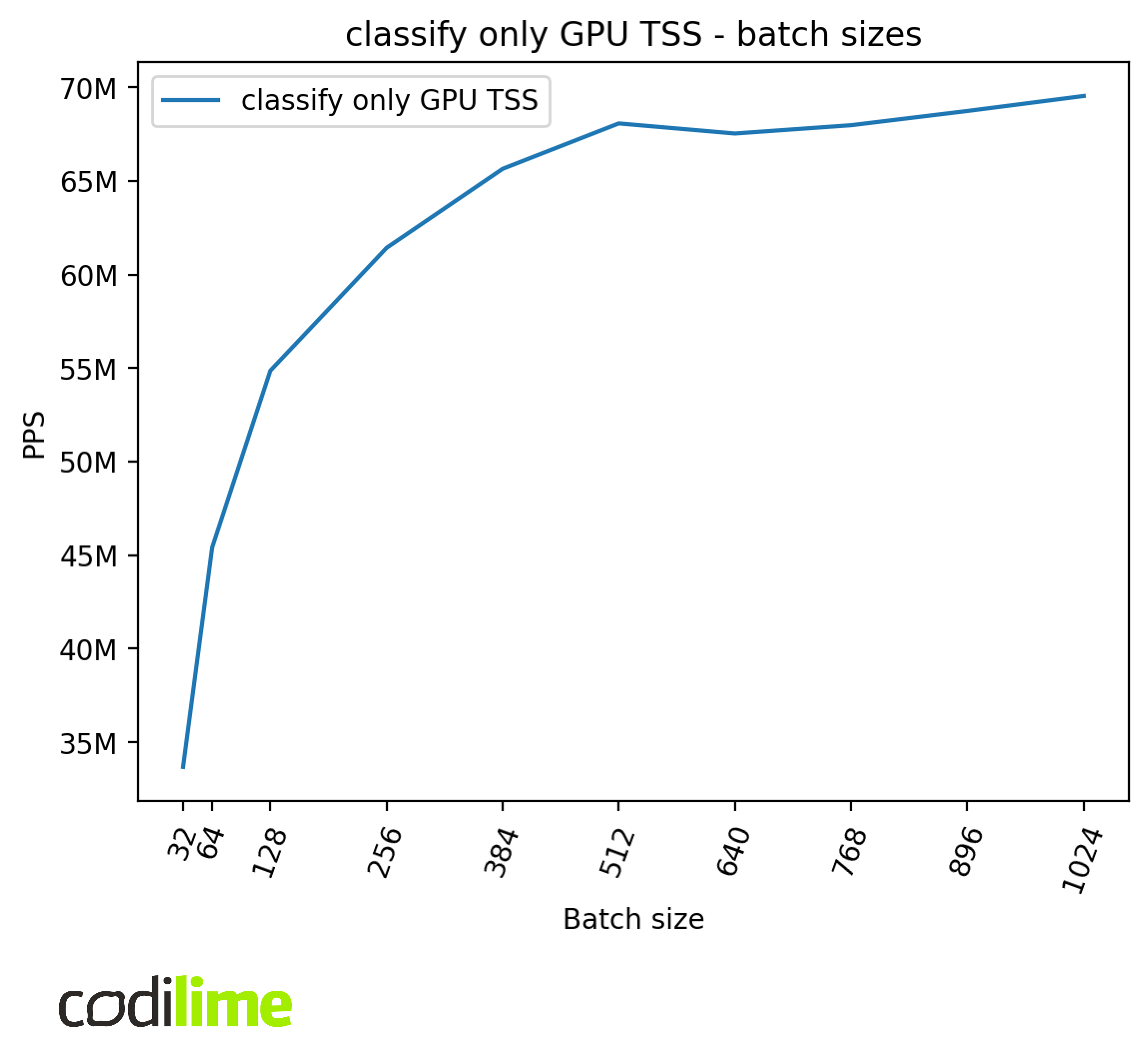
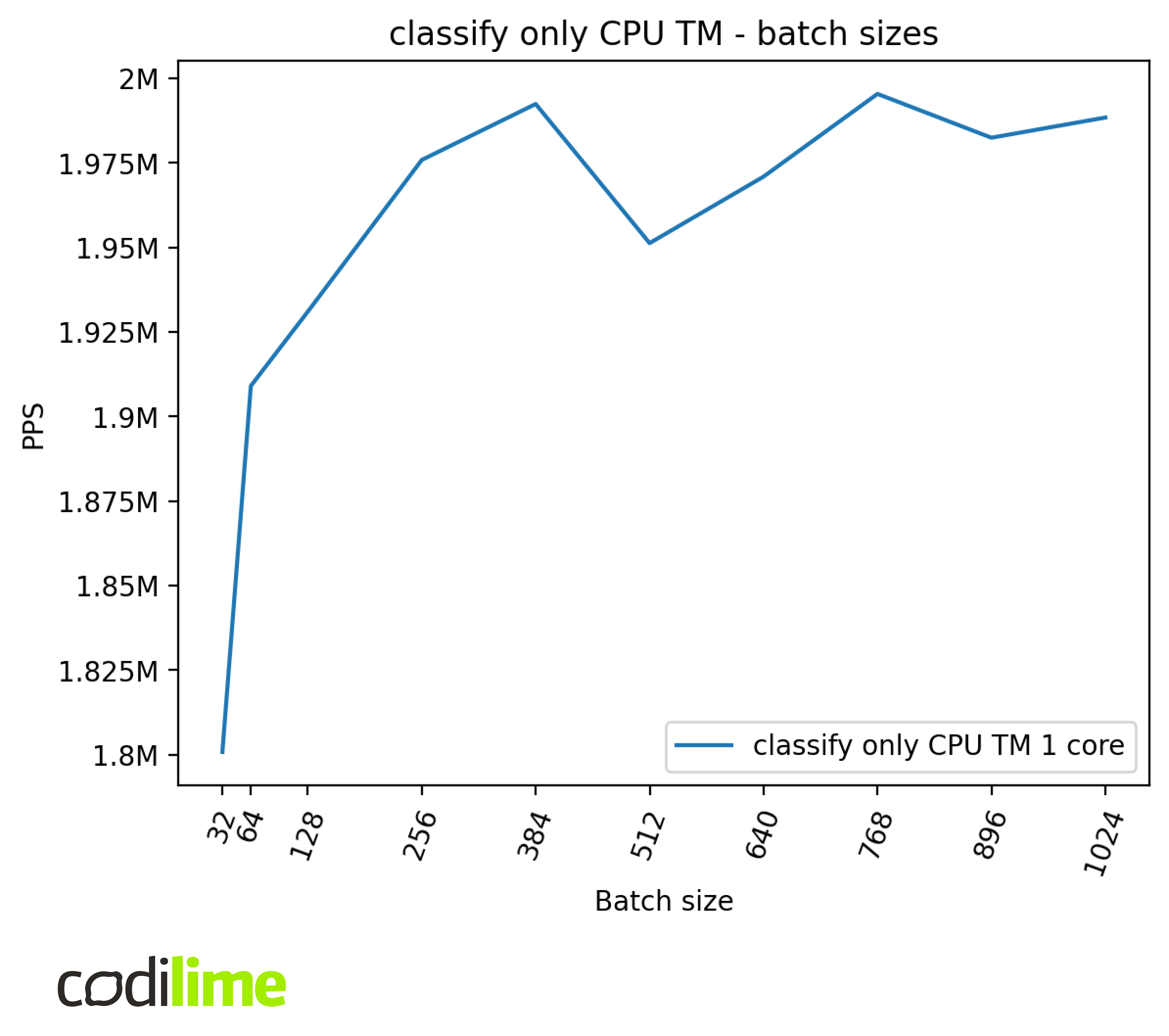
We can see that batch sizes affect the performance, but much more so in the case of the GPU compared to the CPU. We can also see some irregularities for different batch sizes which require further investigation but are out of the scope of this article.
One thing that also needs mentioning here is the fact that larger batch sizes can increase latency – instead of sending a processed packet immediately, we need to first process all the other packets in the batch. Therefore, in a real application, batch size should be dependent on the expected traffic throughput to avoid high latencies when the traffic is low.
The impact of the batch size on latency is presented below in two plots – one with a normal scale and one with a log scale. The traffic rate used to gather latency results is different for each batch size and is equal to the maximum throughput achieved with the given batch size, e.g. for 256 it is set to ~61 MPPS and for 1024 to ~70 MPPS for GPU.


Full application tests
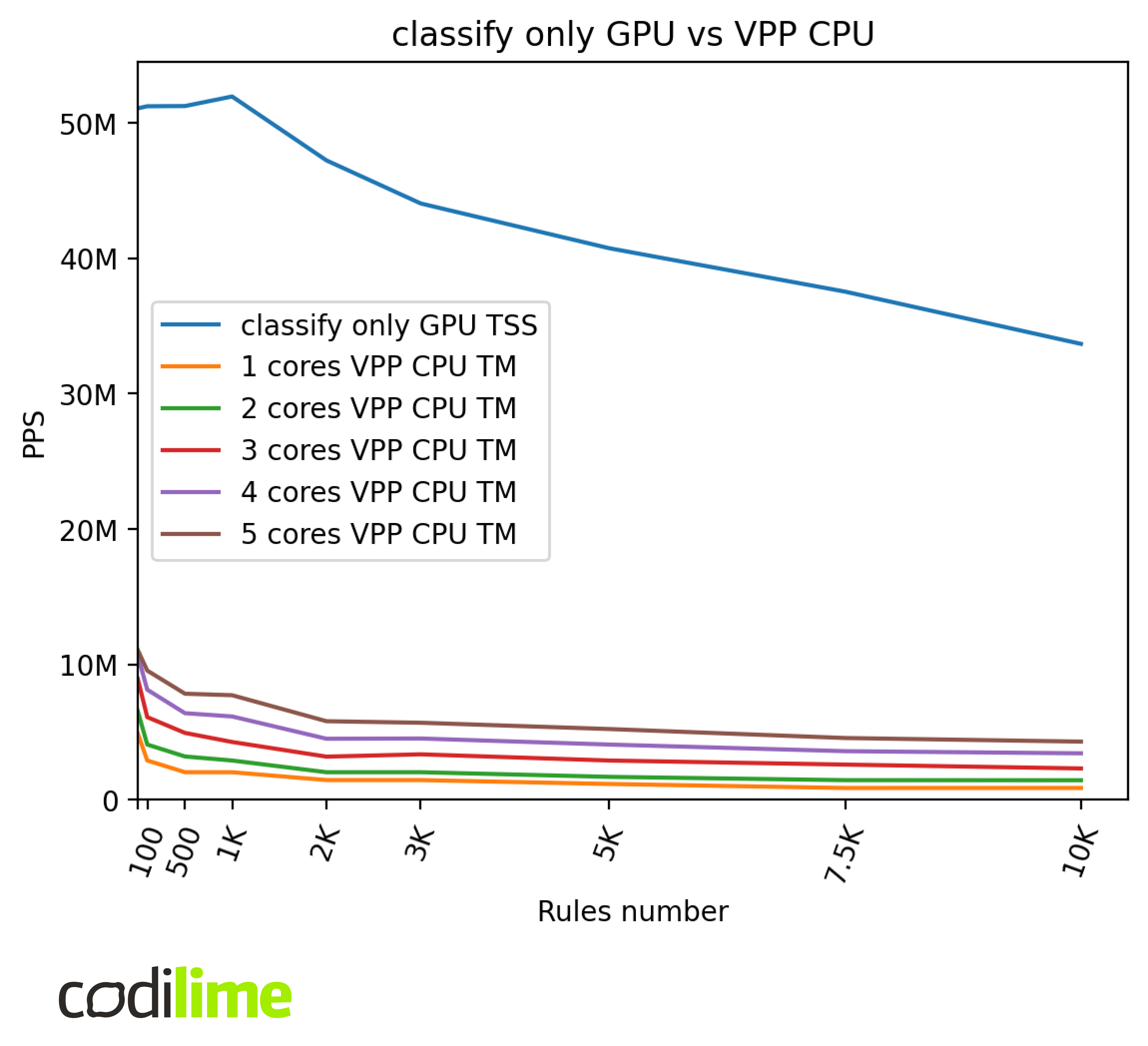
myapp GPU vs. classify-only GPU
In this comparison, we want to compare practical performance results against theoretical ones.
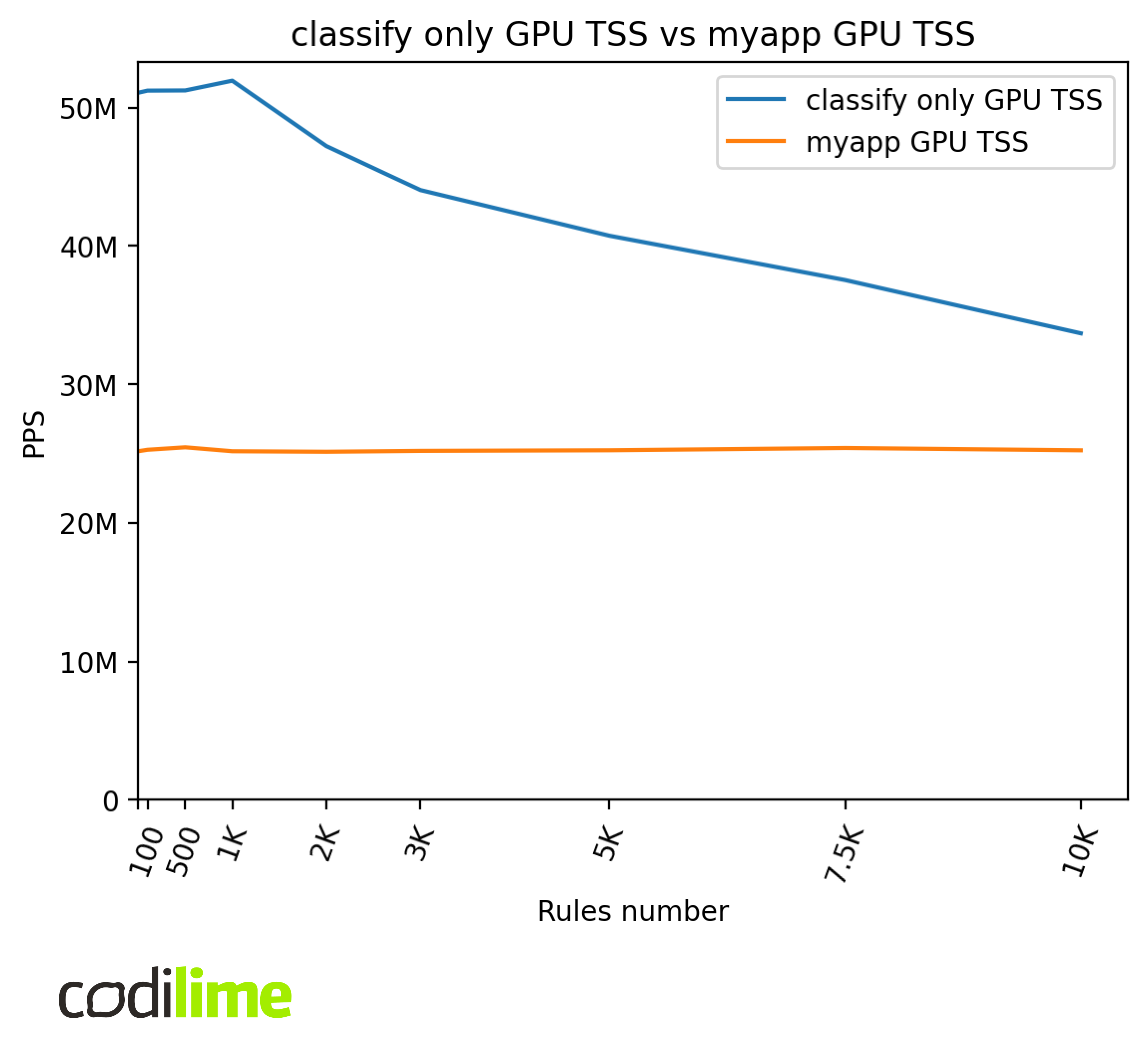
We can see that GPU TSS performance is much worse in the final application compared to the tests of the ACL module only. Final application GPU performance is capped at ~25 MPPS. This is most likely related to the limitations imposed by GPUDirect RDMA technology ![]() , which was used for direct communication between the GPU and NIC but this issue needs further investigation.
, which was used for direct communication between the GPU and NIC but this issue needs further investigation.
We also checked for increased latency between the classify-only and final application tests. Because of the ~25 MPPS cap, we tested both cases with 25 MPPS traffic.
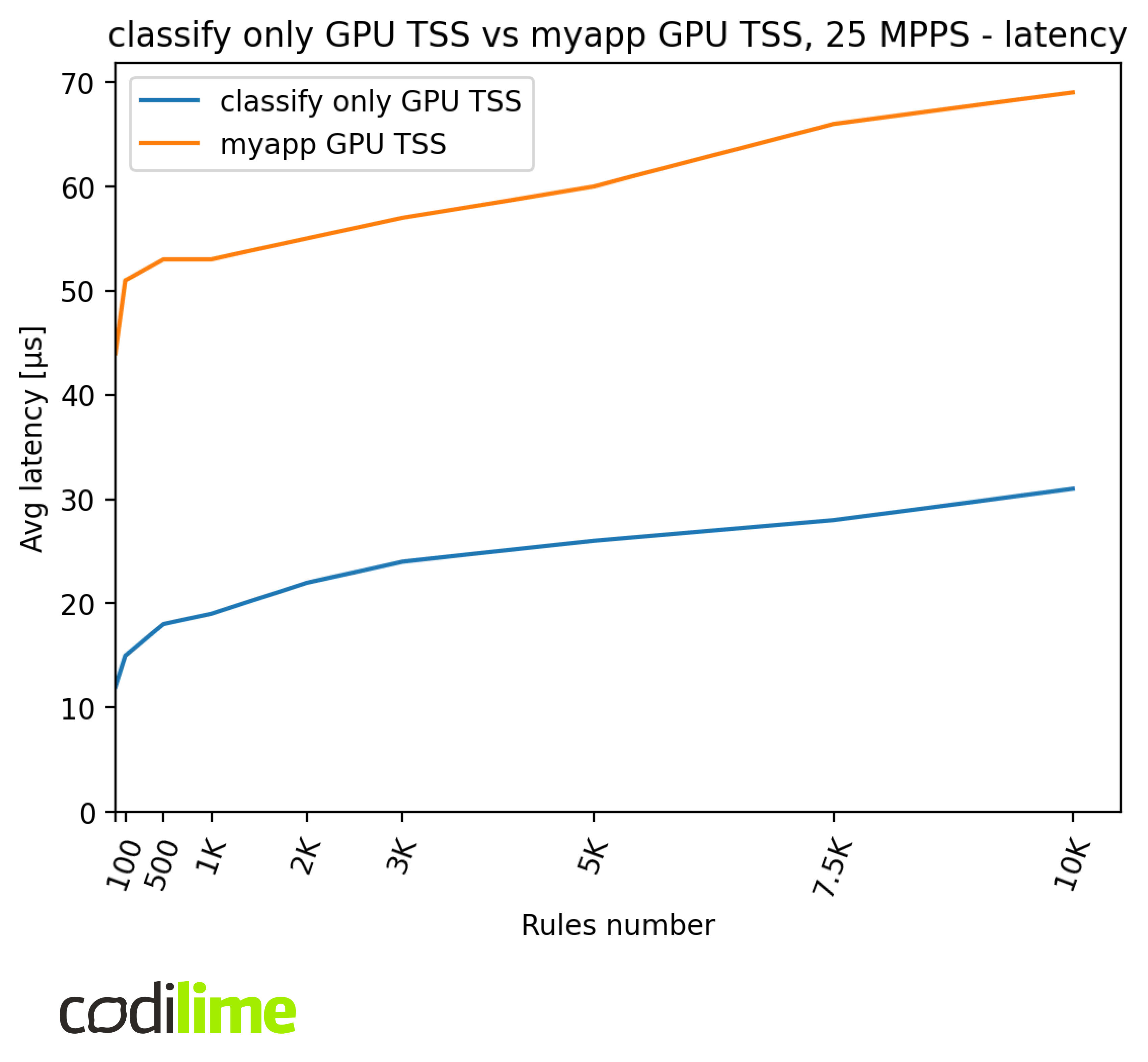
We can see that the latency difference is around 30-40 μs.
Below are presented the results of the naive algorithm. The naive algorithm is slower than TSS and so shouldn’t be affected by the 25 MPPS cap for bigger ACLs.
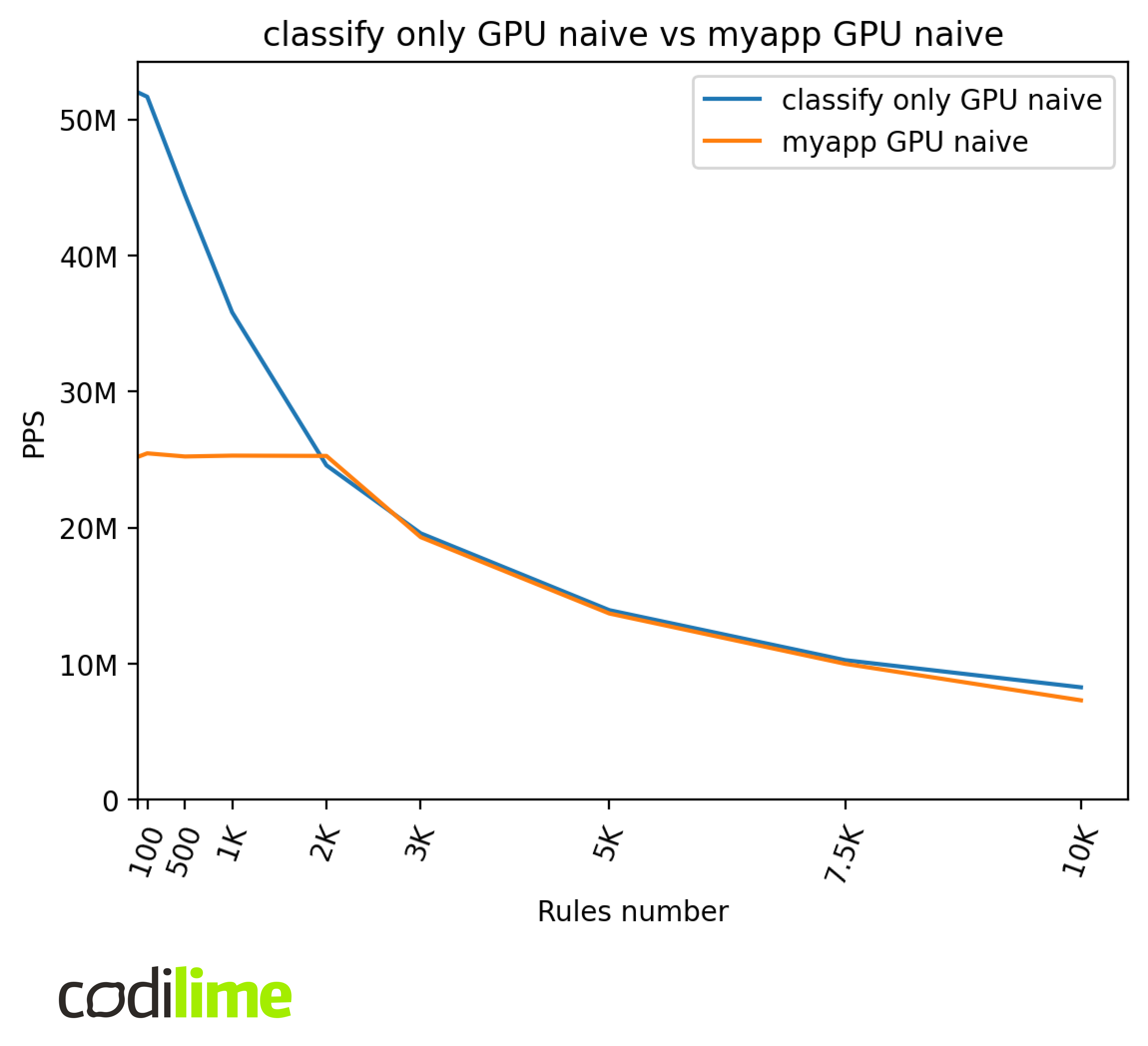
The final application performance is capped at ~25 MPPS for small ACLs. Because of that, GPU naive performance is worse in the final application for lower numbers of rules. However, we can see that the performance is comparable for higher numbers of rules, which means that for these ACLs the overhead caused by the module integration is negligible compared to the time needed to process packets using the naive algorithm.
myapp CPU vs. VPP
We compared the performance of our implementation of Tuple Merge to the VPP’s implementation of this algorithm. This can show if VPP implements optimizations that boost the performance which our implementations of CPU TM and GPU TSS lack.
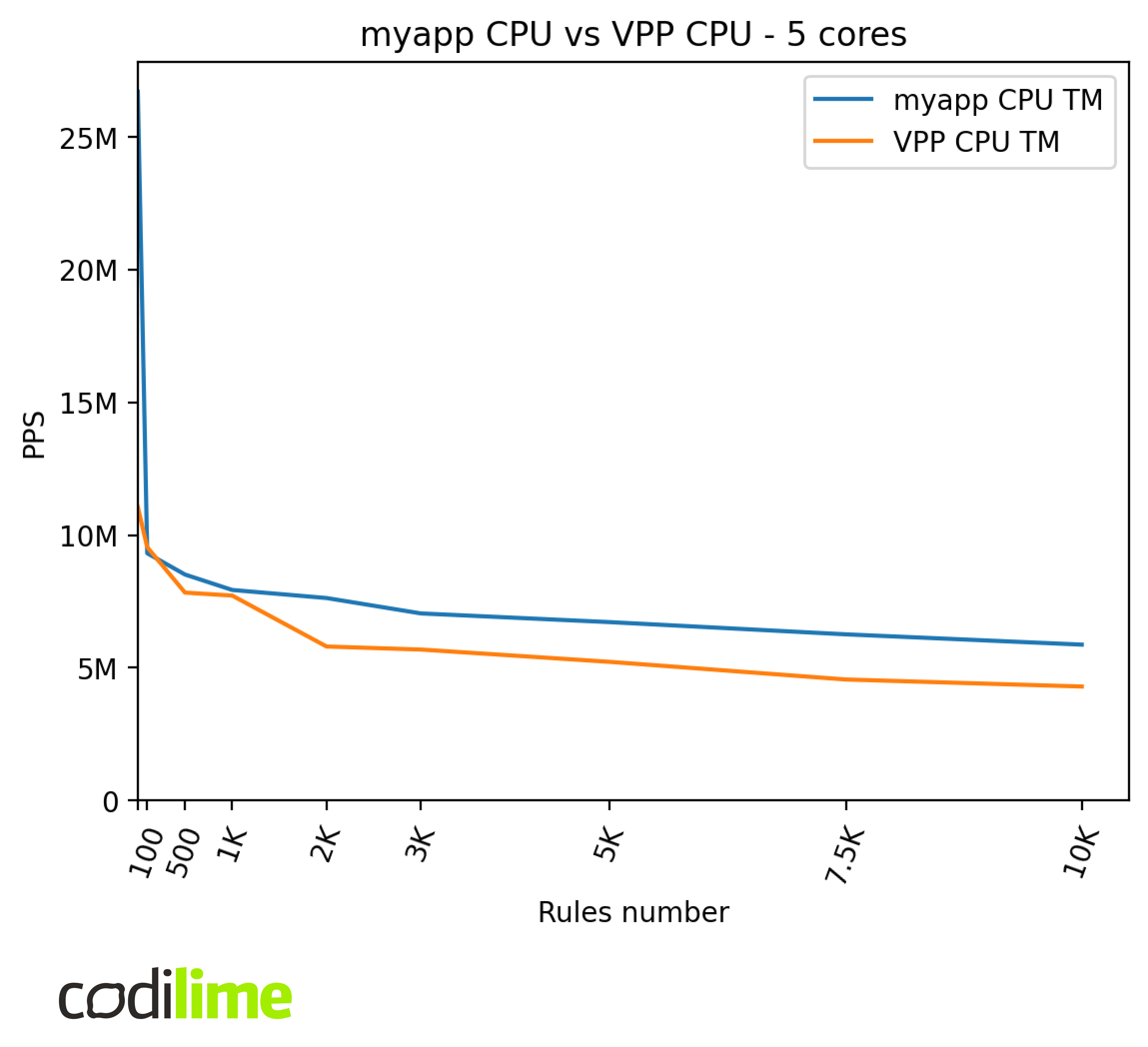
It turns out our implementation achieves better throughput in this comparison despite lacking any real optimizations. This can be caused by the fact that myapp performs filtering only and VPP needs to perform some additional work, like routing, etc.
myapp GPU vs. VPP
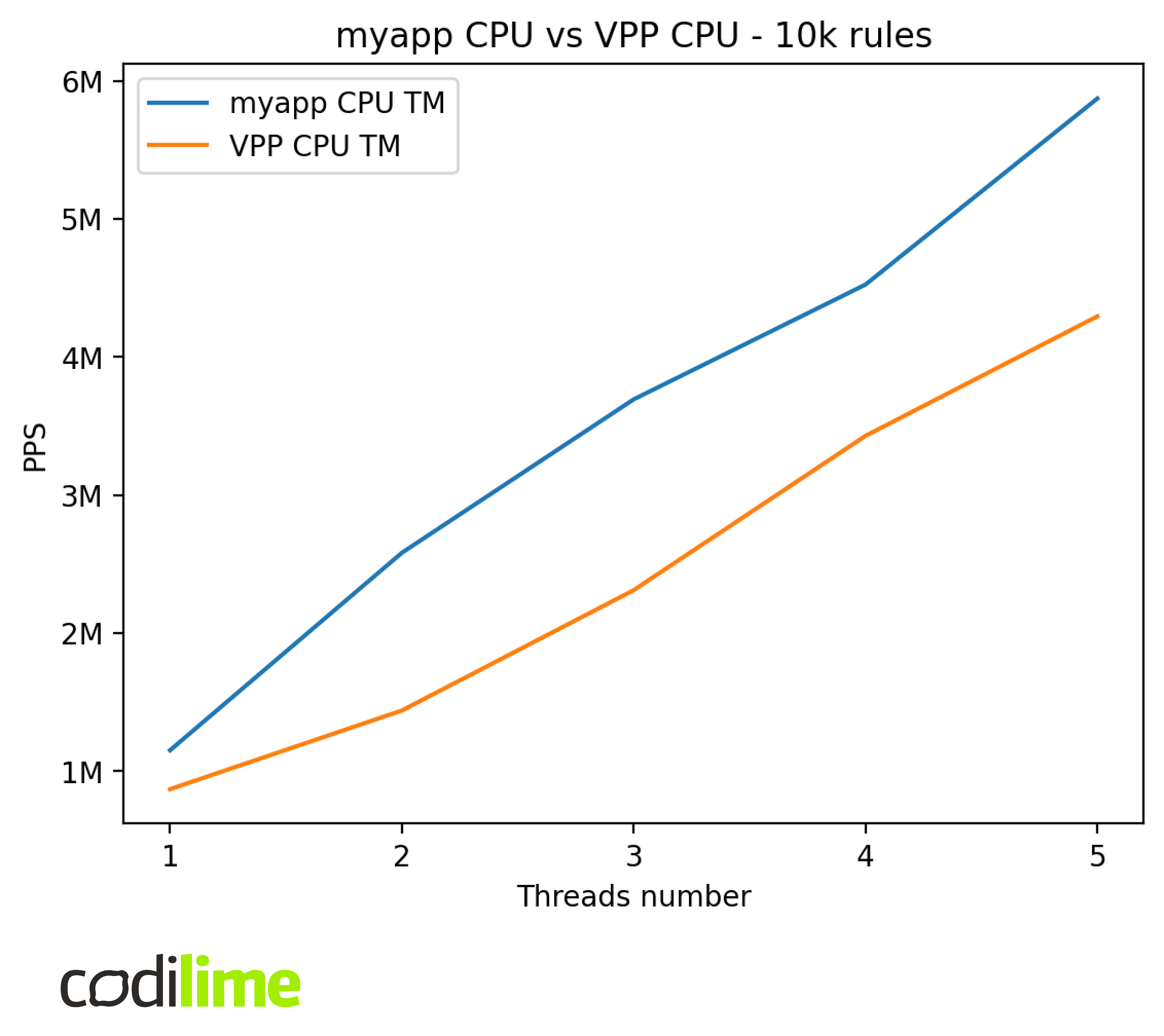
Now we compared our application to the VPP ACL plugin to see how much can be gained by using a GPU for traffic filtering.
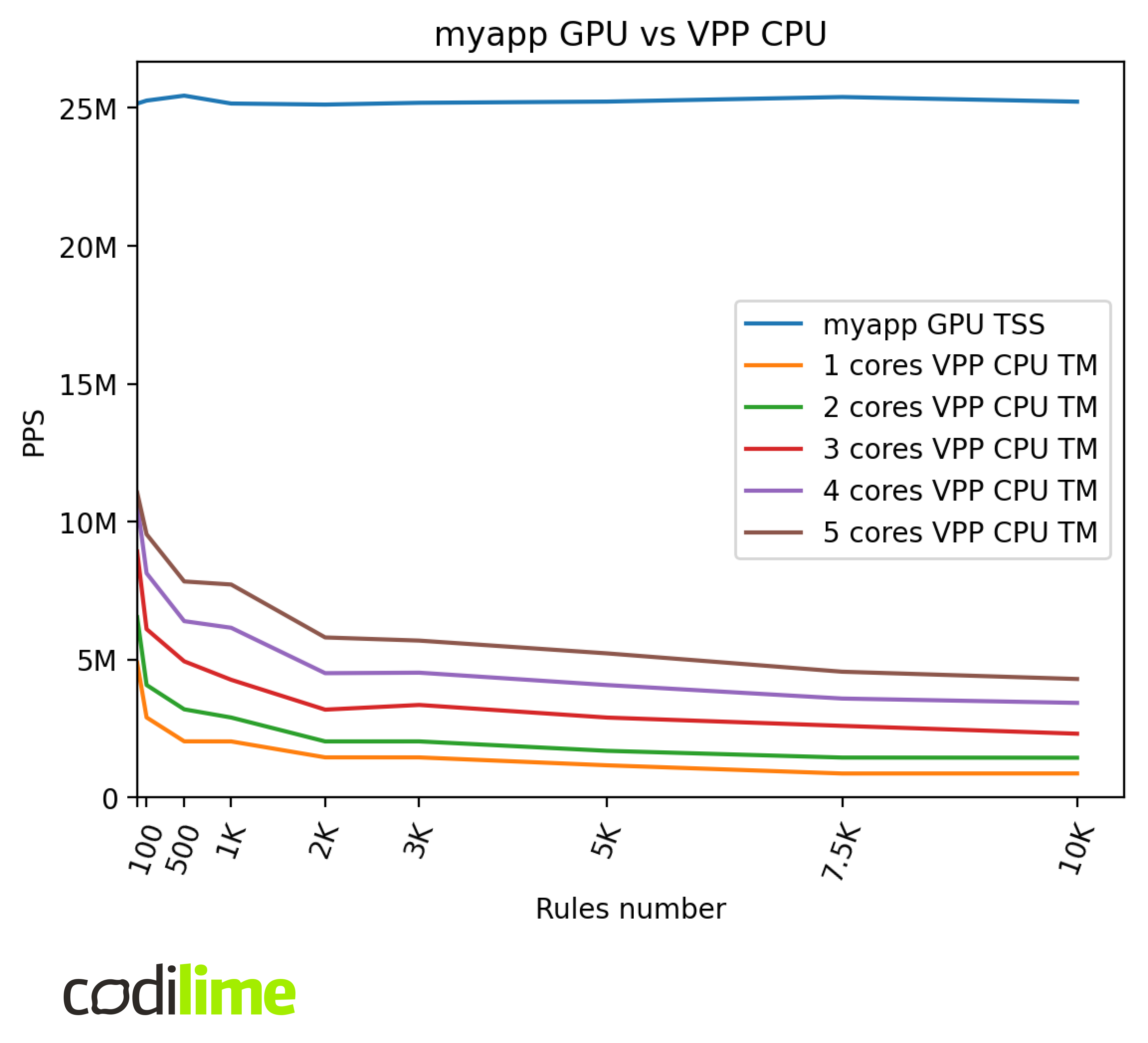
We can estimate that for 10k rules VPP would need about 30 cores to match GPU performance in the final application and about 40 cores to match the theoretical performance.
Below are presented the latencies of each implementation. We tested it with 98% of the maximal throughputs to increase stability.
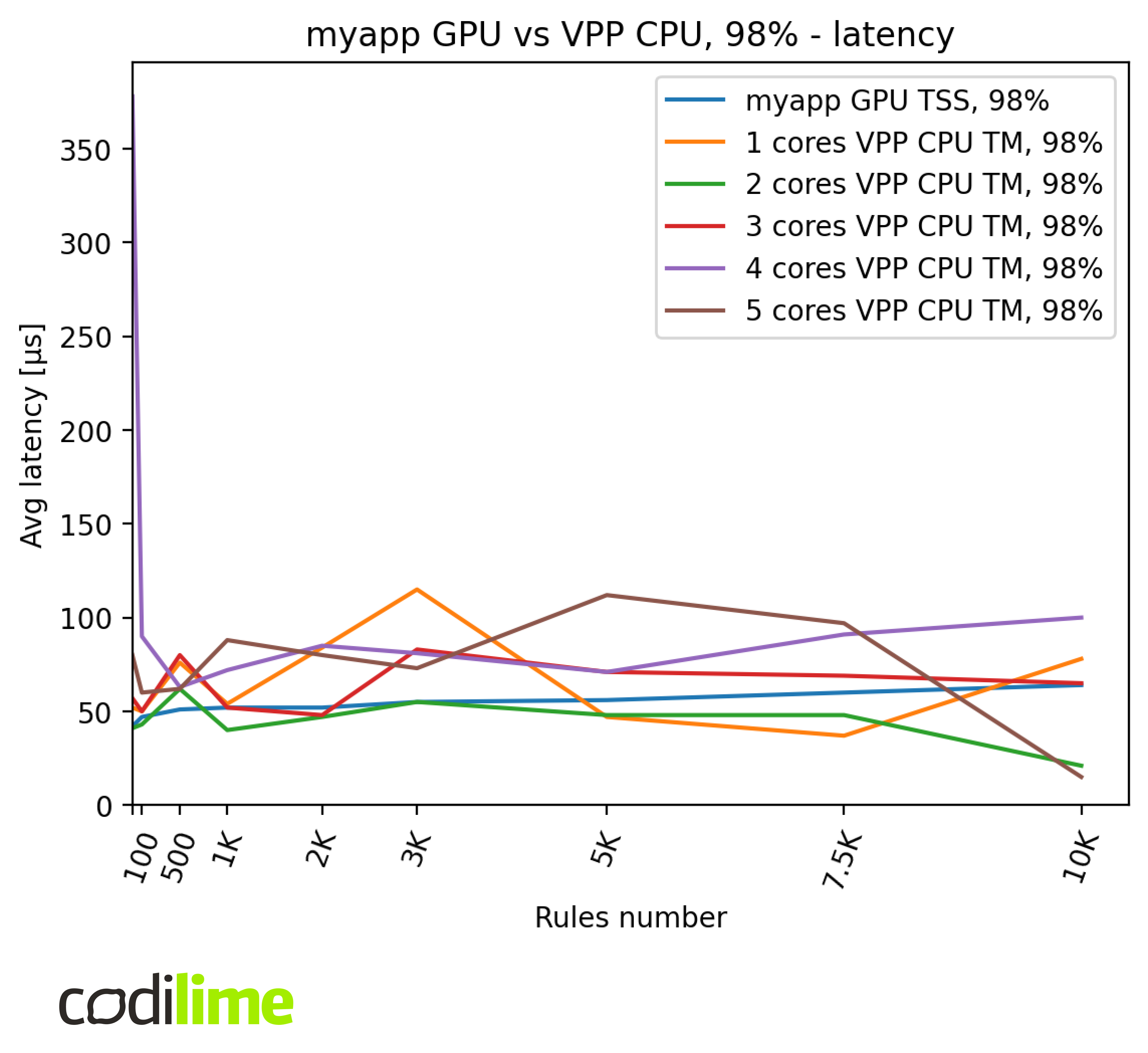
VPP latencies are not stable – they vary from around 20 μs to 100 μs and don’t present any particular pattern. On the other hand, myapp latency is much more stable and increases from 40 μs to 65 μs for bigger ACLs.
Further work
Below we list some topics that were omitted during this project but could provide some interesting results:
- Tuple Merge implementation on a GPU.
Throughout this blog post, we compared the GPU Tuple Space Search implementation to Tuple Merge implementations on a CPU. The question could arise: why haven’t we implemented a faster Tuple Merge algorithm on a GPU?
The answer is mostly related to the difficulty of effective implementation of this algorithm on a GPU. Not going into too much detail, calculations that need to be performed on a GPU in TM are less optimal compared to those in TSS. So even though it would be possible to see some improvements by adding a straightforward implementation of TM on a GPU, it wouldn’t be as fast as it potentially could be. Of course, better implementations of TM on a GPU are possible but need much greater optimization compared to TSS. Besides we mainly wanted to show that there is potential in implementing ACL filtering on a GPU, and the TSS implementation showed it.
- Using ClassBench
 for generating rules.
for generating rules.
ClassBench is a tool that generates synthetic classification rule sets for benchmarking. The rules are generated based on observations of real rule sets, such as the observations that were mentioned in the section “Generating test rules”. Using ClassBench would allow us to easily compare our results to other published filtering algorithms and implementations that used ClassBench for generating rules.
Summary
The results show that GPUs can dramatically improve the performance of ACL filtering algorithms. The VPP to myapp comparison has shown that we can achieve 30 times the speed by using a GPU compared to a single CPU core while maintaining low latency. This shows that using GPUs in computer networks can be beneficial.


