


According to Statista ![]() , in 2021, 85% of respondents (organizations employing a minimum of 5,000 employees) claim that they use microservices. Doubtless, adopting microservices can seriously benefit an organization and visibly improve the quality of the products and services it develops. However, it is crucial to do so properly to see positive results.
, in 2021, 85% of respondents (organizations employing a minimum of 5,000 employees) claim that they use microservices. Doubtless, adopting microservices can seriously benefit an organization and visibly improve the quality of the products and services it develops. However, it is crucial to do so properly to see positive results.
This article will highlight the most important aspects you should be aware of before implementing microservices architecture into the organization.
Microservices – a definition
Microservices architecture, as stated by Fowler, "Microservices is a subset of SOA (service-oriented architecture) with the value being that it allows us to put a label on this useful subset of SOA terminology.
- Componentization, the ability to replace parts of a system, as with stereo components where each piece can be replaced independently from the others.
- Organization around business capabilities instead of around technology.
- Focus on having smart endpoints and dumb pipes, explicitly avoiding the use of an Enterprise Service Bus.
- Decentralized data management with one database for each service instead of one database for a whole company.
- Infrastructure automation with continuous delivery being mandatory.”
-Martin Fowler
If you're curious, read more about the benefits of microservices architecture.
SOA – nothing new
Service-oriented architecture is not new. It was heavily driven by the advent of web services, as pushed by Microsoft in the early 2000s. Before that, we had seen attempts like DCOM, CORBA, Server Objects or Midas. Going back even further, we see mainframes that were often built around a transaction log, appended to by writer processes and tailed by so- called chaser processes that projected log entries to some shared state where other reader processes could read from.
SOA is just a label, coined by Alexander Pasik in 1994 because in his view, the term client-server had become “too overloaded”. Today we see the same with microservices.
The term has been given so much meaning that it has become meaningless.
How to fail with microservices
Creating distributed systems is hard and the first choice should be: Don’t!
Projects that start from the idea that “The new system will be based on microservices architecture” are usually doomed to fail from the start.
Inexperienced teams that are familiar with N-tier (layered) architecture tend to apply the same pattern onto the target architecture, resulting in a system that separates responsibilities into layers that govern data access, business logic and workflows, bound together using direct-call service communication. They end up with a system that is still monolithic in nature, but with distributed complexity added.
This is an anti-pattern also known as the distributed monolith.
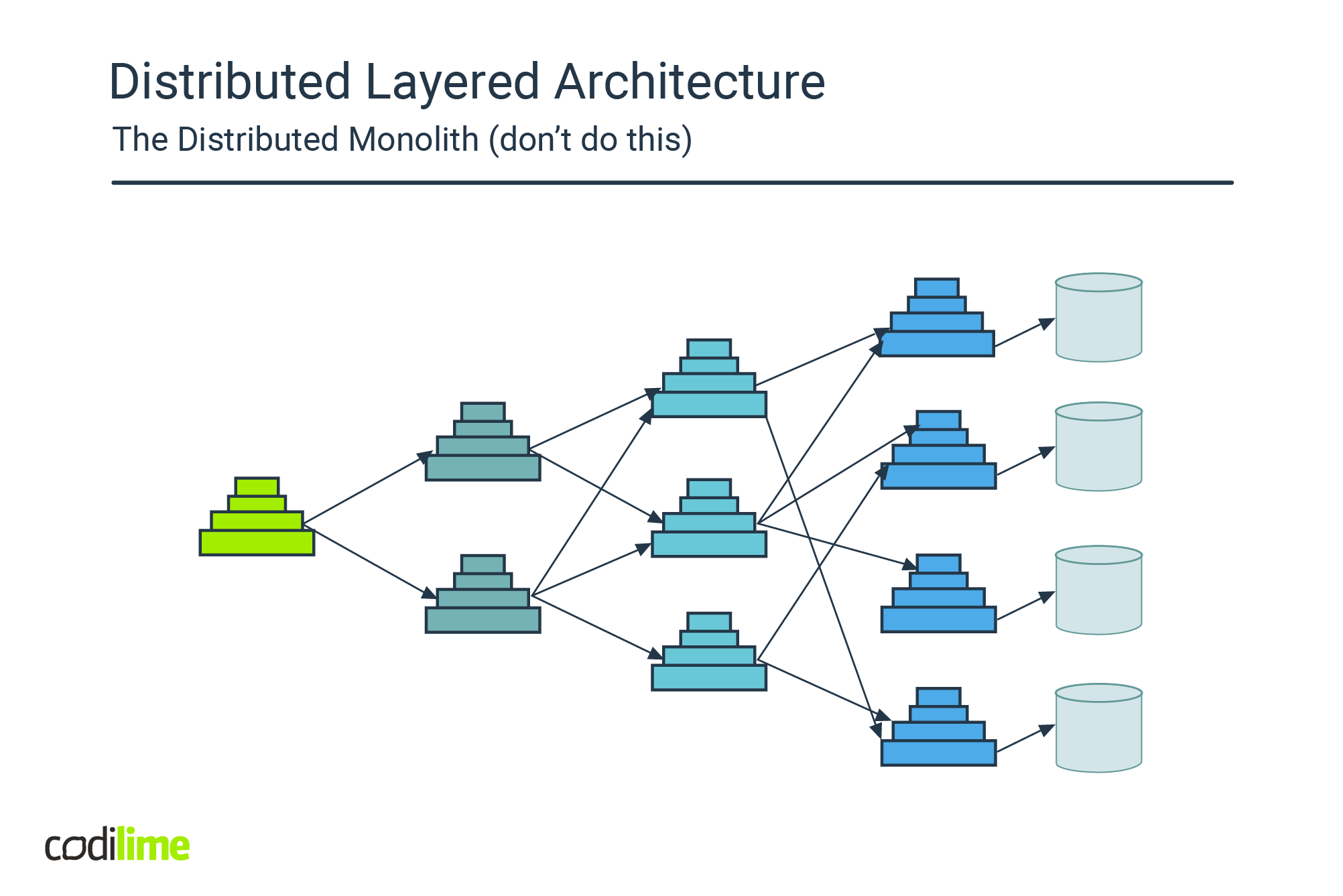
Attempting to split up a system into decoupled components is difficult and demands answers to a whole slew of complexities that are simply not relevant in a monolithic system.
If not addressed properly, these challenges often lead to systems of tightly-coupled services that are even harder to maintain than the monolith they are intended to replace.
So, unless you know what you are doing and are driven by non-functional requirements: don’t do it! The better option is to create a logical modular monolith that offers freedom in terms of unit of deployment.
Choices to make when distributing systems
We have briefly explored the path to disaster which is the distributed monolith.
In the following sections, we will investigate four design aspects that influence the maintainability, availability, scalability and extensibility of distributed systems. Choices must be made on how to minimize coupling, both in terms of design and runtime, by carefully defining the responsibilities of each microservice, the way they interact, the way they handle data and finally, how to avoid centralization and thus, a single point of failure.
Defining Context
A major factor that leads to tight coupling is the practice of distributing data and behavior over separate units of deployment. The obvious solution to this is to define service boundaries in such a way that behavior becomes part of the bounded context itself.
Historically, problem decomposition in a monolithic world was governed by a data-centric mindset. The technique, "underline the nouns in order to discover classes" was the go-to approach for context discovery.
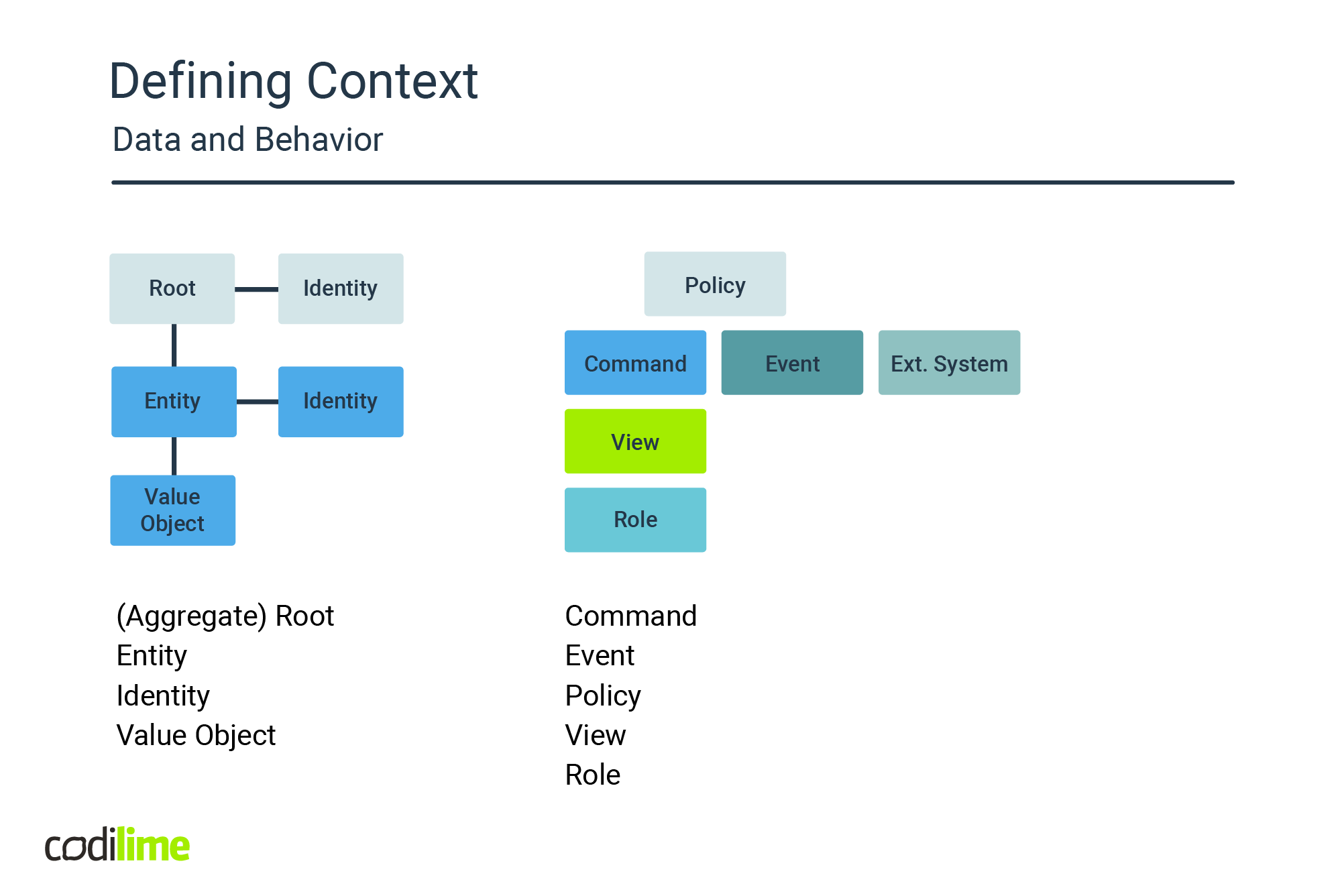
Though domain-driven design (DDD) has introduced many valuable concepts, like bounded context, aggregate root, entity or value object to enable reasoning about static models, it rather lacks the tools to also describe a context's dynamics, its behavior.
For describing behavior, the DDD vocabulary must be enriched with terminology that represents action and reaction: words like command, event, behavior aggregate or policy. Systems that put behavior at the center promote these terms to first-class citizens. In other words, they become an explicit part of the domain and are fully represented in the code, just like the traditional elements of DDD. A useful tool to discover this behavior is event storming: a lightweight, informal technique that is centered around mixed teams of technology and domain experts, with the goal of capturing the intended behavior of the system under design in a game-like setting.
About service interaction
As humans, we have a rather imperative mindset, perhaps it is because we have evolved into sentient beings with wishes and desires. We all seem to share this strange idea of 'being in control'. This is also reflected in the way we design systems: we command the computer to perform an action and expect it will be done.
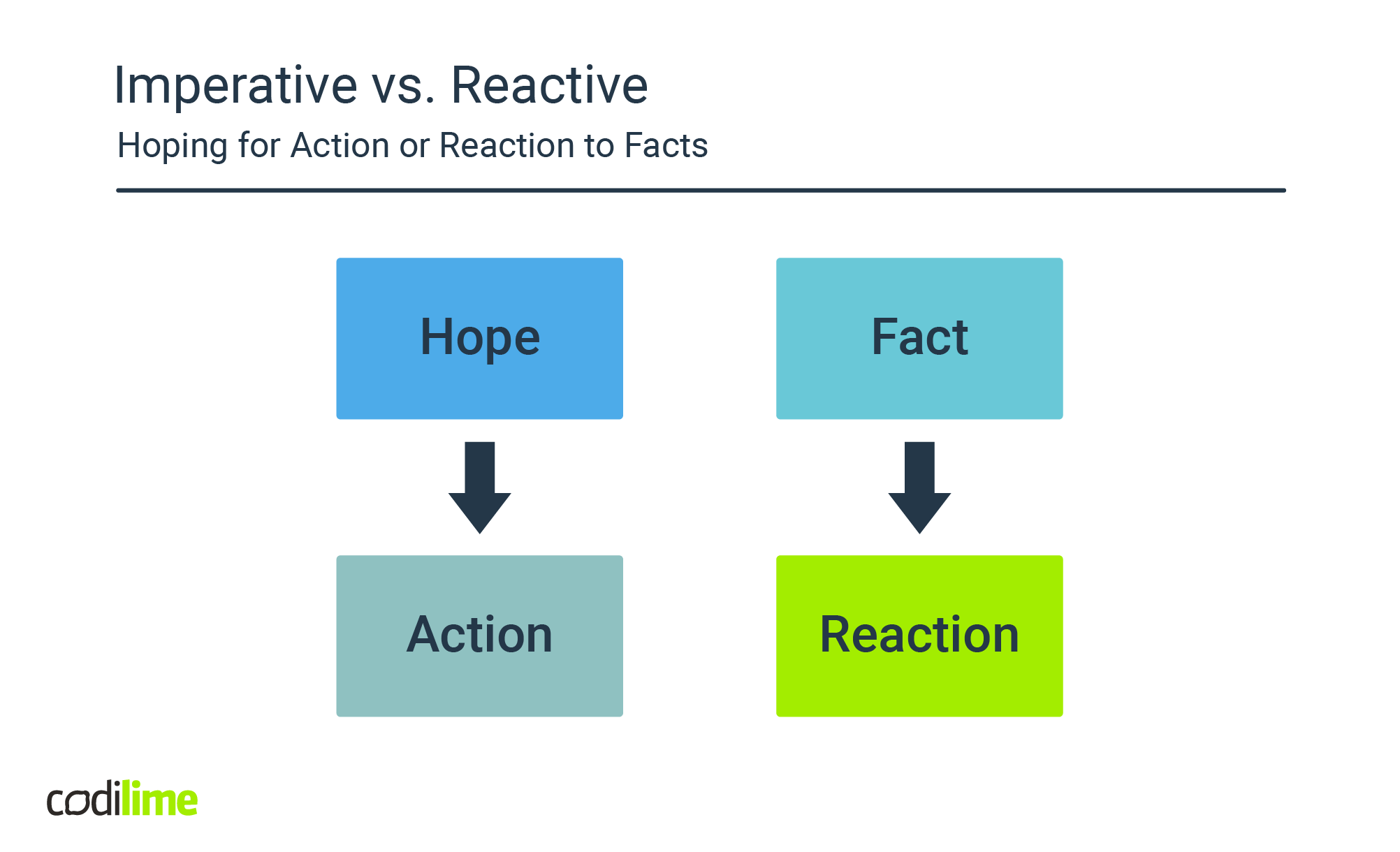
This mindset however, though it feels natural, results in tight coupling when applied to distributed systems. It’s yet another path that leads to the distributed monolith and thus should best be avoided. This path is recognizable by backend services that rely on synchronous, imperative “direct-call” endpoints in technologies like JSON-over-HTTP or gRPC.
The alternative approach, reactive design, is in fact a manifestation of the principle of inversion of control, where services react to facts (or events) asynchronously, as they occur throughout the system. In this case, event producers just fire off events and are not interested in whether or not an event is processed or by whom it is processed and will not wait for feedback. It allows the producers to continue their work unblocked. This has an important effect on the availability and overall performance of the system and is the principle behind event-driven architectures.
Consistency vs. Availability
Concurrency is a case in which separate processes share resources, be it computing power or data. The challenge is how to keep the state consistent when multiple processes have access to it.
In traditional, disconnected monolithic systems, handling concurrency usually boils down to the two-phase commit (2PC) approach, in which operations are encapsulated in transactions and data elements are locked until the transaction succeeds or fails as a whole.
Distributed systems however have the added complexity that the system must choose a strategy in case of network partitioning.
Be it due to infrastructure failure or service outage, the CAP theorem dictates that a choice must be made between data consistency or system availability.
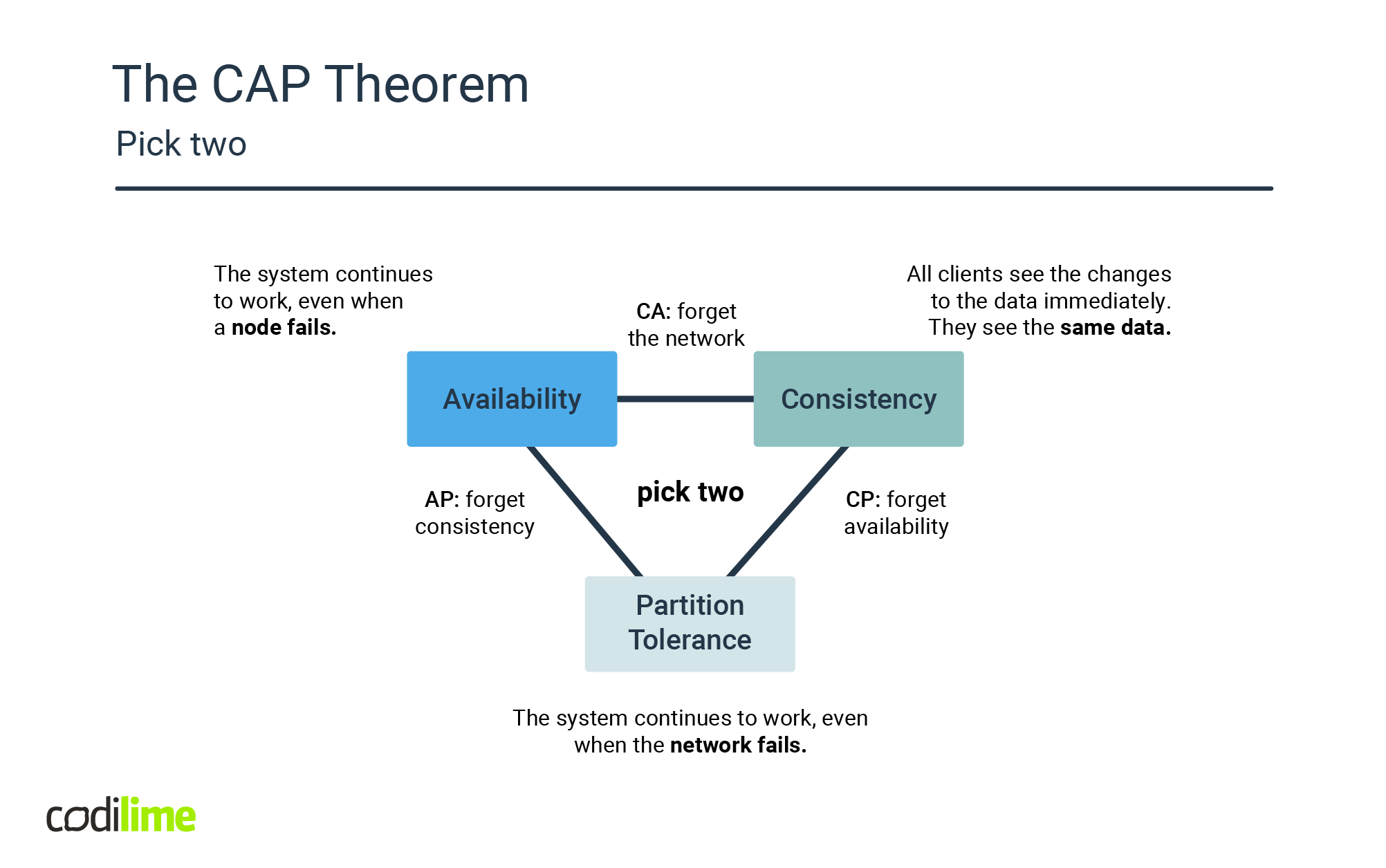
For distributed systems, availability has priority and eventual consistency is considered an acceptable trade-off. This offers the interesting possibility of building systems based on immutable data stores, where write operations append information to an otherwise immutable log and other operations read and transform this information and write it to a mutable data store that is eventually consistent and is optimized for querying only. This technique is also known as event sourcing with command query responsibility segregation (ES/CQRS) and it avoids the problems that arise from mutable, active record models that require transactions in order to guarantee consistency.
Orchestration vs. Choreography
Behavior in distributed systems can be supported in two ways: centralized, where it is implemented in specialized services called process orchestrators, or decentralized, when the behavior is embedded inside each individual service.
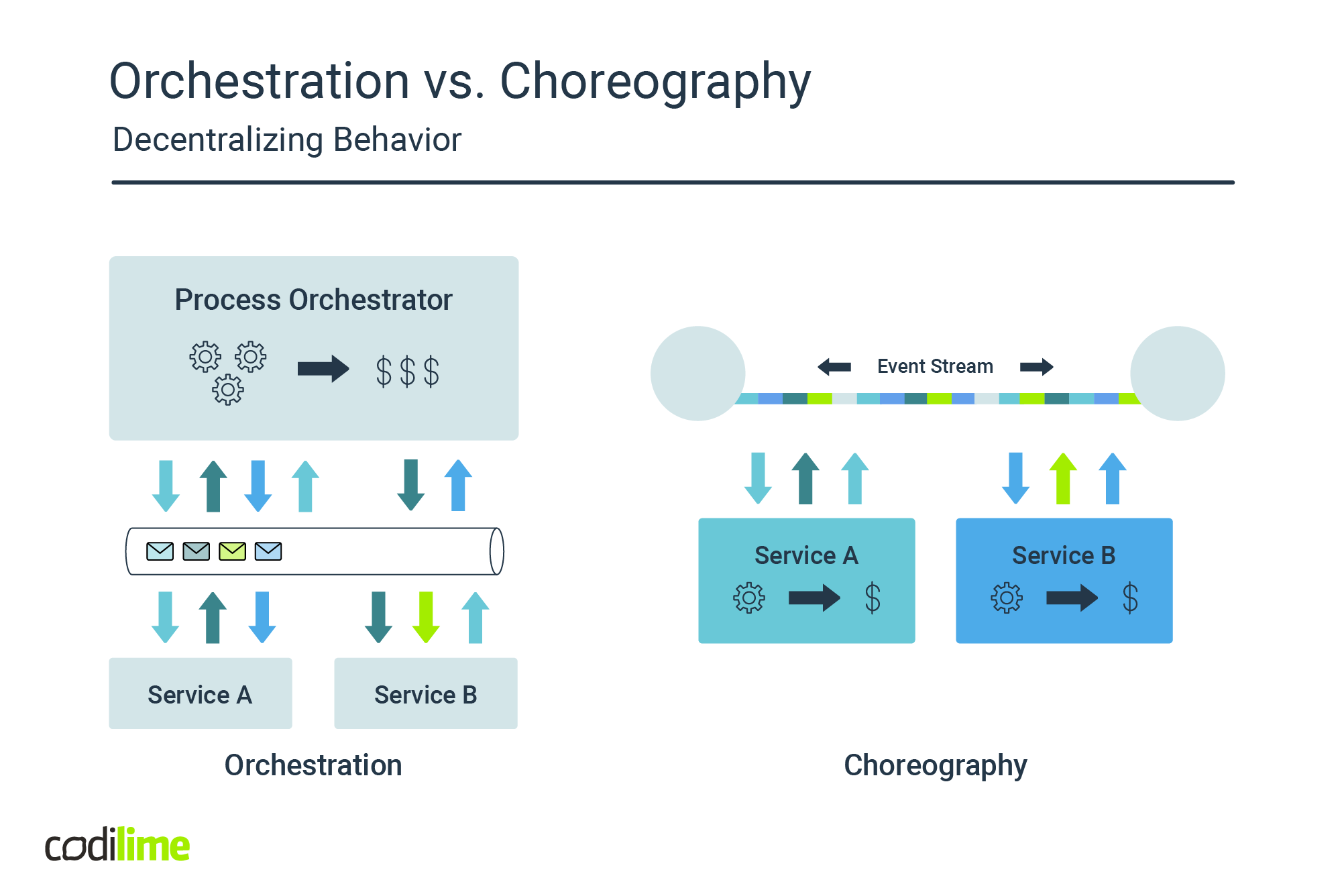
A common argument for using orchestration is that it offers the ability to maintain an overview of the business behavior, usually described in some DSL and visualized in fancy diagrams. Though there is truth in that, there are also some significant drawbacks: aside from the learning curve required to get familiar with the DSL and tooling, more importantly, this technique adds complexity and introduces a single point of failure.
A more reasonable approach would be to embed the behavior into the service and consider its bounded context to be defined by the full behavior instead of just its static data model.
This produces services that are behaviorally coherent and eliminates the single point of failure problem. The business process is not represented explicitly as a workflow though, it is enforced by policies that subscribe to topics on the internal event bus (the mediator) and in turn trigger other commands. This is called choreography and is supported by the domain event pattern.
Indeed, the resulting artifact would support a business process end-to-end and it would have quite a number of responsibilities, but it would also be autonomous, both at design time as well as runtime. The question is: could this still be considered a microservice?

Conclusions
All of the abovementioned aspects aim to help the team avoid common problems arising from a lack of information, or being overwhelmed by powerful terms without knowing their meaning.
The most crucial points that will ensure the right path while adopting microservices are:
- Avoid it if possible and definitely avoid the distributed monolith.
- Choose a service’s boundary based on behavior, instead of a static data model.
- Do not use an imperative, “direct call” model for service-to-service interaction.
A reactive, event-driven and asynchronous approach is preferable. - Embrace immutable state management and split write and read flows.
This means that using active record-style state management using mutable datastores is probably a bad idea.
Use event sourcing/CQRS instead. - Avoid centralization and the single point of failure.
Pick choreography over orchestration. - A well-designed modular monolith is probably a better idea.


