


Artificial intelligence (AI) has rapidly gained in popularity, revolutionizing numerous industries. However, despite the rapid advancements and widespread adoption of AI technologies, a significant challenge persists: the majority of machine learning (ML) projects never reach the production stage, with experts (KDnuggets ![]() , VentureBeat
, VentureBeat ![]() , Gartner
, Gartner ![]() , ML4Devs
, ML4Devs ![]() , Techstrong
, Techstrong ![]() ) estimating that up to 80% of these projects fail to be deployed. The primary reasons for this include critical issues with data quality and availability, misalignment between ML projects and business objectives, unsatisfactory accuracy of final ML models, and challenges in operational integration.
) estimating that up to 80% of these projects fail to be deployed. The primary reasons for this include critical issues with data quality and availability, misalignment between ML projects and business objectives, unsatisfactory accuracy of final ML models, and challenges in operational integration.
Many of these issues can be addressed by implementing the MLOps approach in ML projects.
What is MLOps
The concept of MLOps (machine learning operations) aims to streamline the development and deployment processes of ML-based solutions. MLOps is a set of practices that focus on unifying ML system development (ML Dev) and ML system operations (Ops). It allows for collaboration among data scientists, developers, and IT professionals, facilitating the continuous integration, testing, deployment, and monitoring of ML models and applications utilizing the capabilities of ML models.
Implementing MLOps yields several positive effects on ML projects. It facilitates faster and more stable deployment of models into production, significantly reducing the time from concept to utility. MLOps enhances the management and automation of ML workflows, resulting in better scalability and easier operations across different environments. It ensures projects are reproducible and accountable by emphasizing thorough documentation and version control of data, models, and code. Finally, MLOps adopts a continuous improvement approach, allowing teams to adapt developed models to new data or changing environments effectively.
MLOps: evolution of operational demands
There are several operational approaches from which MLOps emerges.
- DevOps is a cultural and professional movement that emphasizes collaboration, communication and integration between software developers and IT operations professionals. It focuses on automating all processes between software development and IT teams to build, test and release software faster and more reliably. The key principles of DevOps include continuous integration and continuous deployment, rapid feedback loops and a strong emphasis on automation to ensure the efficiency of software releases.
You will find many more benefits of continuous deployment in this article.
- Site Reliability Engineering or SRE is another discipline that takes a slightly different approach. SRE applies aspects of software engineering to system management problems. The core idea is to create scalable and highly reliable software systems. It is based on principles such as automation of operational tasks creating repeatable processes and using engineering solutions for operational issues. SRE focuses on service-level objectives, error budgets, and managing incidents systematically to maintain system reliability. You can find out more about the differences between SRE and DevOps in this article.
- DevOps practices are evolving with new ideas like GitOps. GitOps extends DevOps by using Git as a single source of truth for declarative infrastructure and applications. It emphasizes version control for all parts of the system and automates the application deployment process. This approach enhances visibility, accountability and consistency across operational tasks. You can find out more about the differences between GitOps and DevOps in this article.
Building on the foundational principles of DevOps, MLOps represents a natural progression from these principles. It applies similar concepts to the machine learning life cycle. It extends the DevOps philosophy to include model development, deployment, and monitoring, ensuring that machine learning systems are as robust, scalable, and maintainable as traditional software. Thus, DevOps serves as a critical base for MLOps, adapting its best practices to meet the unique challenges of machine learning projects. Here, you can check our data science services that can help you implement this approach.
Machine learning project life cycle management
MLOps is intended to manage the entire life cycle of machine learning projects, encompassing everything from data preparation to model deployment and monitoring (Figure 1).
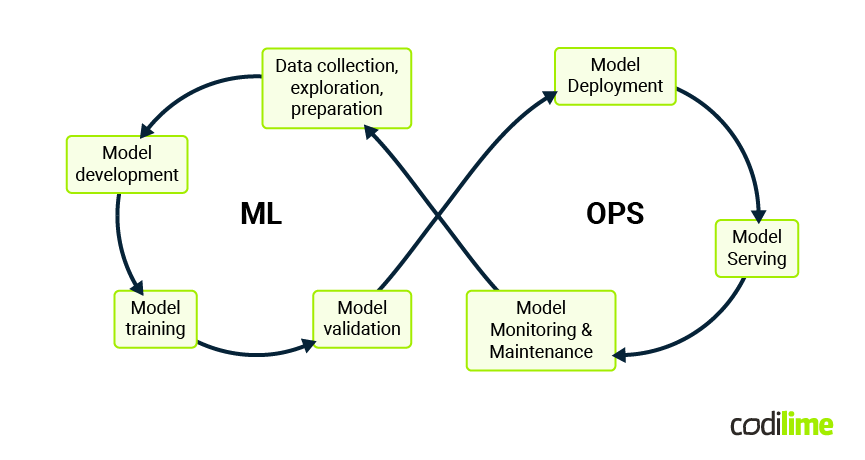
Data collection, exploration and preparation is the first stage, where the necessary data is gathered, cleaned and transformed into a format suitable for machine learning models. Automated data pipelines encompassing a set of data retrieval and processing methods are a key component of MLOps. The goal is to ensure that data is consistently preprocessed and ready for model training.
Data scientists and engineers develop code for building and training models in the model development stage. This phase applies an iterative improvement approach through experimentation. MLOps forces the usage of version control systems that manage different versions of datasets and models during experimentation. Also MLOps supports this stage by applying frameworks and tools facilitating algorithm selection, hyperparameter tuning, features reduction and cross-validation.
Model validation is the next step, when a model is developed and optimized for training data. It is necessary to verify whether it performs well on unseen data. MLOps strongly suggests creation of a suite of various tests to validate model accuracy, bias and other model-specific metrics. Such a suite should be executed using automated testing frameworks. The goal is to ensure the acceptable level of the model’s robustness and reliability before deployment.
Model deployment into production is the next complex task that MLOps tries to facilitate. MLOps promotes automation tools, helping to deploy models across different environments consistently. Packaging tools, containerization technologies like Docker and orchestration systems such as Kubernetes are crucial to deploy scalable machine learning models able to handle real-world loads. The positive result of this phase means that our model is moved to the model serving stage.
After the model’s deployment into the production environment, it should be properly monitored and maintained. Continuous monitoring is essential to ensure the model performs as expected. MLOps promotes tools to monitor the model’s performance, to track its degradation over time and to trigger alerts when its performance drops below acceptable thresholds. The alerts indicate when the model should be retrained or refined.
Model retraining, refinement and updating are essential maintenance tasks. It is normal that ML models can drift over time as data patterns may change over time. Often, model retraining on new data is enough to keep the model in a good condition. However, sometimes more complex model refinement is necessary. MLOps supports both approaches automating the workflows leading to new model versions with acceptable performance as well as automating the replacement of the older versions in production without downtime.
Governance and compliance are crucial aspects of MLOps, encompassing all activities required to meet regulatory and compliance requirements for machine learning processes. A set of practices and guidelines ensures that ML models are developed and maintained in a transparent, ethical, and legally compliant manner. Key aspects include secure data processing, data privacy assurance, comprehensive documentation of data processing and models, transparency, audit trails, accountability, stakeholder engagement, and legal reviews. These measures help maintain the integrity and trustworthiness of ML operations while adhering to regulatory standards.
Key differences between MLOps and DevOps
DevOps and MLOps are both methodologies to facilitate and optimize processes in their domains: software development and machine learning respectively. As we have mentioned, they share common principles, such as automation, continuous integration and continuous delivery. However, there are several key differences that are worth knowing.
The primary focus of DevOps is on continuous development, testing, integration, and deployment of software applications. And the primary objective is to shorten the development life cycle, frequently delivering new features, fixes and updates aligned with business objectives. MLOps focuses on ML models' life cycles, from data collection, preparation, model training to deployment, monitoring and maintenance. The goal is to deliver models that are accurate, fair, and perform well over time.
The life cycle of machine learning systems is more complex than for a typical software application. The experimentation and ML model maintenance stages especially require additional effort. Changes that finally need to be deployed are not only in code and configuration (as in DevOps), but also can involve training data, model parameters and the applied learning algorithms themselves.
Version control of the code and the configuration is obvious for both DevOps and MLOps. However MLOps practice also promotes versioning of the data the model was trained on, and versioning of the trained ML model itself. Additionally, experiment tracking is very useful to determine the optimal settings of models’ hyperparameters and allows for no-repetitive approaches leading to best performing models.
DevOps emphasizes testing to check software functionality and performance in the form of unit, integration and performance tests. In the case of ML systems, similar types of tests should cover validation of ML model accuracy, as well as the statistical properties of data and model predictions.
Both DevOps and MLOps leverage CI/CD principles and tools such as Jenkins, Docker, and Kubernetes as well as configuration management tools like Ansible or Chef. MLOps extends the tool list with a set of specialized tools and frameworks for data management, ML model training (PyTorch, TensorFlow), model serving (TorchServe, TensorFlow Serving) and model monitoring.
Common challenges of DevOps and MLOps include managing infrastructure and dependencies, ensuring high availability and low latency, and managing security. MLOps faces additional problems such as dealing with data and model drifts, reproducibility issues and the need for continuous training and model updates due to the evolving nature of data.
We should also realize that the collaboration between developers and operations teams, which is typical for DevOps, is much more rich in case of MLOps. MLOps assumes collaboration not only between data scientists, ML engineers, and operations but also involves active participation from data engineers and business stakeholders. This increases the chance that ML models are effectively integrated into business processes and bring value.
Often neglected aspects of ML projects
With an understanding of the major stages of the ML project life cycle, let us outline the key unique challenges that MLOps addresses, which are often neglected in practice.
- The first key challenge is model deployment and scalability. Early versions of data processing pipelines and ML models, even those not yet achieving the required accuracy, should be containerized and deployed in a test environment. This allows automation of the process for subsequent experimental model versions and streamlines the eventual deployment into production once the model is sufficiently accurate. More importantly, early deployment provides critical information on the required resources and infrastructure costs needed for efficient processing at the expected request rate. This feedback can influence key decisions by data scientists, such as the selection of learning algorithms, helping them avoid investing effort in models and frameworks that may face scalability issues and can cause unacceptable costs.
- The second challenge is model monitoring and management. Once a model is deployed, it must be properly monitored to detect performance degradation, usually caused by data drift (changes in data over time) and model drift (changes in model behavior due to evolving data patterns). MLOps promotes tools that facilitate monitoring of model performance metrics and data quality, track data drift, and set up relevant alerts. Additionally, MLOps strongly recommends creating feedback loops capable of triggering automatic model retraining or fine-tuning in response to new data, ensuring the model adapts to changes over time. Overall, a robust monitoring and alerting system is crucial to indicate the need for model refinement. Without such functionality, an ML system deployed in a production environment may operate for long periods with a poorly performing model.
- The third challenge is reproducibility and version control. Data scientists conduct numerous experiments with different algorithms for data preprocessing and model training, and various parameters ultimately influence model performance and accuracy. Without exact tracking of experiment settings, it is easy to get lost and it can be challenging to reproduce results in a production environment. This can lead to unexpected issues and failures that are difficult to debug and fix. Implementing strict version control and detailed documentation of experiments saves significant time for data scientists and operations teams.
Key principles and best practices for implementing MLOps
Implementing MLOps within organizations requires a structured approach to managing the entire machine learning life cycle. Unlike a one-time implementation, MLOps is an iterative, cyclical process that evolves as the organization gains insights from completed projects. While not every practice is essential or beneficial for each project, and some may incur unnecessary costs if applied too early, it is crucial to identify and prioritize key practices that are indispensable. Neglecting these can result in significant technical debt, hindering future advancements and operational efficiency. The focus should be on establishing a solid foundation with essential practices that ensure scalability, reproducibility, and effective management of ML models.
Below there are the key principles and practices of MLOps:
- Alignment with business objectives: Start with a clear definition of the expected business goals related to a machine learning project and set measurable objectives and KPIs.
- Ensuring data quality and accessibility: Implement robust processes for data collection, cleaning and validation. Use specialized tools for data versioning and tracking data changes over time. Ensure data is available in a secure way.
- Systematic experimentation: Use tools like Jupyter Notebook for exploratory data analysis and initial model training. Apply experiment tracking tools to log experiments, track model versions and manage artifacts.
- Rigorous testing and validation: Apply a rigorous model testing approach that includes validation against unseen data, cross-validation and if possible A/B testing (comparing the performance of the new model against the current model using a controlled experiment with real users, to determine which model performs better). Establish predefined metrics and thresholds for accuracy, fairness and robustness that need to be met by the final model.
- Reliable and scalable deployment: Use containerization and orchestration tools for reliable and scalable model deployment. Implement CI/CD pipelines for automated integration and deployment.
- Continuous monitoring and operational efficiency: Implement monitoring tools for tracking model performance (accuracy, drift) and operational metrics (latency, throughput). Design dashboards and use logs to provide real-time insights into system health.
- Adaptive and continuous learning: Implement processes for continuous model retraining or fine-tuning with new data, especially when the data is subject to drift. Wherever possible try to automate the model update processes and redeployment processes.
- Ethical AI and compliance: Document all aspects of the ML life cycle for auditability. Implement mechanisms for model explainability and transparency. Ensure all machine learning practices comply with relevant laws and ethical norms.
- Cross-functional collaboration: Set up a collaborative environment among data scientists, ML engineers, DevOps, and business stakeholders. Use tools that facilitate communication and transparency across teams.
- Robust and flexible infrastructure: Invest in scalable infrastructure that supports the demands of machine learning workloads. Consider cloud-based solutions for flexibility and cost-efficiency.
MLOps tools and frameworks
MLOps can be introduced into organizations using various tools and frameworks. Below is a list of the most popular ones.
- MLflow (MLflow
 ) is an open-source platform primarily used for managing the machine learning life cycle, including experimentation, reproducibility, and deployment.
) is an open-source platform primarily used for managing the machine learning life cycle, including experimentation, reproducibility, and deployment. - Kubeflow (Kubeflow ) is a Kubernetes-native platform that supports end-to-end orchestration of machine learning pipelines and provides scalable and portable deployments across diverse infrastructures.
- TensorFlow Extended (TFX ) is an end-to-end platform designed to deploy production machine learning pipelines. It integrates tightly with TensorFlow but supports other tools as well.
- TorchServe (TorchServe ) is an open-source model serving framework for PyTorch. It is designed to make it easy to deploy PyTorch models at scale without having to write custom code.
- Apache Airflow (Apache Airflow ) is an open-source tool used for orchestrating complex computational workflows and data processing pipelines.
- Data Version Control (DVC ) is an open-source version control system for machine learning projects. It extends version control to machine learning data and model files.
- Metaflow (Metaflow ) is a human-centric framework for data scientists to build and manage real-life data science projects with ease.
- Polyaxon (Polyaxon ) is a platform for reproducible and scalable machine learning and deep learning on Kubernetes. It includes features for experimentation, automation, and monitoring.
- Prometheus (Prometheus ) is an open-source monitoring system with a focus on reliability and simplicity. It is often used to monitor the performance of machine learning models in production.
This non-exhaustive list of open-source tools covers various aspects of the MLOps ecosystem, from data management and model training to deployment and monitoring. Many tools offer similar functionalities, making it challenging to select the final set and integrate them. Consequently, numerous commercial platforms, tools, and frameworks support the MLOps culture in organizations. These commercial solutions can be considered when the integration and maintenance effort, as well as the required skill set, is too high for open-source alternatives.
Conclusions
In conclusion, the rapid proliferation of AI presents immense opportunities and significant challenges, notably the frequent failure of ML projects to move from development to production due to issues like data quality, business alignment, model accuracy, and operational integration. MLOps addresses these challenges by fostering a cohesive environment for developing and deploying ML models, ensuring seamless collaboration among data scientists and engineers, developers, and IT professionals. By extending DevOps principles to cater to ML workflows, MLOps emphasizes version control, continuous monitoring, and automated retraining, promoting integrated, sustainable, and scalable ML practices. Adopting MLOps can mitigate ML project failures, accelerating the transition from conceptual models to actionable applications, enhancing technological capabilities, and ensuring ethical alignment and regulatory compliance.


