


Buggy software does no one any good. It harms a company’s reputation, turns off clients and frustrates developers. Correcting bugs when software has already been deployed into production is expensive and time-consuming. To avoid all these pitfalls, learn more about software testing best practices. They’ll keep you on the right track in your QA in 2020 and beyond.
Design all tests to be independent from one another
The test suite you design can have any number of automated tests, but for simplicity, let’s go with 100. It is essential to be able to launch every test independently of other tests. The tests can be launched in a sequence (sometimes the testing environment doesn’t support parallel testing). But still the execution of one test should not depend on the execution of a previous one. Allowing the tests to depend on each other can lead to serious problems. When a test fails, you will not know where the cause may lie. Therefore, it’s better to run every test checking a given functionality independently. In this way, if the test fails, it is easy to discover what went wrong. In other words, both debugibility and developer experience are considerably improved. Moreover, you should be able to run a single test independently. The state of the System Under Test should be known before and after running the test. Test fixtures for both the setup and teardown environments can help considerably here. To reduce interference between test cases, it is good practice to always clean up after yourself.
Integrate all tests with the CI/CD pipeline
The ideal QA process in a company should be automated in such a way that every change in the code is tested automatically as a part of the CI setup before the changes are deployed into production. Testing automation is a crucial element of any successful QA process and today, in the era of DevOps methodology and CI/CD, it makes no sense to perform automated testing outside the CI/CD pipeline. Each element of your testing pyramid should be included in this pipeline, and all such tests should be designed to return results as quickly as possible. Finally, the golden rule says: test as early as possible. Test-driven development shout start at the initial stages of the software development process will improve the final outcome. So be sure to include tests in your CI/CD pipeline right at the beginning of your software project.
Make tests independent of the data source
Another important best practice is to make the tests independent of the data source. The first step toward that end is to separate the test procedure and test data. Then plan the next step to draw on different data sources. Such a separation allows you to test your testing framework itself, as it is important to check if the tests you’re designing work as expected. Separating the tests from the data source will enable you to emulate a real testing scenario by sending mock data to a testing framework, which will not be able to detect if the data coming from the System Under Test (SUT) are real or mock. Keeping the testing framework and SUT separate will mean you don’t have to adjust your testing to every SUT you want to test.
Write requirements that can be easily converted into testing scenarios
When writing requirements explaining what you expect to be developed and tested, do your best to write in a simple and easy-to-understand manner. Then, it should be easy and straightforward to write these requirements in Gherkin language ![]() , which uses natural language to convert them into behavior-driven testing scenarios. Such a scenario might look as follows (keywords in italics):
, which uses natural language to convert them into behavior-driven testing scenarios. Such a scenario might look as follows (keywords in italics):
Feature: Logging into the app
When User enters login and password
Then User gets access to the app.
Gherkin is supported by many modern testing frameworks and is a very useful tool in Behavior Driven Development (BDD). In the end, you should even write requirements using Gherkin syntax. Then every team member will understand what needs to be covered by the tests.
Rely on all levels of a testing pyramid
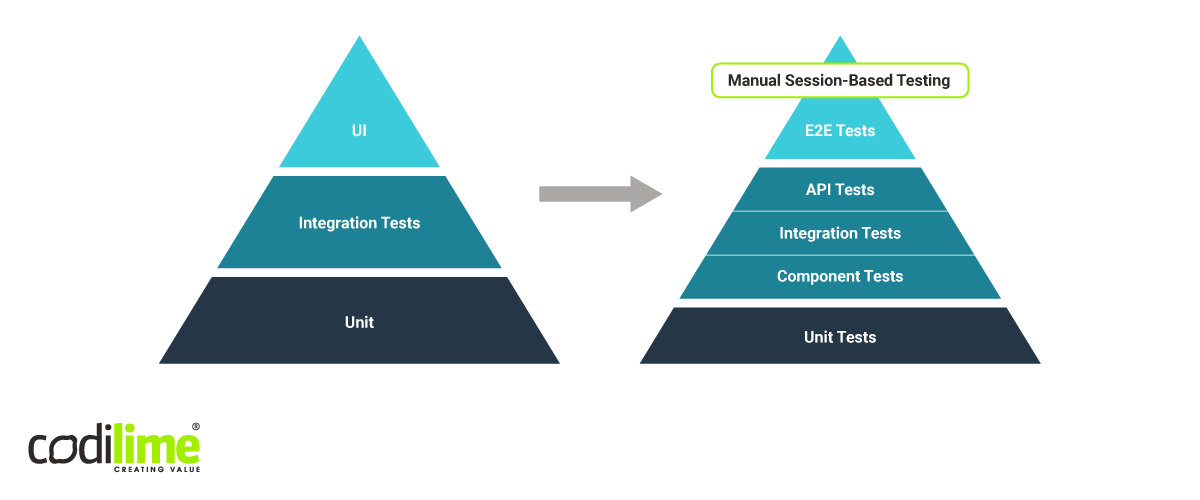
Software developers should use testing pyramids. The base consists of unit tests, which test small pieces of code and are the most numerous. The next level up contains component tests, which test single components (e.g. logging form) in SUT. The third level up contains the integration tests for checking how different software components work with each other. This is followed by the API and UI tests, which test APIs by sending API calls and monitoring the results. On the top level are End-to-end (E2E) tests, which can be either automatic or manual.
The number of the tests depends on where they are located in the pyramid. The higher you go, the smaller the number. This rule also applies to testing costs. The bottom-level unit tests are the cheapest, while the E2E tests are the most expensive in the testing pyramid. Unfortunately, in the traditional waterfall approach, the pyramid is sometimes inverted, with a small number of unit tests and heavy manual testing at the other end (see Figure 1).
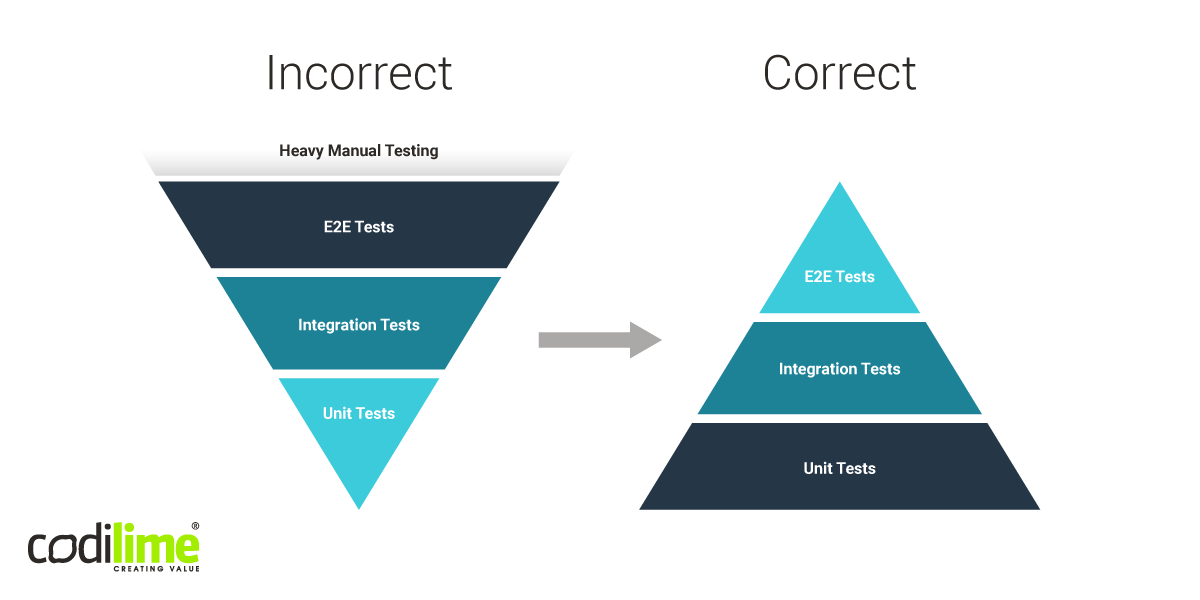
The testing pyramid should always be kept in its proper form as this will reduce testing costs considerably and allow you to detect most bugs at the low levels, where they are relatively easy to correct. It may also be necessary to enlarge the pyramid to include more tests like on Figure 2.
Follow the “green light” approach while executing your tests
Automated tests can fail. Unfortunately, despite the appearance of a “red light”, the process can also be pushed further and failed tests are simply ignored and sometimes even removed without being analyzed properly. This will lead to errors in the testing pipeline, but just where they occurred will not be clear. A test may fail due to an error made at some previous stage, but which one? To avoid having to ask this question, use the “green light” approach: always fix failing tests. It is important to have only those tests that produce correct results. Flaky tests that produce different results in different launches or run for different periods of time should be immediately corrected, which is not always easy to do. Otherwise, it is impossible to establish proper QA. Moreover, errors skipped at the testing phase may lead to serious problems when software has already been deployed into production.
Don’t use Thread.sleep() if it is not explicitly required
QA engineers or developers often tend to use the command Thread.sleep() when they want to pause the test execution for a given time. This may be because a component in SUT is loading slowly and it is necessary to wait until the data to be tested are in place. Sometimes we even add sleep while debugging. Such a practice does no good, as it extends the testing time unnecessarily. At the same time, people tend to forget about Thread.sleep() commands introduced here and there in the test code and, as a result, it takes longer and longer to execute a testing pipeline. In this case it is definitely better to use other tools or methods, such as the wait-for-element method. Once they are available, the test is launched.
Always use simple element locators in UI/GUI testing
Remember to use element locators in your SUT that are easy for users to understand and find. For example, use ID or names that are unique values, but do not use a long xpath that may be illegible. Moreover, even if there is no unique ID, you can always ask developers to add one that will identify the exact element. This will help not only in communication if defects occur, but also with debugging both tests and SUT.
Use easy-to-understand test names
It may seem obvious that the test names you choose should be easy to understand, but this simple rule is too often neglected. Remember to name tests to match the testing scenarios they are to execute. Not only will this make your life as a QA engineer easier, but also help other QA specialists and developers understand what a given test checks and in which SUT component. Additionally, each test case should have a unique ID allowing for proper identification. This will greatly simplify debugging and bug classification.
Use test design patterns and shared libraries
The golden rule of DRY (“Don’t repeat yourself”) is often cited by programmers, and should be by testers as well. Code duplication will for sure make your life harder. When there are corrections or changes to be made, due to a change in requirements, for example, you will have to implement them in many places. Also, do not hardcode too much data into the test code itself. It will only lead to time-consuming corrections later when, for example, your SUT changes. So, whenever it is possible, use test design patterns such as Page Object Model to reduce code duplication and make test maintenance easier and less time-consuming. Lastly, store your common data in shared libraries to avoid confusion and unnecessary data migration at the production stage.
Collect as much data about failed tests as possible
Do your best to gather every piece of evidence that will help to fix bugs. Screenshots and screencasts for failed tests are a good example here. Adding them do the test logs will definitely make your life easier when you investigate a possible cause of a test failure and try to fix it. The same is true for logs coming from different components of the SUT. All this data should be used to automatically create issues in issue tracking software.
Generate reports from tests
Finally, the reports you generate will tell you if your testing has succeeded. These reports will be read not only by QA engineers and developers, but also other stakeholders (including project managers, and higher management) who may want to check a product’s status. It is important to log all the data related to the SUT as well as to the testing framework itself. You should log every single element or module in SUT and its status during the logging. Finally, system data should also be included in the final test report.


