


Have you ever wondered how to set up a test automation framework directly in the cloud? Well, in this blog post you will learn about everything you’ll need to successfully create such a framework. We’re going to look at the pros and cons of preconfigured testing environments and those that are created dynamically. We’ll then show you how to include software testing in a CI/CD pipeline and achieve high level automation. Finally, we’ll break down what a message broker is and how it can be used when creating a testing architecture. Enjoy your reading!
Test automation framework—requirements
To begin with, you should define the requirements your testing framework should meet. You should also ensure that it’s independent of a cloud provider (to avoid vendor lock-in) as well as the Operating System (OS) to allow better portability. Secondly, you should be able to run it not only locally, from your machine or server, but also from the Continuous Integration System. Moreover, the framework should be easy to use for developers, QA engineers as well as for managers who may wish to check if everything works as intended. Last but not least, it should be easy to maintain and expand, as well as to scale according to current needs. While these requirements may be difficult to meet, bear them in mind during the design stage of the testing framework.
Once you have met these requirements for the testing framework, you’ll need to answer this fundamental question: should I use a preconfigured testing environment or a dynamically created environment just before testing itself begins. To solve this dilemma, let’s have a look at the benefits and drawbacks of each.


Preconfigured testing environment—one solution does not fit all
The first approach is to have a test environment that is already preconfigured and accessible for all teams. Good practices should be maintained by a team set up for the purpose. The environment can also have pre-installed prerequisite systems and a database (with test data). Thus QA teams can start testing right away without spending time manually configuring a testing environment. When testing the environment, System Under Test (SUT) and testing framework are already running, so it is easy to load a test plan and perform all the planned tests one by one and get results. Crucially, you don’t have to launch a testing environment and wait until it is up and running to perform tests. Such a scenario can be used when, for whatever reasons, testing time is limited and the testing process should be jump-started as quickly as possible.
On the other hand, preconfigured environments have serious drawbacks. Since such an environment is used by many users, the probability of human error is higher. If somebody commits such an error, it may be impossible to continue using the environment. In order to correct this error, it may be necessary to consult with somebody who has enough expertise to solve it. It goes without saying that that may be problematic, especially when testing time is limited.
Secondly, it is difficult to run parallel tests in preconfigured environments. If you need to run several tests parallely, you must create a second instance of this environment, which, in turn, requires time, money and skilled personnel to deliver such a service. Moreover, it is difficult to modify such a preconfigured environment. If you want to introduce a modification, you must inform other users about it, then the system has to be made unavailable for use until the modification is merged. After a successful merge, other users must be informed that the system is now free to use. Apart from that, you have to know such a system very well in order to introduce modifications into it.
Moving forward, it is difficult to isolate such a preconfigured environment when performing tests due to the lack of component modularization. You do not have any control over the way the system is built—you are working with a ready-made product. Another serious drawback is that the system must be cleaned after the testing is done. If that is not done properly, such a system may not work at all. The worst case scenario is that changes in the environment can cause test ‘flakiness’. These differences may be so small that you will not spot them and will deliver false test results. Finally, there is the issue of scalability. Preconfigured environments are difficult to scale when you need to do parallel testing or expand the environment itself.
The case for using a dynamically created environment
On the other hand, there are environments that are created dynamically, and the advantages they offer are significant. First of all, you don’t have to clean the system after the testing is done. Since everything is created from scratch and simply killed after the testing is done, you don’t have to remember to kill running processes or close containers. When the system is launched for the second time, it is clean and fresh with no data remaining from previous tests. Of course, in the long run you should still take care of your system by cleaning it periodically, as not doing so may lead to a system failure. Still, such maintenance is not as demanding as in preconfigured environments. Secondly, there is no job queueing. With preconfigured environments used by many users at the same time, tests are queued until they can be performed. Use a dynamically created environment, though, and you can do your test plan whenever you want—and obtain the results immediately. It is also worth emphasizing here that it is easy to isolate a testing environment and the modules that are being tested. Additionally, containerization brings costs down. Cloud solutions allow us to simplify the entire process of creating an environment and reducing the time needed to get such an environment up and running. It is also easy to run parallel tests. To perform them, you just have to launch numerous testing instances or dedicated servers or controllers that will launch the instances needed. Finally, a dynamically created environment usually has very good documentation where everybody can check how it should be launched and how it works. This applies both to the entire system and single components, which can be launched and tested in isolation.
Of course, dynamically created environments also have their drawbacks. Foremost among them is that creating and maintaining such a system is expensive. Since there is a CI system that is up and running and every QA engineer can launch a testing environment at will, numerous machines are created and run for a considerable period of time. This requires more computing resources and generates constant maintenance costs. It is also expensive to develop such a dynamic environment, as doing so requires both time and expertise.
Financial costs aside, using a dynamically created testing environment means you’ll need to have advanced programming skills and know more tools than when using a pre-configured environment, where there is usually just a single set of tools. Finally, full automation of large testing environments is not always profitable. When that is the path you have chosen, there will be two possible scenarios to follow. The first is to mix static and automatic configuration where the hardware is setup manually, while services are configured automatically. The second scenario consists in implementing the stages of automation that are executed only when certain conditions are met or changes are rolled back by code automation.
Despite these shortcomings, advantages such as the possibility of isolation, parallel testing or containerization make a dynamically created environment a really good choice.
Testing architecture—an example
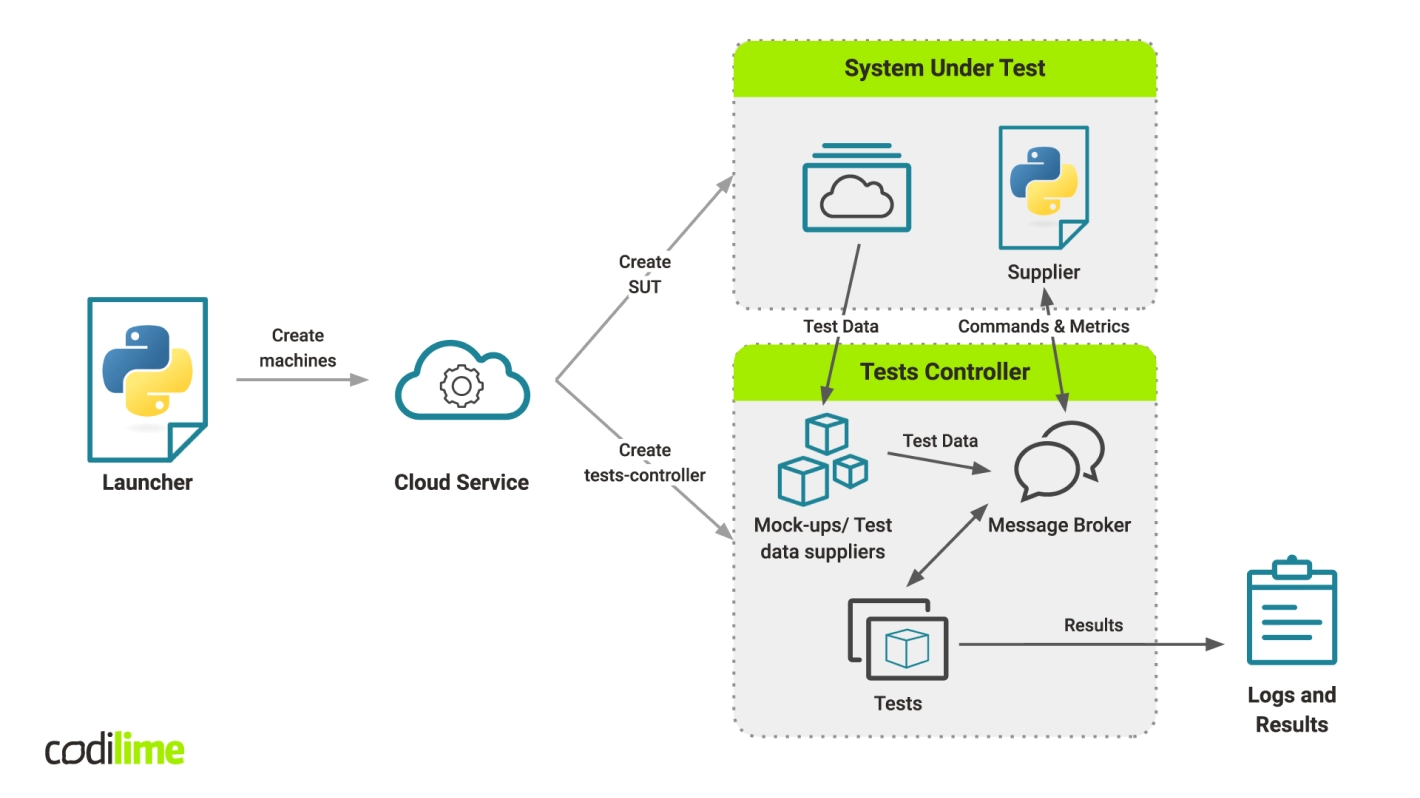
Using everything I’ve established about dynamically created environments, I’d now like to create an example testing architecture. First of all, we have a script or a group of scripts. From the point of view of unified testing methodology, working both locally and in a CI system, it is better to have fewer scripts as managing them is easier. Use a cloud service (e.g. Google Cloud Engine or AWS) to create the System Under Test (SUT). It may be a single machine or many machines communicating with each other—everything depends on the solution being tested. Then, create a test controller—on the same machine from which tests are launched, if it suits you. If you choose this path, though, know that such a machine may have some impact on future tests. So it is better to use separate machines, as it is easy to simply kill them or check what caused the problem when errors inevitably creep in. It is also good to launch an additional script on the SUT, e.g. checking system performance. Additionally, if the systems aggregate any other kind of data, use this script to log and check them during testing.
Of course, apart from SUT there is also the test controller. Its containers can be either grouped by docker-compose or you can use Python SDK to create a virtual network. There will be a container containing only tests, simple ones that compare the expected results with those generated during the tests.
There is also a message broker (e.g. RabbitMQ, Apache Kafka, etc.) which is only rarely used in testing. It allows us to group data to be tested. For example, when doing initial smoke tests to check if processes in the system are up and running, we will have all the information about that under the appropriate routing key. So, when such information is needed, on the test site it is enough to connect to this routing key and download the necessary information. This can also be done with other types of data.
This solution offers considerable advantages. If we separate the system elements responsible for generating data, their logging and sending from the tests, the probability of human error falls considerably. When such separation is lacking, an error may cause the failure of the whole container together with the tests. If such a separation exists and each module is tested separately, we will receive the report from tests containing information about the modules that have been tested. If some of these modules are not working, we will still have a report showing other tests that were passed. We need only determine what went wrong and fix it. If such a separation is lacking, or should something go wrong, all the tests will need to be checked one by one. Obviously, this is very time-consuming and costly.
At the end of the testing process, we have logs and results which need to be stored somewhere. The location where they are stored should be different from the system. A cloud provider is a good place as everyone has access should problems crop up. Going the cloud route also saves time, especially when the DevOps and QA teams are located in different time zones. A message broker can also be used to control which data should be reported. For example, it can be used to send a message to a data supplier to start reporting CPU or RAM usage. Our sample testing architecture is shown in Figure 1 below.
Testing in the CI pipeline
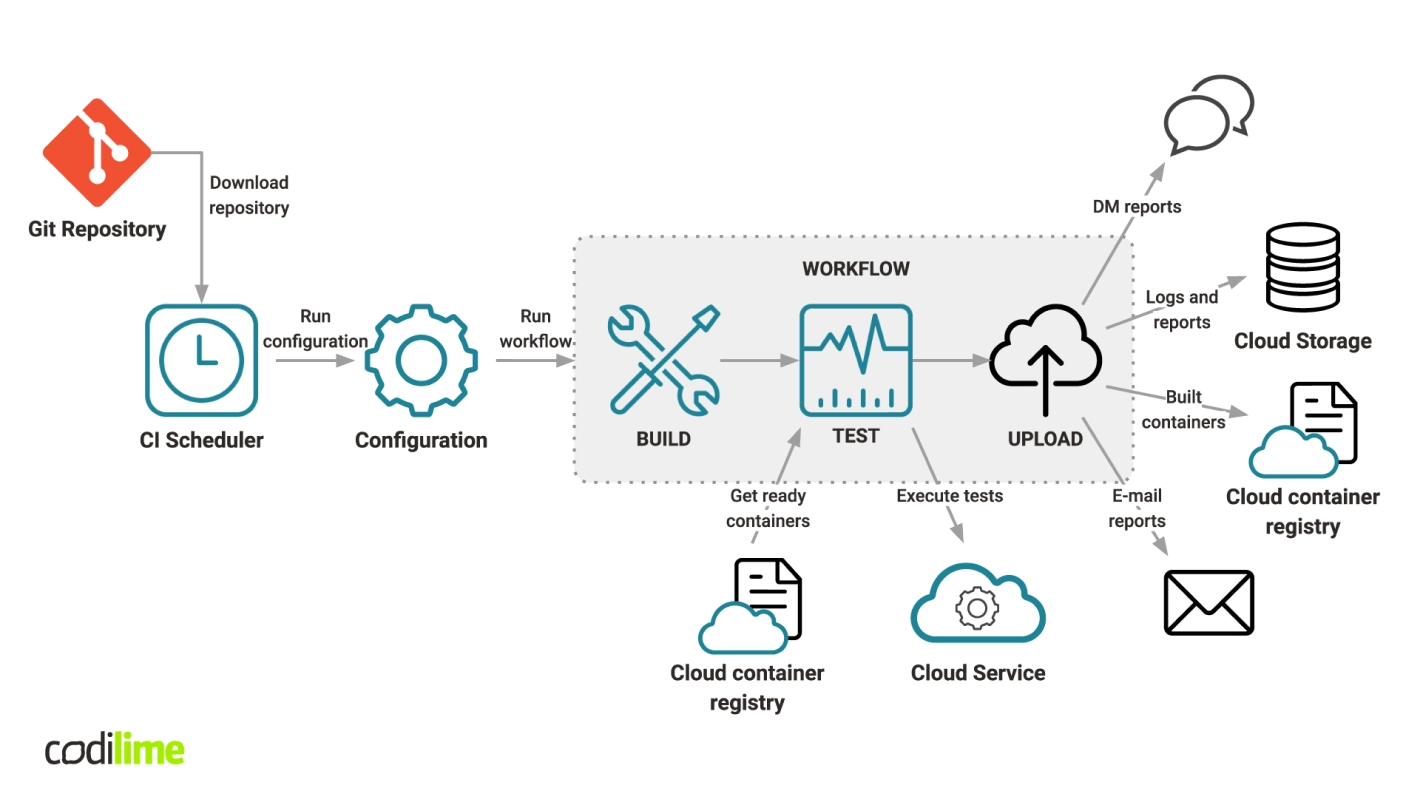
This brings me, finally, to tests in the CI systems. There is always a CI scheduler (e.g. Jenkins, Bamboo, CircleCI, GitLab). An appropriate configuration is loaded from GIT repository, run, and the entire process begins. First, the components to be tested are built and the tests performed. It is important to use ready containers, e.g. ones taken from Google Container Registry. At first it may be a few of them, but the more SUT modules that are tested, the more containers will be created. Building them from scratch takes a lot of time, while using pre-created ones can cut down the time required by up to 30%.
After the tests are done, the results are generated and sent. We can use an automatic notification solution such as Slack plugin to say whether or not the tests were successful. The simplest solution, of course, is to shoot off an e-mail, but I don’t recommend doing that, since there will be many such e-mails and it’s hard to keep on top of them all. It is better to store test results in cloud storage with appropriate tags and reference numbers, so that they’re easily traceable later on. Our containers are stored in a service for container storage, so that they can be reused when performing a new test process. The CI/CD pipeline with the testing phase included is shown in Figure 2.
-> Want to learn more about CI/CD? Check out our other articles:
- What is CI/CD - all you need to know
- How to set up and optimize a CI/CD pipeline
- Best CI/CD pipeline tools you should know
- Continuous monitoring and observability in CI/CD
- CI/CD process—how to handle it
- Business benefits of CI/CD
- Sharing configuration between your CI, build and development environments
Cloud testing framework—how much does it cost
One crucial factor here is cost. Any testing solution in the cloud will use cloud computing resources, which can pile up when the SUT is complicated and requires many types of tests. Therefore, before embarking on building a cloud testing framework, it is wise to perform basic calculations to see if the numbers work for you. Ultimately, perhaps there will be a cloud solution comparably priced or cheaper than a similar on-prem solution. The cost calculation should include the numbers of VMs needed. Their cost can be up to 30% lower when more machines are used (thanks to the so-called Sustained Usage Discount). Another factor is the time needed to perform all of the tests. Finally, there are also cloud storage costs, as a place to store testing logs is needed. If we choose to use Google Compute Engine, the sample calculation may look as follows:
number of pull requests * number of machines * test time (h) * cost per hour
Let’s assume that in one month there are 50 open pull requests. For each of them, a single CI process is run in which two virtual machines are created. One pull request takes circa 12 minutes and an average cost per hour is $7. The calculation is as follows:
50 * 2 * 0.2 * $7 = $140 monthly
Of course, we should also include storage costs. For Google Cloud Storage it would be $0.026/GB/month plus egress $0.12/GB/month. Please note that these are the costs of a testing environment that is created dynamically, i.e. it generates costs only when it is in use. In other words, automation helps keep costs down.
Software testing framework in the cloud - why it’s worth using
I hope that I have convinced you that creating your own test automation framework directly in the cloud is worth it, and superior to pre-configured, ready-to-use environments. The initial investment of your time and labor will pay important dividends in the future, when proper software testing begins. Moreover, a message broker can be a slick way to gain full control over the testing process. Ultimately, all testing should constitute an integral part of a CI/CD pipeline and should be started at the very beginning of a software project.


