


Here’s a question that gives telco operators sleepless nights: How do you go about building and maintaining your telco cloud to maintain carrier-grade requirements while bringing hyper-scale public cloud pronouncements and promises to the telco world?
One of the main challenges to achieving the above is to provide network monitoring, alerting and troubleshooting.
Monitoring such complex infrastructure is not only about monitoring the physical health of the hardware the services rely on. It must also extend to the state of VMs or containers serving either control plane functions or a that runs a specific network function. Moreover, when you add network protocols running on top of that function, allowing underlay and overlay networks to coexist and even cooperate, you get a very complex system to monitor.
Well-recognized troubleshooting provides a solid foundation for successful monitoring.
Introduction to network monitoring and troubleshooting during the VNF lifecycle
Virtual Network Functions are monitored periodically to check their health and workload.
During a VNF health check you should focus on monitoring factors including VM aliveness, VM variables for Disk usage, Memory, CPU, Network throughput and ICMP messages on the VM interfaces. The VNF health check should also include the monitoring of VNF network traffic.
We've previously talked about Linux network troubleshooting specifically, the issue we’ll be focusing on today is: Monitoring and troubleshooting VNF network traffic managed by Software Defined Networking components.
VNF network traffic managed by Software Defined Networking components
There are a variety of SDN solutions available on the market. They all use different approaches to implementing network traffic delivery across VMs, and between VMs and the external resources. To name only a couple:
- Open vSwitch - uses bridge forwarding principles and multiple flow tables containing data to match packets and appropriate actions to be performed once a match occurs (a flow is a set of packets sharing common properties such as: source & destination addresses and ports, and it’s a part of the same communication between two application endpoints).
- Tungsten Fabric - establishes communication between distant sites using well-known MPLS VPN (Multiprotocol Label Switching) concepts, making TF ready to be plugged into the provider MPLS network directly. It uses a flow concept to classify packets and take appropriate actions once a match occurs.
Regardless of the type of SDN solution used, packet flow matching plays a crucial role in traffic processing. Therefore, great care must be taken to properly configure and monitor the flow tables resource. This is especially true with Tungsten Fabric, as incorrect flow table configuration coupled with not fully a cloud-compatible VNF may lead to severe traffic disruptions.
We will revisit these problems and look at some possible solutions later in this article.

How are flows processed?
We know that flows play a crucial role in traffic processing. To understand why that is we can take a closer look at Tungsten Fabric.
Tungsten Fabric uses hash table techniques to implement efficient flow processing ![]() within the vrouter. Each hash table
within the vrouter. Each hash table ![]() entry points to a bucket containing 4 flows. In different implementations of the vrouter made by hardware vendors (DPDK offload for instance) the number of flows per bucket may vary, leading to different hash collision ratios (for details see slide 10
entry points to a bucket containing 4 flows. In different implementations of the vrouter made by hardware vendors (DPDK offload for instance) the number of flows per bucket may vary, leading to different hash collision ratios (for details see slide 10 ![]() ). In the case of hash collision, the flow entry is programmed into the overflow table (which, as of Contrail 2.22, is a list against the hash bucket) and stays there until the flow is removed. If the number of flows in the overflow space grows significantly, the vrouter spends more time at the lookup routines and overall performance degrades. Tungsten Fabric 5.1 introduced Cuckoo, a hashing algorithm, to improve performance of the vrouter under heavy load.
). In the case of hash collision, the flow entry is programmed into the overflow table (which, as of Contrail 2.22, is a list against the hash bucket) and stays there until the flow is removed. If the number of flows in the overflow space grows significantly, the vrouter spends more time at the lookup routines and overall performance degrades. Tungsten Fabric 5.1 introduced Cuckoo, a hashing algorithm, to improve performance of the vrouter under heavy load.
Two recommendations about flow size and overflow table size should be considered:
- The flow table size should be 50% larger than the expected flow count on the hypervisor.
- The number of overflow entries must be at least 20% of the flow table size.
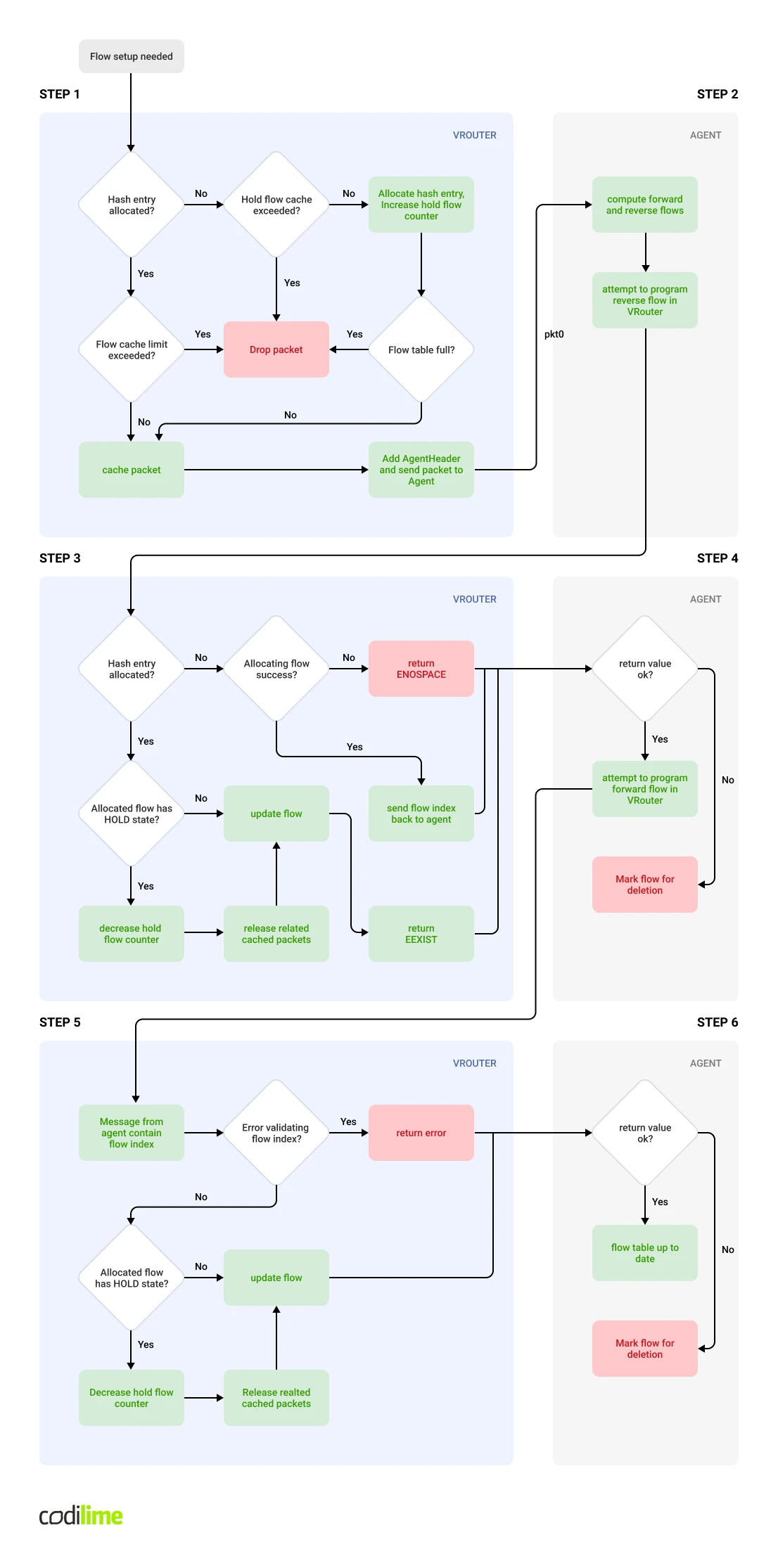
The following steps occur when the first packet(s) of a new flow enters the vrouter:
STEP 1: Inside the vRouter - the vRouter sends a request for flow setup to the vRouter-agent
Initially the vrouter decides that it needs to set up a new flow. In most cases this happens when it processes a new connection (TCP handshake is a good example). The new flow may jump into the place of an existing evicted flow – in this case the flow entry will be reused (and modified accordingly) otherwise a new flow entry must be created. The new flow will be associated with a HOLD Action. There are several steps that might go wrong here and cause the packet to be dropped:
- The flow packet cache may be full
- The limit of flows in a hold state may be exceeded
- The flow table may be full
If none of these occur, the vRouter encapsulates the packet with a proprietary agent header and transmits the packet towards the vRouter Agent using pkt0 interface.
STEP 2: Inside the vRouter Agent - the vRouter Agent computes forward and reverse flows
Upon receiving a packet the vRouter sent during the previous step, the vRouter Agent will start processing the packet to compute all the properties of two flows – forward flow and reverse flow. During computation, Agent software will take into consideration various aspects of VNF deployment configuration – such as floating IP, ECMP, Security Groups, interfaces, virtual networks. Once computation is complete, the Agent daemon will attempt to program both flows within the data plane. It will begin with the reverse flow.
STEP 3: Inside the vRouter - setting up a computed reverse flow in a vRouter
This step is executed within the vrouter after receiving a reverse-flow allocation request from the Agent. The vRouter will attempt to allocate a reverse flow (by setting up a new flow or recycling an existing one that is no longer in use) or, if one already exists in a hold state, release cached packets and decrease the hold limit count. At this time, the flow being processed is updated with the desired parameters. The result of the operation is reported back to the Agent.
STEP 4: Inside the vRouter Agent: Schedule setup of the forward flow
Depending on the result of reverse-flow setup, the Agent will mark forward and reverse flows to be deleted, or it will request the vrouter to process the forward flow.
STEP 5: Inside the vRouter: Setting up a forward flow in the vRouter
This step is executed within the vrouter after receiving a forward-flow update request. At this point, forward flow should already exist and have a known index. If not, an error is returned. Otherwise, cached packets are released, the number of flows in the HOLD state is decreased and the flow is updated with the requested parameters.
STEP 6: Inside the vRouter Agent - Error handling
This step takes place within the Agent. The result of the previous step is validated and if an error state is detected both flows are marked for deletion. If no errors are reported, the flow is considered to be successfully programmed and the algorithm ends.
One of the very important flow states in the above procedure is the HOLD state of the flow - that is, when action associated with a given flow is set to HOLD. The number of flows allowed in the HOLD state is a shared resource at the level of the vrouter Agent process and, as such, is valid for the entire vrouter (hypervisor). If the limit is reached, new flow setups (both forward and reverse) will fail instantly. In practice this means that regardless of the tenant, none of the VMs present within the impacted hypervisor will be able to establish new network connections and the vrouter will drop the corresponding packets. At the same time, the flow unusable counter within dropstats will increment. VM traffic using already existing flows will be forwarded without any issues.
Common flow-related problems from real life:
-
Flow table extinction
- A highly-utilized flow table generates more overflow entries and decreases vrouter performance.
- With flow and overflow tables full, new flows can’t be created. This means problems with establishing new communication sessions.
- The flow table full counter increments when there is no space for new flow.
-
HOLD flow table limit reached
- New flows cannot be created and new communication is blocked.
- Impacts all VMs on hypervisor regardless of tenant.
- May look like random connectivity loss on hypervisor and create confusion in the troubleshooting process (suspicion of CRC errors within underlay network interfaces, for instance).
-
Application generates flows too quickly
- Some VNFs may attempt to initiate thousands of connections at the same time (for instance during site to site switchover). This will cause the vrouter Agent to reach the hold flow limit almost immediately.
- Unfortunately, this is an example of VNF-infrastructure/telco cloud incompatibility and little can be done about it beyond protecting other workloads from this particular VNF. A possible workaround involves increasing the limit for the hold flows. However, too aggressive hold flow threshold values could cause performance problems on the compute node due to too many flow setup events taking place at the same time. Bear in mind that compute node resources are shared between vRouter and deployed workload (like VNF, Apps). So it is crucial to find an optimal state in between the VNF requirements, compute resources available for workload and forwarding performance.
-
Packet buffer full
- It may happen that under heavy load, the flow setup becomes too slow, causing the vrouter to cache more packets. At some point, the flow cache limit will be reached and the vrouter will begin dropping packets.
What Tungsten Fabric features help you deal with flow-related issues
Some properties of the flow tables can be modified on the fly, while others require vrouter kernel module reload, causing service disrupting operation. The most significant vrouter kernel module parameters ![]() from a flow table perspective are vr_flow_entries and vr_oflow_entries. These configure flow table size and overflow table size, respectively. Both parameters need to be chosen with care, because too small flow tables will cause performance issues, while too large ones will cause unnecessary memory resource consumption.
from a flow table perspective are vr_flow_entries and vr_oflow_entries. These configure flow table size and overflow table size, respectively. Both parameters need to be chosen with care, because too small flow tables will cause performance issues, while too large ones will cause unnecessary memory resource consumption.
Depending on the Tungsten Fabric version, the allocated flow memory structure is aligned up to 128B ![]() or 256B
or 256B ![]() .
.
On the other hand, the number of allowed flows in a HOLD state may be configured without any service disruption using the vrouter utility. This is because such flows are stored in the same way as ACTIVE flows (“HOLD” or “ACTIVE” state are two of many flow attributes) and therefore no table allocations need to be done when this value is altered.
root@test:~# vrouter --flow_hold_limit 1024
root@test:~# vrouter --info
[...]
Runtime parameters
[...]
Other settings
NIC cksum offload for outer UDP hdr 0
Flow hold limit: 1024
[...]
There are several ways to deal with the traffic load that pushes flow table resources to the limit.
- If the hypervisor hardware being used has some spare memory resources, the flow table size can be increased. With decent versions of Tungsten Fabric, a flow table for 4M flows should consume around 1GB of memory (according to documentation, this is the largest flow table size tested).
- The limit for the number of flows in the HOLD state can also be increased. The main purpose of this limit is to protect the agent from being flooded by flow setup requests and thus from high CPU load. However, if the hardware being used is powerful enough, it should be able to handle a higher flow setup rate.
- A possible strategy for keeping the amount of flows in the HOLD state below the limit is to configure the vrouter agent with a per-VM flow limit. This parameter is given as a percent of the total system flow limit, which is the sum of the flow and overflow table sizes. This configured limit should be lower than the maximum amount of permitted flows in the HOLD state. Such configuration will ensure that a single VM will not be able to saturate the HOLD flow pool on its own. Such a VM will probably suffer from connectivity issues (as it will not be able to open the desired number of connections) but other VMs will not be impacted (they would be otherwise).
The per-VM flow limit is configured in the vrouter agent configuration file, contrail-vrouter-agent.conf ![]() :
:
# Maximum flows allowed per VM (given as % of maximum system flows)
# max_vm_flows=
-
Flow aging - an obvious strategy to keep the number of flows as small as possible is to remove them as soon as they are no longer needed. There are several flow-aging strategies implemented in Contrail:
- Aging on flow inactivity - by default, flows are timed out after 180 seconds of inactivity. This value may be altered by modifying the flow_cache_timeout setting under the DEFAULT section in the contrail-vrouter-agent.conf file.
- Aging stateful TCP flows - The Tungsten Fabric vrouter keeps track of the TCP session lifecycle to be able to identify flows that can be ended earlier than after 180 seconds of inactivity. In particular, the vrouter looks for packets initiating the TCP session start containing SYN flags and packets indicating TCP session tear-down - that is, containing FIN or RST flags. Data about the flow TCP state is exported to the vrouter agent, so it may keep track of broken TCP sessions - for instance, those not fully established.
- Protocol-based flow aging. There can be services running inside a VM that do not rely on TCP transmission and require a small number of packets to be exchanged with the client in order to fulfill the request. The DNS service is a good example (a single packet with query and a single packet response). In such a case, each execution will set up two flows, each of them lasting for 180 seconds by default. This issue can be addressed by configuring protocol-based flow aging; that is, aging is configured for a specific protocol/port while default aging for other traffic remains valid.
-
Packet mode
 is a feature configured at the virtual machine interface (VMI) level. When configured, no flows are created for traffic originating from and to the VMI. Such an alternative for the flow processing has both advantages and drawbacks.
is a feature configured at the virtual machine interface (VMI) level. When configured, no flows are created for traffic originating from and to the VMI. Such an alternative for the flow processing has both advantages and drawbacks.Advantages:
- Can be set up at the VMI granularity
- Decreases the probability of vrouter flow table depletion (and connectivity issues for all VMs on affected hypervisor) level as the number of flows (ACTIVE and HOLD) is reduced
- Higher vrouter performance (flow setup not executed for a given VMI)
Disadvantages:
- Connectivity troubleshooting becomes harder
- Security groups aren’t supported
- Limited network policy functionality (only route leaking is available)
- The floating IP doesn’t work
- No RPF
The main drawback of using packet mode forwarding is the lack of certain traffic processing features that are available in Tungsten Fabric. However, these functions aren’t always required by the VNF and in such scenarios packet mode may be a good alternative.
-
Fat flow
is based on the concept of aggregating multiple traffic sessions sharing some common properties into a pair of flows in a vrouter flow table. This feature was first introduced in Contrail 2.22 and, following new versions of Contrail and Tungsten Fabric, supported additional matching features to allow better alignment with application specifics.-
The following fat flow matching functionality is available:
- A fat flow feature was added in Contrail version 2.22. Initially it was allowed to configure flow aggregation for a Virtual Machine Interface using a protocol and the port number of the service. The client port number is not taken into account when the hash is being computed.
- Starting with Tungsten Fabric release 5.0 , the fat flow feature may be additionally configured at the Virtual Network (VN) level . In such cases it will be applied to all VMIs belonging to that VN. This version also allows more flexibility in matching flows, as the user can aggregate flows by ignoring source and destination ports and/or IP addresses in any combination.
- Tungsten Fabric 5.1 allows fat flows to be defined with IP prefixes by implementing mask processing for defined addresses.
- A fat flow feature was added in Contrail version 2.22.
-

Issues and possible actions
The following is a one-page manual with common issues and measures for resolving them.
Flow table extinction
Impact:
- Performance drop - more hash collisions as the main flow table is utilized more and, as a consequence, the overflow table becomes busier (searching the overflow table is far more demanding of CPU the resource).
- If the flow table is full, then flow is marked as short-flow (to be deleted). This means that any new communication (being established) is likely to be immediately dropped.
How to minimize the effect:
- Depending on the traffic type (but especially for stateless traffic) a good practice would be to adjust flow aging timers, so flows are deleted after a shorter period of inactivity. The stateful traffic-TCP flows will be deleted automatically because the TCP session state is being tracked by the vRouter Agent.
- Increase the size of the flow and overflow tables (this may be a reason for considerable increase of memory requirements).
- If the cause of the problem is a single VM (or a small group of VMs) it may be beneficial to configure the per-VM flow count limit.
- Configure fat flows, so similar types of flows may be bundled within the same flow entry. This type of configuration must take into account the specifics of the VNF to make sure that fat-flow configuration will not affect the operation of the virtual network function.
- If applicable, configure packet mode on VMIs belonging to the biggest flow consumers.
“Hold flow table” extinction
Impact:
- Communication disruption - most new flows cannot be established for any VM that uses a given hypervisor.
How to minimize the effect:
- Attempt to locate VMs that contribute most of the new flows and check if it is possible to reconfigure the application to decrease the rate of new flows/s.
- Increase the hold flow count limit.
- Configure a per-VM flow limit that is smaller than the hold flow count limit. While this will not solve problems with a particular VM generating a high rate of new flows, it will allow other VMs to resume normal operation.
- If applicable, configure the packet mode on VMIs belonging to the biggest flow consumers.
The challenge
With an improper vrouter configuration some very demanding (or improperly implemented) VNF deployments sending huge amounts of flows may effectively put user applications in a DoS (Denial of Service) state. This blogpost has presented some countermeasures that allow us to continue operating properly under such conditions even if we cannot influence the way the application is operating internally. All of these techniques are intended to reduce the usage of flow table space inside the vrouter and to handle the rate at which new flows are being set up. It also explains what costs and constraints, if any, those techniques introduce.
If you found this article interesting and would like to get to know more practical aspects of flows in SDN, we can help you with that! In our next blogpost we will guide you through a real-life implementation of flows monitoring and troubleshooting during the Virtual Network Function lifecycle based on a combination of data gathered from SDN (Tungsten Fabric) and OpenStack. We will also present how to build automated scripts for detecting the biggest troublemakers among all Virtual Machines/OpenStack projects/VNFs. Read a real use case example of network troubleshooting during the VNF lifecycle.



