


When we first started, we were given two things to do: resolve issues with builds getting gradually slower and set up a completely new system that Tungsten Fabric could use.
Over the years, Tungsten Fabric has received commits from more than 500 contributors and the code is scattered across over 50 repositories. The entire project consists of over 2 million lines of code, written mostly in C++ and Python.
In the beginning of the project few major tasks emerged:
- prepare the CI for the increased involvement of the community;
- decrease build and test times;
- ensure the system is highly scalable.


Recon
The existing system consisted of three major components - Gerrit ![]() , Zuul
, Zuul ![]() and Jenkins
and Jenkins ![]() . Gerrit took care of all the code and contributions. Zuul acted as Jenkins’ job scheduler and Jenkins was simply executing jobs on its workers. During the release time, there were over 40 different reviews being tested at the same time, sometimes stretching to multiple VMs to test Tungsten’s high availability capabilities.
. Gerrit took care of all the code and contributions. Zuul acted as Jenkins’ job scheduler and Jenkins was simply executing jobs on its workers. During the release time, there were over 40 different reviews being tested at the same time, sometimes stretching to multiple VMs to test Tungsten’s high availability capabilities.
Pain points
After a number of conversations with the CI team, project developers and a deep dive into the code (assisted by a few gallons of coffee), we’ve managed to identify problems to avoid and solve in the new system.
Third party packages
Building Tungsten Fabric requires a lot of third party dependencies. Originally, they were sourced from the official repositories (e.g. archive.ubuntu.com ![]() ). However, to ensure the product was stable, we needed to mirror and cache the upstream packages.
). However, to ensure the product was stable, we needed to mirror and cache the upstream packages.
Mirrors and caches can prove difficult to maintain, but they’re worth it - they allow you to have better control over the dependencies and significantly speed up the building process as you no longer need to get your dependency packages from the Internet; they’re local now.
Configuration management system
As the project was growing rapidly, the CI system needed to be changed even faster to be able to adapt to the growth. And as the project was growing, maintenance and the existing configuration management system suddenly became an obstacle in delivering changes to the CI as fast as the product required.
And so the Configuration Management System became disabled, making the CI system just a bunch of manually managed snowflakes that eventually started increasing the time needed to keep it alive and working, instead of reducing it as intended.
Rebuilding packages
For every single operating system/OpenStack version combination, the whole pipeline was being run again from the very beginning. This meant that for every CI run, all Tungsten packages were being built multiple times across different jobs. The result was exactly the same, as the packages were built from the same code.
Additionally, the lack of building process parallelization extended the time of the run. The whole process took about 6 hours for a single build target.
Scalability and housekeeping
The existing Jenkins instance already had over a hundred static worker nodes and was reaching its limits. It was becoming unreliable and difficult to manage. Adding more workers became simply impossible.
Because of the product’s nature, there was a need for multiple different operating systems on the machines. Unfortunately, their images were managed manually, which caused additional overhead for the CI operators.
What’s more, because all worker nodes were static and had different operating systems, all of the machines had to be balanced manually. Whenever more Ubuntu machines were needed, someone had to do it by hand.
Here’s Johnny
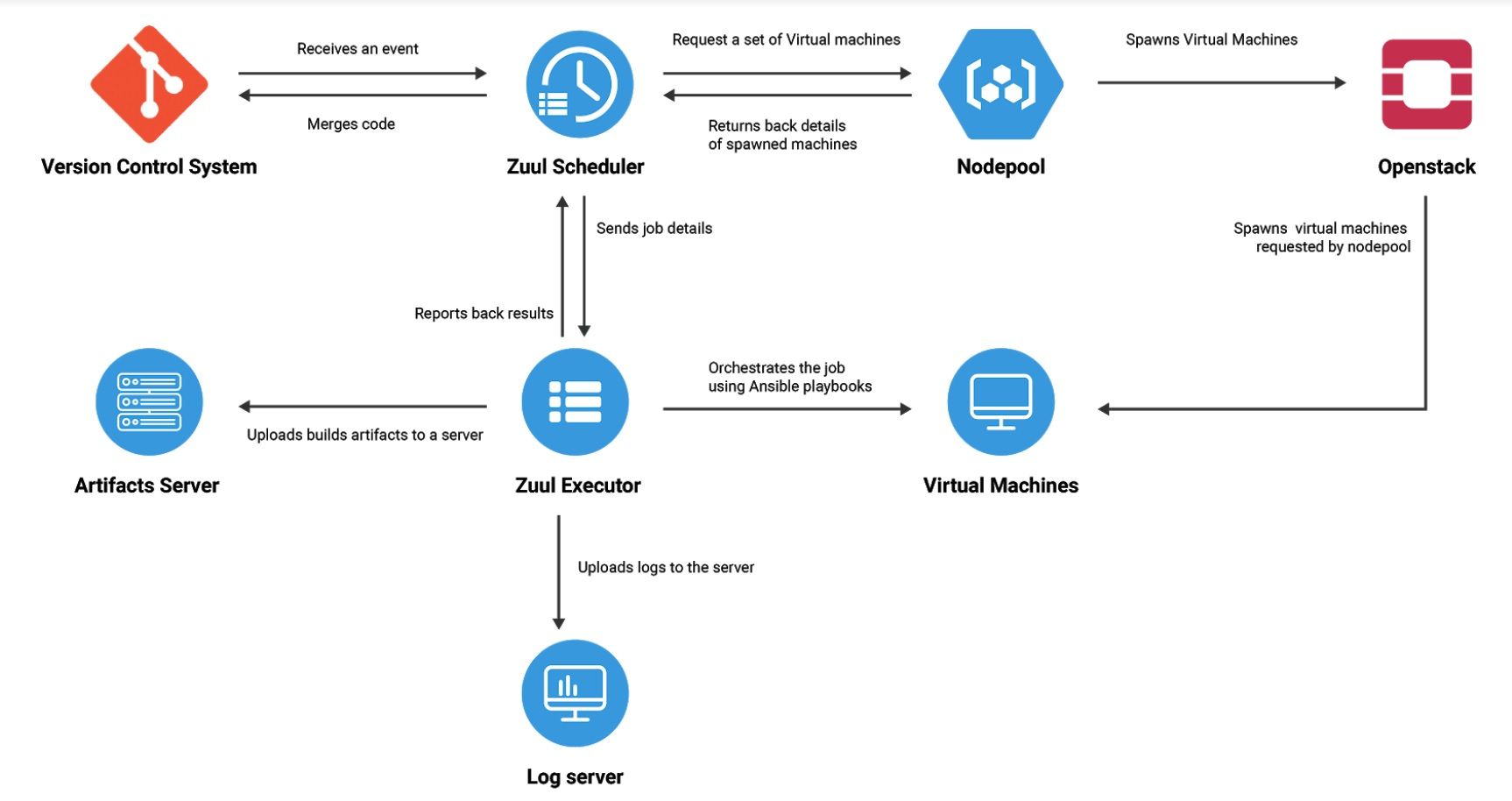
From the beginning we were interested in using Zuul as the main driver of the new CI system. Not only was it already known by the developers and used by the previous system, but it was also proven to work well at the scale OpenStack requires. Around the time we were starting, OpenStack was in preparation to migrate its CI system to the newest Zuul version, 3.0.
Why we love Zuul
Compared to its previous version, Zuul v3 brings a lot of fresh ideas and solutions forged by the almost extreme needs of OpenStack. Numerous operating tasks have been automated, because Zuul’s main developers are the very same people who use it every day and know its problems inside and out.
It’s Ansible-driven
All of the work under the hood is being done by Ansible, one of today’s most popular tools. It allows us to craft our jobs with some flexibility - we often reuse our code for different test scenarios and it turns out well for us, as we try to keep the building blocks as small as possible.
You can have more
Job execution is no longer handled by Jenkins. Now, that task is taken care of by Zuul Executor. An independent service that connects back to its “brain” to fetch all necessary code and job information and run it on top of the workers using Ansible. One Zuul Executor can handle running multiple jobs scattered across multiple OpenStack clusters. However, if you want to scale your system even more, you can set up a few more Zuul Executors to start load-balancing the jobs between each other.
Automates mundane tasks no one wants to handle
Managing your workers and their images manually can prove difficult and tremendously time-consuming. Zuul automates them, allowing operators some breathing room, using two components - Disk Image Builder and Nodepool.
Disk Image Builder (DIB) handles the preparation of worker images, allowing you to stay up to date on your dependencies and run your jobs with the freshest upstream code. All of its configuration is stored in a git repository, ensuring the images are consistent and there are no snowflakes requiring manual intervention. Every 24 hours, DIB pulls the base operating system image from the upstream and installs the packages you have specified on top of it. After that, the image gets uploaded to all defined OpenStack clouds, and is then ready to be used by your worker nodes.
Nodepool is a clever approach to managing your worker pool. It looks for job requests raised by Zuul and spawns nodes (VMs) for the duration of the job, only to be torn down afterwards. It allows for better cluster utilization compared to static pool. And because worker pool is completely backed by OpenStack, expanding it simply means adding more hardware to the OpenStack cluster and setting some project quotas.
You can test the CI in the CI
Zuul provides you with the ability to test changes to the CI system before they actually run in production. Every CI change follows the same workflow as any change to the product’s code itself does - you open a review (pull request), the CI system runs its jobs, someone reviews it and, depending on the code-review and the CI result, the code is merged. Only after all of these steps are completed does the proposed change start to affect the production environment.
Focused on security
One of the aspects of running a CI system is handling your sensitive data - sometimes you need to upload build artifacts somewhere, but you don’t want the server credentials to leak out. The issue becomes thornier if the CI system, instead of being hidden behind the company’s firewall, is completely open and available publicly. Zuul has a solution for that.
Zuul allows you to encrypt your data (which is then stored as ‘secrets’) using asymmetrical encryption. Everyone can add new secrets to it, but only Zuul can read them. Zuul employs a set of access and job inheritance rules to prevent untrusted and newly added CI jobs from reading them. Only changes approved by core reviewers can access a secret’s content. Additionally, because everyone can add a secret to Zuul, the operator’s involvement is not necessary as the process is fully automated.
Aftermath
By completely reworking the CI system and jobs and the build system, we were able to knock hours from the build time. Reducing duplicated tasks allowed us to free up more resources for other jobs, which in turn has shortened the average time developers need to wait for the CI results. Builds that sometimes stretched to well over seven hours have been cut down to three hours or less. The unit test time has also been reduced by 20% on average, depending on the test suite.
Zuul v3 brings a lot of changes, one of them being dropping support for Jenkins workers. Tungsten Fabric has a heterogeneous environment requiring two operating systems families - Linux and Windows. We’ve managed to work around the issue, creating some sort of ‘hybrid CI system’ to use Jenkins and its workers through Zuul, which allows us to continue supporting both platforms.
The entire codebase of the CI system is open-source now and has no hidden dependencies, meaning anyone can clone it from GitHub or Gerrit, review it, propose changes or even deploy their own system based on that code. This approach, combined with the ability to test the CI changes before they are merged, enables both developers and CI operators to be equally responsible for the CI system and the jobs, bringing us closer to DevOps culture and lowering the barrier of entry for newcomers.
-> Want to learn more about CI/CD? Check out our other articles:
- What is CI/CD - all you need to know
- How to set up and optimize a CI/CD pipeline
- Continuous monitoring and observability in CI/CD
- CI/CD process—how to handle it
- Business benefits of CI/CD
- Sharing configuration between your CI, build and development environments
- How to build a test automation framework in the cloud


